representación de texto es la base del procesamiento del lenguaje natural, la representación de texto de buena o mala afectan directamente a la totalidad del lenguaje natural el rendimiento de procesamiento del sistema. vectorización texto es una representación de texto de manera importante.
texto texto vectorización es capaz de expresar un vector representado como una serie de semántica de texto. Si es chino o Inglés, las palabras son la expresión de la unidad básica de procesamiento de texto.
La etapa actual del texto para cuantificar la mayor parte de la investigación es cuantificar logrado a través de palabras. Al mismo tiempo, hay un número considerable de investigadores artículo o frase como unidad básica de procesamiento de texto, y también lo han hecho doc2vec técnicas str2vec.
métodos de vectorización de texto:
Palabras como la unidad básica en el procesamiento de la técnica word2vec
doc2vec
str2vec
Texto para cuantificar el texto de once páginas de texto será casos vectorizados.
Vectorización algoritmo word2vec
bolsas de palabras (Bolsa de la palabra) es el primer modelo de la unidad básica de texto de procesamiento de texto con el método de cuantificación.
Dos de texto simple:
John le gusta ver películas, María también le gusto.
John también le gusta los juegos de fútbol del reloj.
Sobre la base de estas dos palabras aparecen en el documento, construido como sigue diccionario (el diccionario):
{ "John": 1, "le gusta ": 2" a ":. 3," reloj ":. 4," Películas ":. 5," también ":. 6," fútbol ": . 7," juegos ":. 8," María ":. 9," demasiado ": 10}
diccionario contiene más de 10 palabras, cada palabra tiene un índice único, entonces podemos utiliza cada texto una está representado vector de 10 dimensiones. En la siguiente manera:
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
[1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
del vector original orden de las palabras aparece en el texto, no importa, pero cada palabra en el diccionario aparece en el texto de la frecuencia. Aunque este método es sencillo, pero hay un problema de los siguientes tres aspectos: la
maldición de la dimensionalidad. Obviamente, si el diccionario Ejemplos de arriba contiene 10.000 palabras, cada texto requiere una representación vectorial 10000-dimensional, lo que significa que además de las palabras que aparecen en la posición del texto no es cero, el resto de 9000 y más son 0 posición, tan alto dimensión del vector afectará seriamente su rendimiento.
Incapaz de retener la información de orden de las palabras.
Problemas vacío semántico.
En los últimos años, con el desarrollo de la tecnología de Internet, datos en Internet ha aumentado de forma espectacular. Un gran número de los no etiquetados númerosse generan los datos, por lo que los investigadores desviar la atención sobre el uso de datos no etiquetados minería información valiosa para arriba.
vector tecnología Word (word2vec) es para extraer información útil a partir de un gran número de texto no marcada usando redes neuronales producidas.
En general, la palabra es la unidad básica de la semántica.
Debido a que el modelo bolsa de palabras sólo palabras simbólicas, la bolsa de palabras modelo no contiene ninguna información semántica. Cómo hacer "la palabra significa" información semántica está contenida en el campo investigador se enfrenta a problemas.
Propuesto hipótesis de distribución (hipótesis de distribución) proporciona una base teórica para resolver los problemas anteriores.
La idea central es la hipótesis: el contexto de palabras similares, la semántica es también similar.
Seguido por algunos estudiosos compilados usando puntos de contexto métodos tela representa el significado de tales métodos es el modelo de espacio famosa palabra (palabra modelo de espacio).
Con todo tipo de duro para mejorar el desarrollo de algoritmos de computación y piezas asociadas potencia de los equipos, el modelo de red neuronal que emerge gradualmente en varios campos, la flexibilidad del modelado de contexto estructura de la red neuronal es la mayor ventaja representación palabra.
Construir relaciones entre las palabras de contexto y de destino a través de modelo de lenguaje es un método común. Palabra de vectores red neuronal modelo es el modelo de la relación entre el contexto y la palabra objetivo .
En los primeros días, justo a entrenar a la red neuronal palabra vector -producto del modelo de lenguaje generado en el proceso, entonces el modelo de red neuronal tiene una lengua depende de la dirección del desarrollo de la palabra este último vector de la función cualitativa.
神经网络语言模型(Neural Network Language Model , NNLM ) 与传统方法估算不同, NNLM 模型直接通过一个神经网络结构对n 元条件概率进行估计。
大致的操作是: 从语料库中搜集一系列长度为n 的文本序列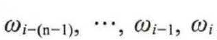 ,假设这些长度为n 的文本序列组成的集合为D , 那么NNLM 的目标函数如式:
,假设这些长度为n 的文本序列组成的集合为D , 那么NNLM 的目标函数如式:

上式的含义是: 在输入词序列为 的情况下,计算目标词为ωi的概率。
的情况下,计算目标词为ωi的概率。
