1. Descripción general
En el artículo anterior, mencionamos que durante el proceso de montaje durante la compilación, la plantilla se compilará en una expresión de render para prepararse para la formación de un vnode más adelante.
Repasemos el proceso de compilación.

Todo el proceso se divide en tres etapas:
1. Analice, convierta la plantilla en el árbol modelo AST.
2. Optimizar, marcar nodos estáticos.
3. Generar, generar una expresión de representación.
También lo presentaremos en tres capítulos, este capítulo se centra en la primera etapa.
En segundo lugar, la entrada
En el artículo anterior hablamos sobre el código en src / platform / web / entry-runtime-with-compiler.js
//2、编译,生成render
...
const { render, staticRenderFns } = compileToFunctions(template, {
shouldDecodeNewlines,
shouldDecodeNewlinesForHref,
delimiters: options.delimiters,
comments: options.comments
}, this)
options.render = render
options.staticRenderFns = staticRenderFns
...
}Los parámetros de entrada de compileToFunctions son plantilla, matriz de opciones y objeto vm, y finalmente devuelven objetos render y staticRenderFns. compileToFunctions se define en src / platform / compiler / index.js y createCompiler lo devuelve.
import { baseOptions } from './options'
import { createCompiler } from 'compiler/index'
const { compile, compileToFunctions } = createCompiler(baseOptions)createCompiler, cuya entrada es el objeto baseOptions, devuelve dos métodos, compile y compileToFunctions.
Continuar para ver createCompiler (src / compiler / index.js)
export const createCompiler = createCompilerCreator(function baseCompile (
template: string,
options: CompilerOptions
): CompiledResult {
const ast = parse(template.trim(), options)
if (options.optimize !== false) {
optimize(ast, options)
}
const code = generate(ast, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
})createCompiler es devuelto por el método createCompilerCreator, que se define en src / compiler / create-compiler.js
export function createCompilerCreator (baseCompile: Function): Function {
return function createCompiler (baseOptions: CompilerOptions) {
function compile (
template: string,
options?: CompilerOptions
): CompiledResult {
...
//真正实现编译的核心代码
const compiled = baseCompile(template, finalOptions)
...
compiled.errors = errors
compiled.tips = tips
return compiled
}
return {
compile,
compileToFunctions: createCompileToFunctionFn(compile)
}
}
}El parámetro de entrada de createCompilerCreator es el método baseCompile. El método createCompiler se define en el cuerpo de la función y el método de compilación se define en createCompiler. En este método, se llama a baseCompile para realizar la compilación real. createCompiler devuelve el método compileToFunctions, que se implementa en createCompileToFunctionFn
export function createCompileToFunctionFn (compile: Function): Function {
const cache = Object.create(null)
return function compileToFunctions (
template: string,
options?: CompilerOptions,
vm?: Component
): CompiledFunctionResult {
....
const compiled = compile(template, options)
....
return (cache[key] = res)
}
}
El parámetro de entrada de createCompileToFunctionFn es el método de compilación, que devuelve las funciones de compileTo. Este es el método que llamamos inicialmente y finalmente encontramos la fuente.
El proceso de definir toda la entrada es muy redondo. Utilizamos la siguiente imagen para arrancar la piel capa por capa.
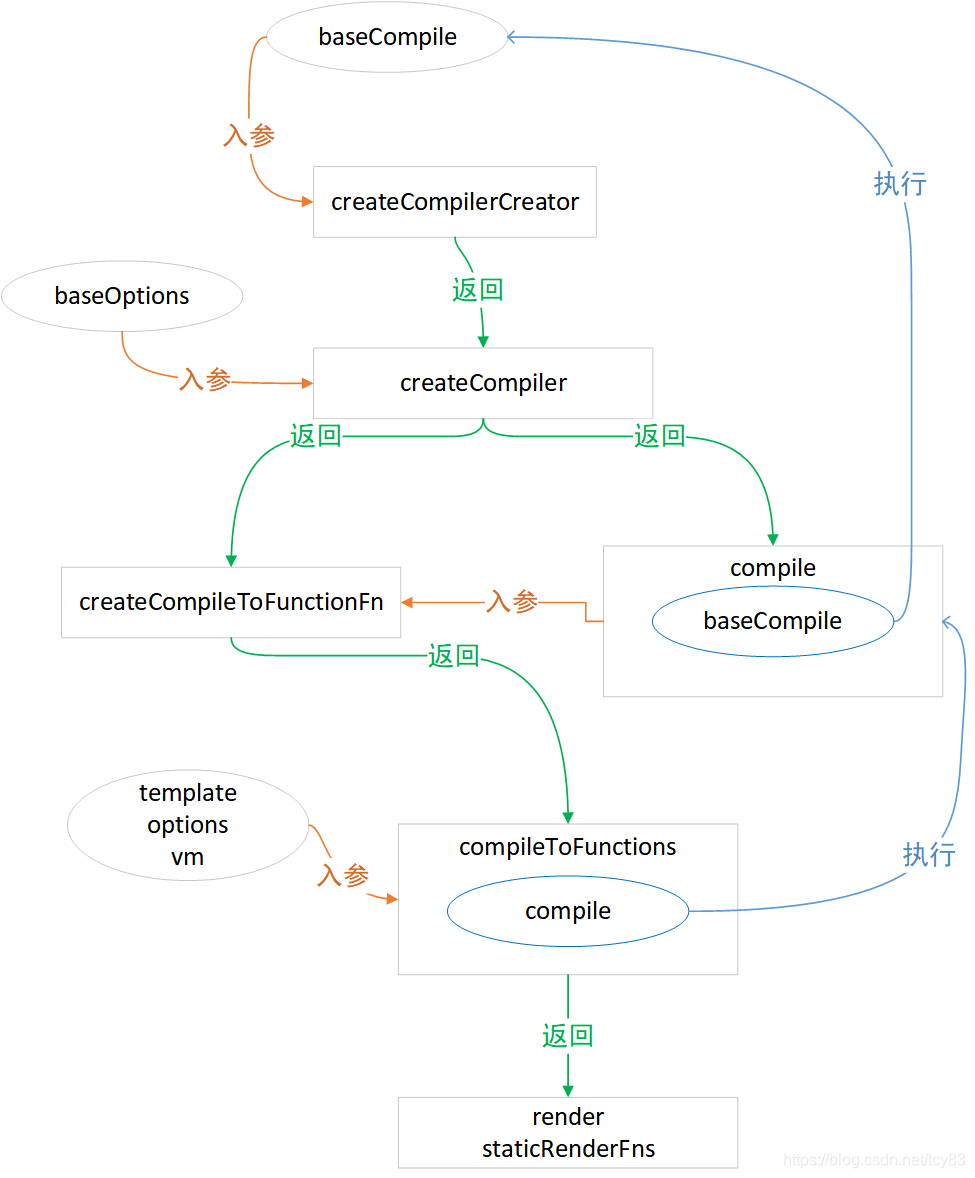
¿Por qué quieres hacer esto? Esta no es una técnica llamativa. Las opciones base que vue.js compila en diferentes plataformas son diferentes, pero el proceso de compilación básico baseComplie es el mismo. Escribimos la pseudofunción al curry de este proceso.
createCompilerCreator(baseCompile)(baseOptions)(compile)(template,options,vm)3. AST
Según el análisis anterior, la compilación final es ejecutar el método baseCompile.
export const createCompiler = createCompilerCreator(function baseCompile (
template: string,
options: CompilerOptions
): CompiledResult {
//1、parse,将templat转成AST模型
const ast = parse(template.trim(), options)
//2、optimize,标注静态节点
if (options.optimize !== false) {
optimize(ast, options)
}
//3、generate,生成render表达式
const code = generate(ast, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
})Este método define tres etapas del proceso de compilación. El análisis consiste en convertir la plantilla en modelo AST, AST es un árbol de sintaxis abstracta. Tomamos la siguiente plantilla como ejemplo.
<div id="app">
<ul>
<li v-for="item in items">
itemid:{{item.id}}
</li>
</ul>
</div>Después de convertirse en el modelo de árbol abstracto AST, es como sigue:
{
"type": 1,
"tag": "div",
"attrsList": [
{
"name": "id",
"value": "app"
}
],
"attrsMap": {
"id": "app"
},
"children": [
{
"type": 1,
"tag": "ul",
"attrsList": [],
"attrsMap": {},
"parent": {
"$ref": "$"
},
"children": [
{
"type": 1,
"tag": "li",
"attrsList": [],
"attrsMap": {
"v-for": "item in items"
},
"parent": {
"$ref": "$[\"children\"][0]"
},
"children": [
{
"type": 2,
"expression": "\"\\n itemid:\"+_s(item.id)+\"\\n \"",
"tokens": [
"\n itemid:",
{
"@binding": "item.id"
},
"\n "
],
"text": "\n itemid:{{item.id}}\n "
}
],
"for": "items",
"alias": "item",
"plain": true
}
],
"plain": true
}
],
"plain": false,
"attrs": [
{
"name": "id",
"value": "\"app\""
}
]
}Cada elemento del AST contiene información sobre sus propios nodos (etiqueta, atributo, etc.) y, al mismo tiempo, los elementos primarios y secundarios apuntan a su elemento primario y elemento secundario, respectivamente, anidados en capas para formar un árbol. No profundizaremos en la descripción de cada atributo por el momento, pero primero tendremos una comprensión intuitiva. Veamos cómo se forma este árbol.
Cuatro, analizar
El método de análisis se define en src / parser / index.js. Este método tiene más contenido. Escribimos la estructura de la siguiente manera:
export function parse (
template: string,
options: CompilerOptions
): ASTElement | void {
....
//定义AST模型对象
let root
...
//主要的解析方法
parseHTML(template, {
...
})
//返回AST
return root
}
Los parámetros de entrada son plantillas y opciones, y la salida es la raíz del modelo AST generado. Se realiza principalmente llamando al método parseHTML, que también tiene más contenido, y solo escribimos la estructura
export function parseHTML (html, options) {
const stack = []
const expectHTML = options.expectHTML
const isUnaryTag = options.isUnaryTag || no
const canBeLeftOpenTag = options.canBeLeftOpenTag || no
let index = 0
let last, lastTag
//循环处理html
while (html) {
last = html
// Make sure we're not in a plaintext content element like script/style
//处理非script,style,textarea
if (!lastTag || !isPlainTextElement(lastTag)) {
let textEnd = html.indexOf('<')
//1."<"字符打头
if (textEnd === 0) {
// Comment:
//1.1、处理标准注释,<!--
if (comment.test(html)) {
...
}
// http://en.wikipedia.org/wiki/Conditional_comment#Downlevel-revealed_conditional_comment
//1.2、处理条件注释,<![
if (conditionalComment.test(html)) {
...
}
// Doctype:
//1.3、处理申明,DOCTYPE
const doctypeMatch = html.match(doctype)
if (doctypeMatch) {
...
}
// End tag:
//1.4、处理结束标签
const endTagMatch = html.match(endTag)
if (endTagMatch) {
...
}
// Start tag:
//1.5、处理开始标签
const startTagMatch = parseStartTag()
if (startTagMatch) {
...
}
}
//2、非"<"打头,作为text内容处理
let text, rest, next
if (textEnd >= 0) {
....
}
...
}else{
....
}
}
...
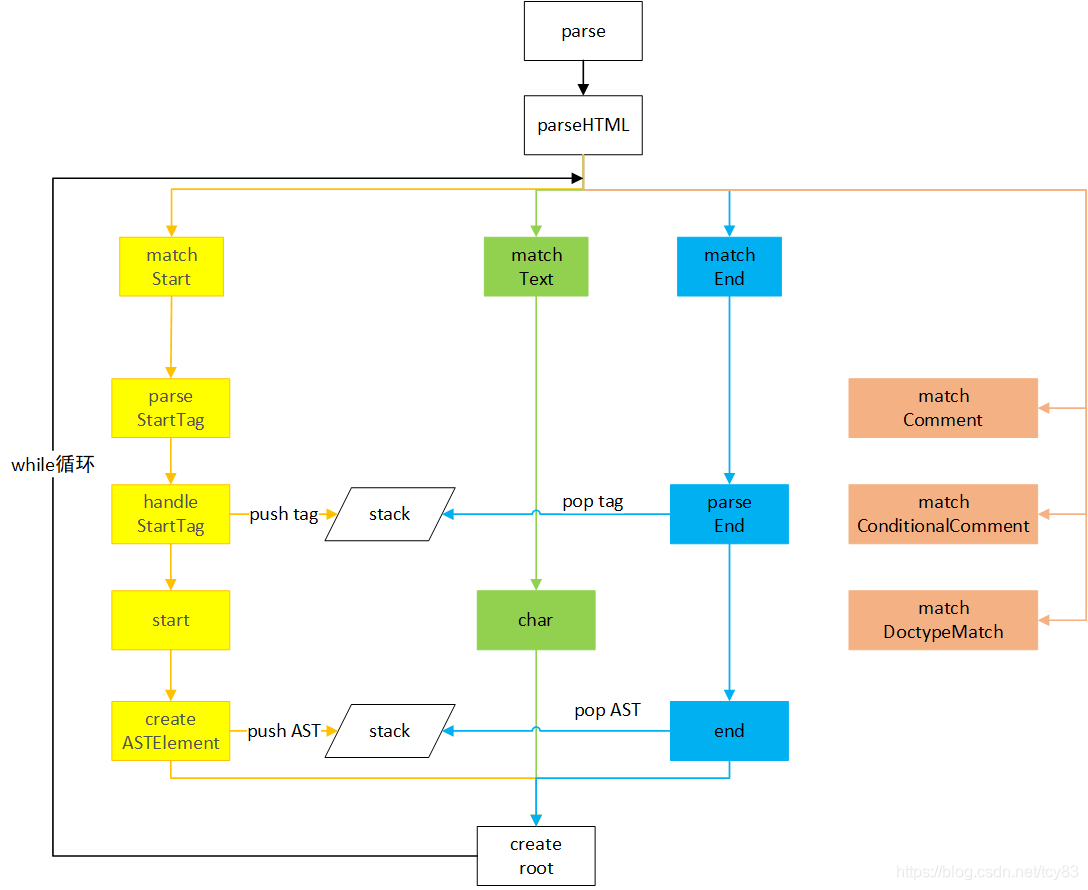
}A través del ciclo while, los caracteres HTML entrantes se analizan línea por línea. El método completo se puede dividir en dos partes:
1. Los caracteres que comienzan con "<" se juzgan aún más en tipos, que se dividen en notas estándar, notas condicionales, aplicaciones, etiquetas finales, etiquetas iniciales y diferentes tratamientos.
2. Los caracteres que no comienzan con "<" se tratan como texto.
Tomemos como ejemplo la plantilla anterior, centrándonos en el análisis del proceso de análisis de inicio, fin y módulo de texto.
Five, startTag
El análisis de la plantilla html comienza desde la primera oración:
<div id="app">
<ul>
...Como comienza con el carácter "<", ingresa al bucle y es procesado por el segmento de código de la etiqueta de inicio:
const startTagMatch = parseStartTag()
if (startTagMatch) {
handleStartTag(startTagMatch)
if (shouldIgnoreFirstNewline(lastTag, html)) {
advance(1)
}
continue
}1 、 parseStartTag
Analice la plantilla a través de varias expresiones regulares y guarde la información relevante en el objeto de coincidencia.
function parseStartTag () {
//1、匹配<${qnameCapture}字符,如:<div
const start = html.match(startTagOpen)
//start=[<div,div,index=0]
if (start) {
//定义match对象保存相关属性
const match = {
tagName: start[1],
attrs: [],
start: index
}
//2、步进tag的长度
advance(start[0].length)
//3、循环查找该标签的attr,直到结束符>
let end, attr
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
//步进该attr的长度
advance(attr[0].length)
match.attrs.push(attr)
}
//4、tag结束,记录全局的位置
if (end) {
match.unarySlash = end[1]
advance(end[0].length)
match.end = index
return match
}
}
}(1) RegExp (`^ <$ {qnameCapture}`) coincide con la etiqueta de inicio. En este ejemplo, el carácter coincidente es "<div" y el objeto coincidente se inicializa.
(2) La longitud de la etiqueta de paso,
function advance (n) {
//index为全局位置
index += n
//从n位置开始截取,后面的字符作为新的html
html = html.substring(n)
}Los caracteres después de interceptar las etiquetas se utilizan como nuevo html, una vez completados, son los siguientes:
id="app">
<ul>
...(3) Recorra los atributos de la etiqueta hasta que encuentre un carácter final>
La condición del bucle se juzga por primera vez. Html.match (atributo) coincide con el atributo id de carácter = "aplicación", ingresa al bucle, escalona el número de caracteres del atributo y guarda el atributo en el objeto de coincidencia. El nuevo html después de los pasos es el siguiente:
>
<ul>
...El segundo juicio de la condición del bucle, html.match (startTagClose) coincide con el carácter final>, y salta directamente.
(4) El final de la etiqueta, escalone la longitud del carácter final y registre y guarde la posición global, en este caso, la longitud de <div id = "app"> 14. Los nuevos caracteres html son:
<ul>
...En este punto, la etiqueta de inicio del div se analiza y el objeto de coincidencia se devuelve para continuar con el siguiente flujo de procesamiento.
2 、 handleStartTag
El parámetro de entrada de handleStartTag es el objeto de coincidencia, que implementa principalmente la regularización del objeto de atributo y llama al método de inicio para crear el modelo AST de la etiqueta.
//处理开始标签
function handleStartTag (match) {
const tagName = match.tagName
const unarySlash = match.unarySlash
//有些tag可以作结束处理
if (expectHTML) {
if (lastTag === 'p' && isNonPhrasingTag(tagName)) {
parseEndTag(lastTag)
}
if (canBeLeftOpenTag(tagName) && lastTag === tagName) {
parseEndTag(tagName)
}
}
//是否为单元素,如<img />
const unary = isUnaryTag(tagName) || !!unarySlash
//1、整理attr为字面量对象
const l = match.attrs.length
const attrs = new Array(l)
for (let i = 0; i < l; i++) {
const args = match.attrs[i]
// hackish work around FF bug https://bugzilla.mozilla.org/show_bug.cgi?id=369778
if (IS_REGEX_CAPTURING_BROKEN && args[0].indexOf('""') === -1) {
if (args[3] === '') { delete args[3] }
if (args[4] === '') { delete args[4] }
if (args[5] === '') { delete args[5] }
}
const value = args[3] || args[4] || args[5] || ''
const shouldDecodeNewlines = tagName === 'a' && args[1] === 'href'
? options.shouldDecodeNewlinesForHref
: options.shouldDecodeNewlines
attrs[i] = {
name: args[1],
value: decodeAttr(value, shouldDecodeNewlines)
}
}
//2、非单元素,压入到stack,并在lastTag中缓存
if (!unary) {
stack.push({ tag: tagName, lowerCasedTag: tagName.toLowerCase(), attrs: attrs })
lastTag = tagName
}
//3、创建该标签的AST模型,并建立关联关系
if (options.start) {
options.start(tagName, attrs, unary, match.start, match.end)
}
}El proceso principal tiene las siguientes tres partes:
1. Atrs de regularización de bucle es un objeto literal. Después de la regularización, los objetos son los siguientes:
attrs = [{nombre = id, valor = app}]
2. Para elementos no individuales, introdúzcalo en la pila y guarde en caché el nombre de etiqueta actual como lastTag. Esta pila realiza el procesamiento en bucle cerrado en la siguiente etiqueta final.
3. Continúe llamando al método de inicio para crear un modelo AST del elemento de etiqueta y construir un árbol modelo.
3 、 inicio
options.start es el método principal en el que se crea el modelo AST y se establece la asociación.
start (tag, attrs, unary) {
// check namespace.
// inherit parent ns if there is one
const ns = (currentParent && currentParent.ns) || platformGetTagNamespace(tag)
// handle IE svg bug
/* istanbul ignore if */
if (isIE && ns === 'svg') {
attrs = guardIESVGBug(attrs)
}
//1、创建ASTelement
let element: ASTElement = createASTElement(tag, attrs, currentParent)
if (ns) {
element.ns = ns
}
if (isForbiddenTag(element) && !isServerRendering()) {
element.forbidden = true
process.env.NODE_ENV !== 'production' && warn(
'Templates should only be responsible for mapping the state to the ' +
'UI. Avoid placing tags with side-effects in your templates, such as ' +
`<${tag}>` + ', as they will not be parsed.'
)
}
//2、以下是处理属性中各类指令,从attrsList中删除相关的属性,
// apply pre-transforms
for (let i = 0; i < preTransforms.length; i++) {
element = preTransforms[i](element, options) || element
}
if (!inVPre) {
processPre(element)
if (element.pre) {
inVPre = true
}
}
if (platformIsPreTag(element.tag)) {
inPre = true
}
if (inVPre) {
processRawAttrs(element)
} else if (!element.processed) {
// structural directives
processFor(element)
processIf(element)
processOnce(element)
// element-scope stuff
processElement(element, options)
}
function checkRootConstraints (el) {
if (process.env.NODE_ENV !== 'production') {
if (el.tag === 'slot' || el.tag === 'template') {
warnOnce(
`Cannot use <${el.tag}> as component root element because it may ` +
'contain multiple nodes.'
)
}
if (el.attrsMap.hasOwnProperty('v-for')) {
warnOnce(
'Cannot use v-for on stateful component root element because ' +
'it renders multiple elements.'
)
}
}
}
// tree management
//3、构建AST模型树
if (!root) {
//如第一个元素,设置根元素
root = element
checkRootConstraints(root)
} else if (!stack.length) {
//其他元素,构建关联关系
// allow root elements with v-if, v-else-if and v-else
if (root.if && (element.elseif || element.else)) {
checkRootConstraints(element)
addIfCondition(root, {
exp: element.elseif,
block: element
})
} else if (process.env.NODE_ENV !== 'production') {
warnOnce(
`Component template should contain exactly one root element. ` +
`If you are using v-if on multiple elements, ` +
`use v-else-if to chain them instead.`
)
}
}
if (currentParent && !element.forbidden) {
if (element.elseif || element.else) {
processIfConditions(element, currentParent)
} else if (element.slotScope) { // scoped slot
currentParent.plain = false
const name = element.slotTarget || '"default"'
;(currentParent.scopedSlots || (currentParent.scopedSlots = {}))[name] = element
} else {
//建立父子element关系
currentParent.children.push(element)
element.parent = currentParent
}
}
//4、非单元素,将元素push到stack数组,
if (!unary) {
currentParent = element
stack.push(element)
} else {
closeElement(element)
}
}Ignorando los detalles, hay cuatro partes principales:
1. Llame a createASTElement para crear el objeto modelo AST del elemento de etiqueta. '
export function createASTElement (
tag: string,
attrs: Array<Attr>,
parent: ASTElement | void
): ASTElement {
return {
type: 1,//1-标签,2-表达式text,3-普通内容
tag,//标签
attrsList: attrs,//标签属性数组
attrsMap: makeAttrsMap(attrs),//标签属性map
parent,//父元素
children: []//子元素
}
}En la tercera parte, hablamos sobre el modelo AST final, que se define aquí. El modelo AST es un objeto literal que define la información relevante del elemento de etiqueta, incluidas las etiquetas, los atributos, los elementos primarios y secundarios asociados, etc.
2. Procese varias instrucciones en el atributo y elimine los atributos relacionados de la lista de atributos para prepararse para el procesamiento posterior.
3. Construya el árbol modelo AST. El primer elemento de etiqueta sirve como elemento raíz, como el div en este ejemplo, y el siguiente elemento de etiqueta establece la asociación estableciendo padres e hijos. Finalmente forma un árbol.
4. Para elementos no individuales, empuje el elemento AST actual a la matriz de la pila (observe la diferencia con la pila anterior, los objetos guardados por los dos son diferentes y también son preparaciones de ciclo cerrado para el final de la última). Para elementos individuales, llame a closeElement para finalizar el procesamiento.
Dicho esto, en realidad procesé la línea <div id = "app">. Luego, el ciclo while continúa procesando las dos líneas siguientes, y el proceso es el mismo.
<ul>
<li v-for="item in items">Seis, texto
Una vez que se completa el procesamiento de la etiqueta de inicio, cuando se analiza la siguiente línea, se procesa como texto porque no comienza con "<".
itemid:{{item.id}}
</li>
</ul>
</div>Ingrese el siguiente bloque de código
let text, rest, next
if (textEnd >= 0) {
rest = html.slice(textEnd)
while (
!endTag.test(rest) &&
!startTagOpen.test(rest) &&
!comment.test(rest) &&
!conditionalComment.test(rest)
) {
// < in plain text, be forgiving and treat it as wen
//普通文本中包含的<字符,作为普通字符处理
next = rest.indexOf('<', 1)
if (next < 0) break
textEnd += next
rest = html.slice(textEnd)
}
//1、获取text内容,并步进到新的位置
text = html.substring(0, textEnd)
advance(textEnd)
}
//html的<字符匹配结束,将剩余字符都作为text处理
if (textEnd < 0) {
text = html
html = ''
}
//2、创建text的AST模型
if (options.chars && text) {
options.chars(text)
}1. Según textend, coloque los caracteres delante del contenido del texto (es decir, </ li>), itemid: {{item.id}}.
2. Llamar caracteres para procesar caracteres. Crea un modelo AST.
Veamos su lógica principal:
chars (text: string) {
...
//创建AST模型
if (text) {
let res
//包含表达式的text
if (!inVPre && text !== ' ' && (res = parseText(text, delimiters))) {
children.push({
type: 2,
expression: res.expression,
tokens: res.tokens,
text
})
}
//纯文本的text
else if (text !== ' ' || !children.length || children[children.length - 1].text !== ' ') {
children.push({
type: 3,
text
})
}
}
}Incorpore texto como elemento secundario de su propio elemento en el árbol modelo AST. En este caso, es el elemento etiqueta de <li>. Según si la expresión está incluida en el texto (es decir, "{{}}"), hay dos casos.
1. Texto de expresión, escriba 3 y use atributos de expresión y tokens para guardar la expresión.
2. Texto sin formato, tipo 2.
Este ejemplo pertenece al primer caso. Después de completar el análisis, lo siguiente:
{
"type": 2,
"expression": "\"\\n itemid:\"+_s(item.id)+\"\\n \"",
"tokens": [
itemid:",
{"@binding": "item.id"},
"\n "
],
"text": "\n itemid:{{item.id}}\n "
}Puede ver el contenido de expresiones y tokens, y los analizaremos en detalle más adelante.
El análisis de texto de texto se completa y luego el procesamiento termina con la etiqueta.
Siete, fin
Después de analizar la etiqueta final, se realiza el procesamiento en bucle cerrado para el elemento objeto de la etiqueta. Sigue leyendo el resto del html
</li>
</ul>
</div>Fragmento de código procesado:
const endTagMatch = html.match(endTag)
if (endTagMatch) {
const curIndex = index
//步进结束tag的长度
advance(endTagMatch[0].length)
parseEndTag(endTagMatch[1], curIndex, index)
continue
}html.match (endTag) coincide regularmente con </ xx> dichos caracteres, determinados como el carácter final de la etiqueta, registra la posición actual del carácter final en curIndex, luego escalona la longitud de la etiqueta final, llama a parseEndTag para procesar.
function parseEndTag (tagName, start, end) {
...
// Find the closest opened tag of the same type
//1、从stack数组中查找结束的tag标签,并记录位置pos
if (tagName) {
for (pos = stack.length - 1; pos >= 0; pos--) {
if (stack[pos].lowerCasedTag === lowerCasedTagName) {
break
}
}
} else {
// If no tag name is provided, clean shop
pos = 0
}
//2、当pos>0,关闭从pos到最后的所有元素,理论上只会有一个,但也要防止不规范多写了结束标签
if (pos >= 0) {
// Close all the open elements, up the stack
for (let i = stack.length - 1; i >= pos; i--) {
if (process.env.NODE_ENV !== 'production' &&
(i > pos || !tagName) &&
options.warn
) {
options.warn(
`tag <${stack[i].tag}> has no matching end tag.`
)
}
//处理end
if (options.end) {
options.end(stack[i].tag, start, end)
}
}
// Remove the open elements from the stack
//从stack中删除元素
stack.length = pos
lastTag = pos && stack[pos - 1].tag
} else if (lowerCasedTagName === 'br') {
...
}
}1. Encuentre la etiqueta en la pila. Al comienzo del proceso, empujamos el objeto de coincidencia de cada etiqueta en la pila. En este ejemplo, la pila tiene tres objetos
[{etiqueta: div, ...}, {etiqueta: ul, ...}, {etiqueta: li, ...}]
Haga coincidir de atrás hacia adelante, con el tercer objeto li. Grabar pos como 2.
2. Cuando pos> 0 indica que la etiqueta coincide, se llama al método final para su procesamiento y el objeto se elimina de la pila.
end () {
// remove trailing whitespace
//从AST中查找该标签的模型对象
const element = stack[stack.length - 1]
//删除text为空格的child
const lastNode = element.children[element.children.length - 1]
if (lastNode && lastNode.type === 3 && lastNode.text === ' ' && !inPre) {
element.children.pop()
}
// pop stack
//stack中删除该模型模型对象,并变更当前的currentParent
stack.length -= 1
currentParent = stack[stack.length - 1]
//关闭
closeElement(element)
}El método final realiza el procesamiento de ciclo cerrado para el objeto del elemento de etiqueta, elimina el objeto modelo AST de la pila y actualiza el objeto principal actual.
Después de completar el proceso </ li>, continúe procesando las etiquetas como </ ul>, </ div>.
Después de que parseHTML termine de procesar todos los caracteres html, se rastreará hasta el método de análisis y finalmente devolverá el objeto raíz del árbol modelo AST.
8. Total
Este capítulo se centra en el análisis del proceso de análisis. A continuación, usamos un diagrama de flujo para clasificar todo el proceso