
Instalar Solr
- Descargar el paquete jar oficial de Solr Dirección de descarga oficial de Solr
- Utilicé el paquete de instalación solr-7.7.2-src.tgz para construir
- Descargar descomprimir local

Crear espacio de trabajo central
- Puede entenderse como base de datos Mysql, puede haber múltiples bases de datos bajo un localhost local
- Copie el directorio y modifíquelo en un núcleo personalizado, copie la carpeta server / solr / configsets / _default en el servidor / solr y personalice el nombre para publicar

- La primera copia es solo la carpeta conf, echemos un vistazo a la estructura interna

- Estos dos son los archivos de configuración principales; si no, cree su propioMismo nombreArchivo xml
- Tenga en cuenta que la versión de Solr 5.X a continuación no se llama managed-schema.xml sino que se llama archivo schema.xml
Instalar el tokenizador IK
- Descargue el paquete jar de separador de palabras IK El separador de palabras IK depende del número de versión de Solr para descargar el separador de palabras IK correspondiente
- Después de la descarga, colóquelo en la carpeta solr-7.7.2 / server / solr-webapp / webapp / WEB-INF / lib

- Configure managed-schema.xml y agregue el siguiente código a cualquier ubicación para habilitar la segmentación de palabras usando el tokenizador IK
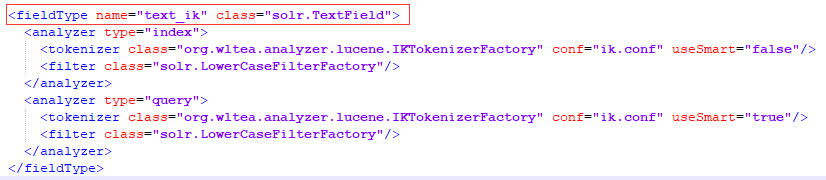
- Una vez completada la instalación, probará si la instalación se realizó correctamente en el cliente Solr ...
Sincronización de configuración Configuración de Mysql
Crear / modificar data-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://127.0.0.1:3306/nsi_database?useSSL=false&serverTimezone=UTC&tinyInt1isBit=false"
user="root"
password="123456"/>
<document>
<entity name="nsi_post_category_item" query="SELECT * FROM `nsi_post_category_item` WHERE is_check = 1">
<field column="item_id" name="itemId"/>
<field column="title" name="title"/>
<field column="summary_desc" name="summaryDesc"/>
<field column="content" name="content"/>
<field column="post_type" name="postType"/>
<field column="post_icon" name="postIcon"/>
<field column="comment_num" name="commentNum"/>
<field column="share_num" name="shareNum"/>
<field column="watch_num" name="watchNum"/>
<field column="collect_num" name="collectNum"/>
<field column="tag" name="tag"/>
<field column="open_id" name="openId"/>
<field column="avatar" name="avatar"/>
<field column="nick_name" name="nickName"/>
<field column="is_check" name="isCheck"/>
</entity>
</document>
</dataConfig>
- No se describirá la etiqueta dataSouce. Cualquiera que haya escrito JDBC sabe lo que significa
- entidad nombre: Puede ser cualquier nombre o clase de entidad
consulta: Es la instrucción sql que desea consultar - campo columna: Es el campo en esta tabla, debe corresponder a lo contrario, no se puede especificar
nombre: El alias es para la indexación y la segmentación de palabras para Solr, pero debe corresponder al nombre en managed-schema.xml, de lo contrario no podrá crear la segmentación de índice y palabras
Implementación managed-schema.xml
<field name="itemId" type="pint" indexed="true" stored="true"/>
<field name="title" type="text_ik" indexed="true" stored="true"/>
<field name="summaryDesc" type="text_ik" indexed="true" stored="true"/>
<field name="content" type="text_ik" indexed="true" stored="true"/>
<field name="postType" type="text_ik" indexed="true" stored="true"/>
<field name="postIcon" type="string" indexed="false" stored="true"/>
<field name="commentNum" type="pint" indexed="false" stored="true"/>
<field name="shareNum" type="pint" indexed="false" stored="true"/>
<field name="watchNum" type="pint" indexed="true" stored="true"/>
<field name="collectNum" type="pint" indexed="false" stored="true"/>
<field name="tag" type="text_ik" indexed="true" stored="true"/>
<field name="openId" type="string" indexed="false" stored="true"/>
<field name="avatar" type="string" indexed="false" stored="true"/>
<field name="nickName" type="string" indexed="false" stored="true"/>
<field name="isCheck" type="pint" indexed="false" stored="true"/>
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/>
- Agregar a cualquier ubicación, el nombre del último archivo de configuración corresponde al nombre de este archivo de configuración
- tipo: Declare este tipo de campo (Solr tiene pinta, plong, string, text_ *) y muchos otros tipos, solo enumere los más utilizados,También puede especificar el tipo de tokenizer
- indexado: Si crear índice verdadero / falso
- almacenado: Si mostrar verdadero / falso en la biblioteca de índice
- carné de identidad: Si su tabla de datos tiene este campo, puede reemplazar la identificación de Solr, de lo contrario, Solr generará automáticamente una cadena uuid y la almacenará en esta identificación
Comience Solr
- Ingrese la línea de comando de DOS en la carpeta solr-7.7.2 / bin
- inicio solr
- solr stop -todos cerrados solr (hay muchos comandos, Baidu)

- Ver este mensaje es un inicio exitoso
- Visite localhost: 8983 para ingresar a la interfaz Solr

Agregar configuración central
- La primera vez que necesita especificar el intervalo de trabajo del núcleo, es decir, el archivo de configuración recién modificado

- nombre: Generalmente coherente con el nombre de la carpeta principal
- instanceDIr: La ruta principal del archivo se copia sola
- dataDir: Cree una carpeta de datos debajo de la carpeta de publicación y especifique la ruta
- config: En la ruta del archivo core / conf / solrconfig.xml
- esquema: En la ruta del archivo core / conf / managed-schema.xml
- Agregue Core directamente después de agregar la ruta anterior

Sincronice los datos de Mysql con la biblioteca de índice Solr
Detectar la instalación del tokenizador IK
- Encuentra el núcleo recién definido

- Pruebe si el tokenizer IK se instaló correctamente

- Si puede encontrar el representante de IK tokenizer instalado con éxito
- Simplemente escriba una oración y podrá ver que el tokenizador IK segmentará la oración por nosotros y luego usará estas palabras o palabras para buscar
Sincronizar datos

- Abra la pestaña dataImport
- Ver la configuración de la configuración a la derecha es la configuración en nuestro data-config.xml
- Ejecutar Haga clic en Importar actualización para actualizar

- Importación exitosa
- Ver si la biblioteca de índice tiene datos

- Ingrese al panel de consulta a la izquierda
- La declaración de consulta de Solr puede ser Baidu
- numFound es el número total, los elementos del parámetro dentro son mis alias personalizados
La escritura a mano no es fácil, pero puede ayudarte, ¡por favor, dale me gusta! ! !
Si necesita reimprimir, indique la fuente, dé una rosa y deje la fragancia
