Java implementa consulta de asociación de dos tablas para mongoDB
Registre el proceso de aprendizaje de Java para implementar la consulta de asociación de dos tablas de mongodb, que es conveniente para revisar cuando la necesite en el futuro.
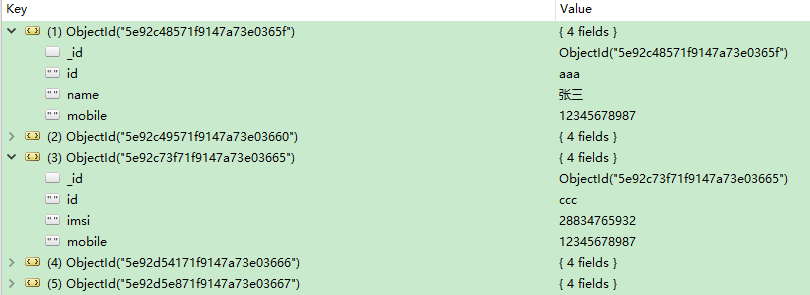
Escenario: hay dos tablas en mongodb, debe realizar una consulta asociada basada en la identificación.
Los datos en la Tabla 1 son los siguientes:

Los datos en la Tabla 2 son los siguientes:
Para realizar la consulta relacionada de dos tablas, debe usar la búsqueda de mongodb. Cuando se devuelve el resultado de la consulta, debe filtrar los datos sin que el conjunto de resultados esté vacío. En este momento, debe usar la coincidencia de mongodb.
La implementación de Java requiere el paquete mongo-java-driver. Aquí se usa mongo-java-driver-3.9.0.jar. Las dependencias del espejo maven de Ali son las siguientes
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.9.0</version>
</dependency>
El código Java se implementa de la siguiente manera:
MongoClient mongoClient = new MongoClient("localhost", 27017);
//“test”为连接的数据库
MongoDatabase mongoDatabase = mongoClient.getDatabase("test");
//test1是表1
MongoCollection<Document> mongoCollection = mongoDatabase.getCollection("test1");
List<Bson> aggregateList = new ArrayList<>(1);
//利用lookup进行关联查询
//test2是表2,两个表根据id进行关联,关联的结果定义一个新的字段
/**Aggregates.lookup函数的说明:
* lookup(final String from, final String localField, final String foreignField, final String as)
* Creates a $lookup pipeline stage, joining the current collection with the one specified in from
* using equality match between the local field and the foreign field
* @param from the name of the collection in the same database to perform the join with.
* @param localField the field from the local collection to match values against.
* @param foreignField the field in the from collection to match values against.
* @param as the name of the new array field to add to the input documents.
*/
aggregateList.add(Aggregates.lookup("test2", "id", "id", "result"));
//利用match将没有关联到的结果过滤掉
aggregateList.add(Aggregates.match(Filters.ne("result", new ArrayList<String>(0))));
AggregateIterable<Document> aggregateIterable = mongoCollection.aggregate(aggregateList);
for (Document document : aggregateIterable) {
System.out.println(document.toJson());
}
Los resultados devueltos son los siguientes:
{ "_id" : { "oid" : "5e92c58671f9147a73e03662" }, "id" : "aaa", "keys" : ["name", "mobile"], "values" : ["姓名", "手机"], "result" : [{ "_id" : { "oid" : "5e92c48571f9147a73e0365f" }, "id" : "aaa", "name" : "张三", "mobile" : "12345678987" }, { "_id" : { "oid" : "5e92d5e871f9147a73e03667" }, "id" : "aaa", "name" : "李四", "mobile" : "12345678987" }] }
{ "_id" : { "oid" : "5e92c64e71f9147a73e03664" }, "id" : "ccc", "keys" : ["imsi", "mobile"], "values" : ["IMSI", "手机"], "result" : [{ "_id" : { "oid" : "5e92c73f71f9147a73e03665" }, "id" : "ccc", "imsi" : "28834765932", "mobile" : "12345678987" }] }
Todo el proceso de implementación requiere una cierta comprensión del concepto de "canalización" en mongodb. Por ejemplo, en este escenario, los resultados de la consulta se consultan primero mediante la búsqueda, y luego el conjunto de resultados se pasa para que coincida con el filtrado a través de la "canalización".