1. Introducción
SparkContext es el principal punto de entrada del programa Spark y se utiliza para conectarse con el clúster Spark. Todas las operaciones del clúster Spark se realizan a través del SparkContext, que se puede usar para crear RDD, contadores y variables de difusión en el clúster Spark. Todos los programas de Spark deben crear un objeto SparkContext. El StreamingContext utilizado para la informática de transmisión y el SQLContext utilizado para la informática SQL también se asociarán con un SparkContext existente o crearán implícitamente un objeto SparkContext. El código fuente es el siguiente:
/ ** * Punto de entrada principal para la funcionalidad Spark. Un SparkContext representa la conexión a un
clúster Spark *, y se puede usar para crear RDD, acumuladores y variables de difusión en ese clúster. * * Solo un SparkContext puede estar activo por JVM. Debe `detener ()` el SparkContext activo antes * de crear uno nuevo. Esta limitación puede eventualmente ser eliminada; ver SPARK-2243 para más detalles. * * @param config un objeto Spark Config que describe la configuración de la aplicación. Cualquier configuración en * esta configuración anula las configuraciones predeterminadas, así como las propiedades del sistema. * / class SparkContext (config: SparkConf) extiende Logging { //El sitio de la llamada donde se construyó este SparkContext. private val creationSite: CallSite = Utils.getCallSite () // Si es verdadero, registre advertencias en lugar de lanzar excepciones cuando varios SparkContexts estén activos. private val allowMultipleContexts: Boolean = config.getBoolean ( " spark.driver.allowMultipleContexts " , false ) // En Para evitar que varios SparkContexts se activen al mismo tiempo, marque este // contexto como si hubiera comenzado la construcción. // NOTA: esto debe colocarse al comienzo del constructor SparkContext. SparkContext.markPartiallyConstructed (esto , allowMultipleContexts) val startTime = System.currentTimeMillis () privado [chispa] val parado: AtomicBoolean = nuevo AtomicBoolean ( falso ) privado [chispa] def afirmarNotStopped (): Unidad = { if (parado. obtener ()) { val activeContext = SparkContext.activeContext. get () val activeCreationSite = if (activeContext == null ) { " (No activo SparkContext.) " } más { activeContext.creationSite.longForm } lanzar una nueva IllegalStateException ( s "" " No se pueden llamar métodos en un SparkContext detenido. | Este SparkContext detenido se creó en: | | $ {creationSite.longForm} | | El SparkContext actualmente activo se creó en: | | $ activeCreationSite "" " .stripMargin) } } def this () = this ( new SparkConf ()) defthis (master: String, appName: String, conf: SparkConf) = this (SparkContext.updatedConf (conf, master, appName)) def this ( master: String, appName: String, sparkHome: String = null , jars: Seq [String ] = Nil, environment: Map [String, String] = Map ()) = { this (SparkContext.updatedConf ( new SparkConf (), master, appName, sparkHome, jars, environment)) }
privado [spark] def this (master : String, appName: String) = this (master, appName,null , Nil, Map ()) private [spark] def this (master: String, appName: String, sparkHome: String) = this (master, appName, sparkHome, Nil, Map ())
private [spark] def this (master) : String, appName: String, sparkHome: String, jars: Seq [String]) = this (master, appName, sparkHome, jars, Map ()) // cerrar sesión en la versión de Spark en el controlador de Spark logInfo (s " Running Spark version $ SPARK_VERSION " )
2. Configuración de SparkConf
Al inicializar SparkContext, solo se necesita un objeto de configuración SparkConf como parámetro. La definición de la clase SparkConf para guardar la configuración está en el archivo SparkConf.scala en el mismo directorio. Su miembro principal es una tabla hash, donde los tipos de clave y valor son ambos tipos de cadena:

Aunque SparkConf proporciona algunas interfaces simples para la configuración, de hecho, todas las configuraciones se almacenan en la configuración en forma de pares <clave, valor>. Por ejemplo, establecer el método maestro es establecer el elemento de configuración spark.master.
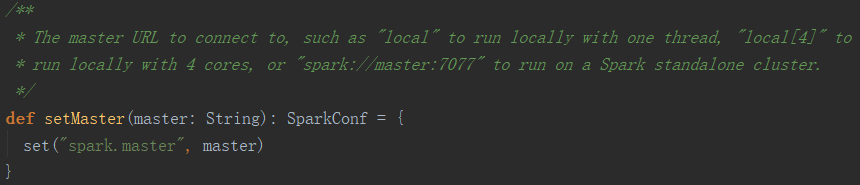
Por lo tanto, puede usar el elemento de configuración spark.master en el archivo de configuración, o la opción --master en la lista de parámetros, o el método setMaster () para establecer la dirección maestra, pero sus prioridades son diferentes.
Solo se puede iniciar un SparkContext por JVM, de lo contrario, se generará una excepción de forma predeterminada. Por ejemplo, en un entorno de programación interactivo iniciado a través de spark-shell, se ha creado un objeto SparkContext llamado sc de forma predeterminada. Si un objeto StreamingContext se crea directamente, entonces Informará un error. Una solución simple es detener primero el sc predeterminado.
Por supuesto, también puede ignorar este error estableciendo spark.driver.allowMultipleContext en verdadero, de la siguiente manera:

3. Proceso de inicialización.
Durante la construcción de SparkContext, todos los servicios se han iniciado. Debido a las características de la sintaxis de Scala, todos los constructores llamarán al constructor predeterminado, y el código del constructor predeterminado está directamente en la definición de clase. Además de inicializar varias configuraciones y registros, una de las operaciones de inicialización más importantes es iniciar el Programador de tareas y el Programador de DAG. El código es el siguiente:
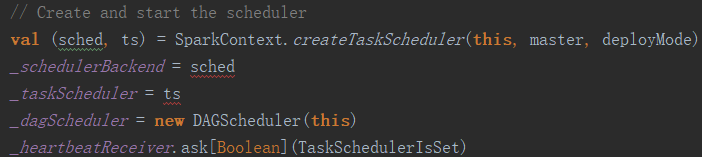
La diferencia entre la programación de DAG y la programación de tareas es que DAG es una programación de alto nivel, dibuja un gráfico acíclico dirigido para cada trabajo, rastrea la salida de cada etapa, calcula la ruta más corta para completar el trabajo y envía la tarea al programador de tareas Para ejecutar. El programador de tareas solo es responsable de aceptar la solicitud del programador de DAG y es responsable de la ejecución de la programación real de la tarea, por lo que la inicialización de DAGScheduler debe ser posterior al programador de tareas.
La ventaja del diseño separado de DAG y Task es que Spark puede diseñar de manera flexible su propia programación de DAG, y también se puede combinar con otros sistemas de programación de recursos, como YARN y Mesos.
El planificador de tareas en sí se crea en la función createTaskScheduler. De acuerdo con los diferentes modos especificados cuando se envía el programa Spark, se pueden iniciar diferentes tipos de programadores. Y en aras de la tolerancia a fallos, createTaskScheduler devolverá dos planificadores con un maestro y un respaldo. Tomando el modo de clúster YARN como ejemplo, los programadores maestro y en espera corresponden a diferentes tipos de instancias, pero se carga la misma configuración. El código es el siguiente:
case masterUrl => val cm = getClusterManager (masterUrl) match { case Some (clusterMgr) => clusterMgr case None => throw new SparkException ( " No se pudo analizar la URL maestra: ' " + master + " ' " ) } try { val Scheduler = cm.createTaskScheduler (sc, masterUrl) val backend = cm.createSchedulerBackend (sc, masterUrl, planificador) cm.initialize (planificador, backend) (backend, planificador) } captura { case se: SparkException => throw se case NonFatal (e) => throw new SparkException ( " El planificador externo no puede ser instanciado " , e) } }
4. Otras interfaces funcionales
Además de inicializar el entorno y conectarse al clúster Spark, SparkContext también proporciona muchas entradas funcionales, de la siguiente manera:
1. Crear un RDD. Todos los métodos para crear RDD se definen en SparkContext, como paralelizar y textFilenewAPIHadoopFile.
2. Persistencia RDD. Los métodos de operación persistente de RDD persistRDD y unpersistRDD también se definen en SparkContext.
3. Crear variables compartidas. Incluyendo contadores y variables de difusión.
4.detener (). Detener SparkContext.
5.runJob. Envíe la operación de acción RDD, que es el punto de entrada para todas las ejecuciones programadas.