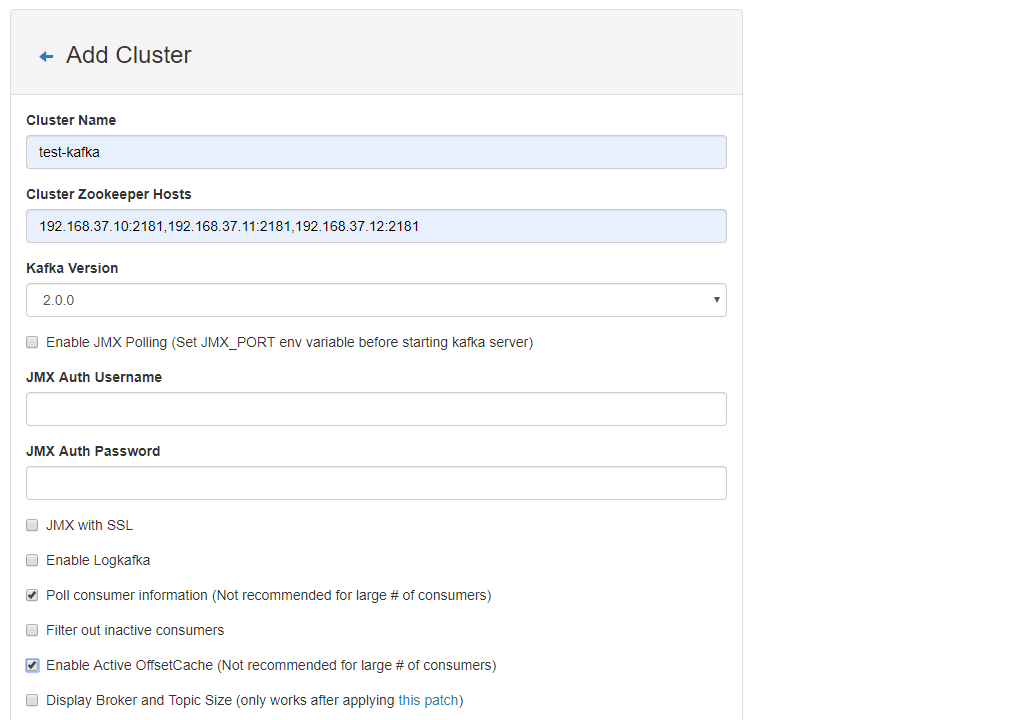
Gran Sección de datos: Kafka

Lo que Kafka?
Kafka es un alto rendimiento de distribución publicar, suscribirse sistema de mensajería, puede manejar todas las acciones de los consumidores transmisión de datos en el sitio. Esta acción (navegación web, búsqueda y otra acción del usuario) es un factor clave en muchas funciones sociales en las redes modernas. Estos datos por lo general debido al caudal requerido se consigue mediante el registro de procedimiento de polimerización y el registro.
Si no lo hace Kafka
Millones de mensajes por segundo en grandes áreas de datos, mensaje persistente no pueden ser procesados;
Los mensajes de texto arte, e-mail convencional, etc. operación asincrónica, el procesamiento de recorte y similares. (Por supuesto, también puede ser usado RabbitMQ, ActiveMQ, RocketMQ etc.)
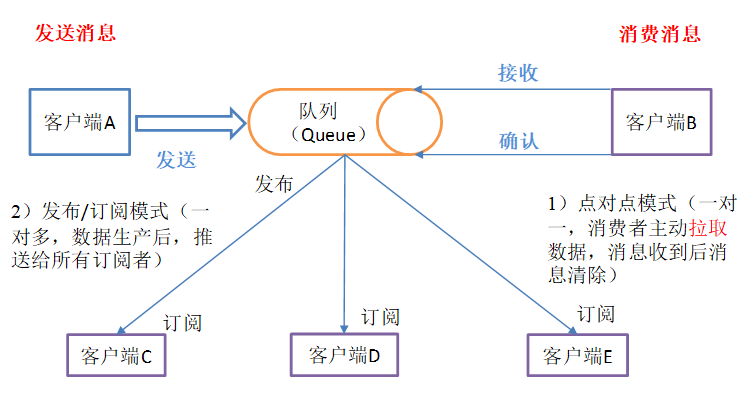
Hay dos tipos de modo de procesamiento de mensajes 1
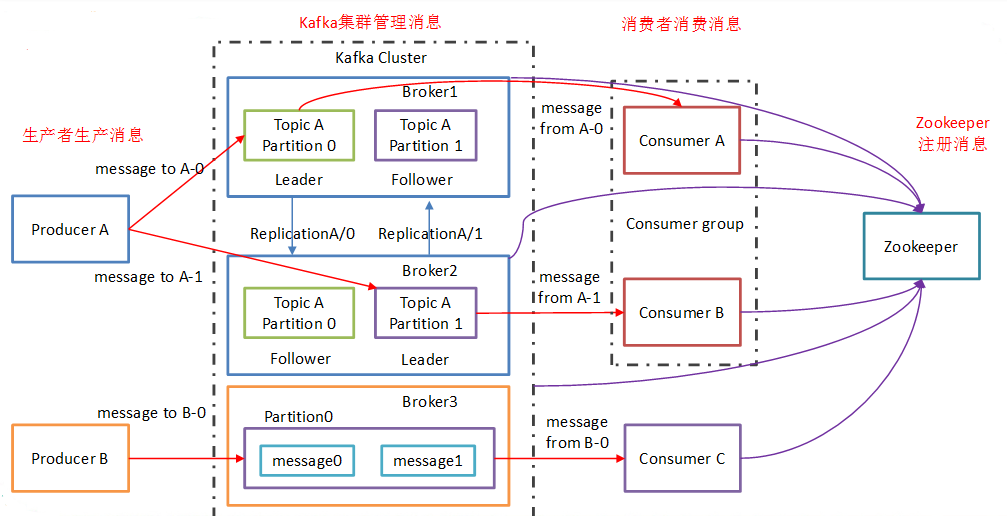
arquitectura 2 Kafka
-
Productor: productora de noticias, kafka agente cliente de mensajería.
-
Consumidor: los consumidores de noticias, kafka clientes del broker reciben mensajes
-
Tema: un tema para obtener instrucciones para utilizar la producción y el consumo es lo que el sujeto puede ser entendida como una cola. (La clasificación de datos)
-
Consumer Group (CG): tema kafka utilizado para implementar un mensaje de difusión (enviado a todos los consumidores) y unicast (emitido ninguna de consumo) medios. Un tema puede tener una pluralidad de CG. tema de la copia del mensaje (no copia fiel, es conceptual) para la totalidad de la CG, pero cada partición sólo el mensaje a un consumidor en el GC. Si desea una emisión, siempre que cada consumidor tiene una CG independiente sobre ella. Para lograr, siempre y cuando todos los consumidores de unidifusión en el mismo CG. El consumidor también se pueden agrupar por libremente sin mensaje CG se transmite varias veces a un tema diferente. (Por encima de la tópica mensaje de grupo enviado al consumidor, recibida por ConsumerA, no se puede recibir el ConsumerB, esta vez para lograr un unicast) (por encima de hipótesis, tres a cada consumidor un grupo de consumidores, una tópica 3 grupos tomaron conjuntamente terminado, entonces se da cuenta de la emisión) (teóricamente, que corresponde al número de particiones grupo de consumidores Topic en el número de consumidores el mejor rendimiento)
-
Broker: un servidor de Kafka es un corredor. Un grupo compuesto de una pluralidad de corredor. Un corredor puede recibir una pluralidad de tema.
-
Partición: Con el fin de lograr escalabilidad, un tema muy grande puede ser distribuido a una pluralidad Broker (es decir, servidor), el tema puede ser dividido en una pluralidad de partición, cada partición es una cola ordenada. particionar cada mensaje se le asigna un identificador secuencial (offset). Para kafka para asegurar que sólo una partición en un mensaje al consumidor, no garantiza todo un tema (s partición entre) la secuencia. (Kafka sólo se puede leer la información Líder de la partición en)
-
Offset: kafka almacenados los archivos se nombran de acuerdo con offset.kafka que ver con el nombre de los beneficios de compensación son fáciles de encontrar. Por ejemplo, usted quiere encontrar la ubicación en 2049, acaba de encontrar 2048.kafka de archivos. Por supuesto, el primer desplazamiento es 00000000000.kafka
-
zookeeper: salvar kafka información de configuración de clúster
3 Monitoreo
3.1 Kafkatool
Este software se utiliza para visualizar los datos y otra información de productor kafka, puede descargar e instalar.
-
Baidu dirección de disco de red: https://pan.baidu.com/s/1N8BCXXgVydrDvJYXRSYxdQ código de extracción: Calp
3.2 C
CMAK (anteriormente conocido como Kafka Manager) es una herramienta para la gestión de grupos de Kafka, que se utilizan principalmente para observar la información al consumidor. 3.0.x necesidad más java11 anterior, se puede ejecutar más de zookeeper3.5.x
-
Baidu dirección de disco de red: https://pan.baidu.com/s/1QJeRs36bbfm9xWTPEEYKfg código de extracción: la2m
- Carga de archivos de desempaquetado
mkdir /usr/local/src/CMAK
cd /usr/local/src/CMAK
unzip cmak-3.0.0.4.zip
cd cmak-3.0.0.4

- Modificar la configuración
vim conf/application.conf
ZK configuración del clúster necesita atención aquí y la correspondiente configuración de kafka, de lo contrario, no encuentra el grupo de consumidores web, reemplazado si no puede encontrar el nombre de host IP o el nombre de host en IP.
Las versiones antiguas
kafka-manager.zkhosts = "192.168.xx.xx: 2181,192.168.xx.xx: 2181,192.168.xx.xx: 2181"
La nueva versión
cmak.zkhosts = "192.168.xx.xx: 2181,192.168.xx.xx: 2181,192.168.xx.xx: 2181"
- comienzo
puerto de puerto predeterminado cmak 8080, por -Dhttp.port, designado; -Dconfig.file = conf / application.conf archivo de configuración especificado:
nohup bin/cmak -Dconfig.file=conf/application.conf -Dhttp.port=8080
4 Operación Comando
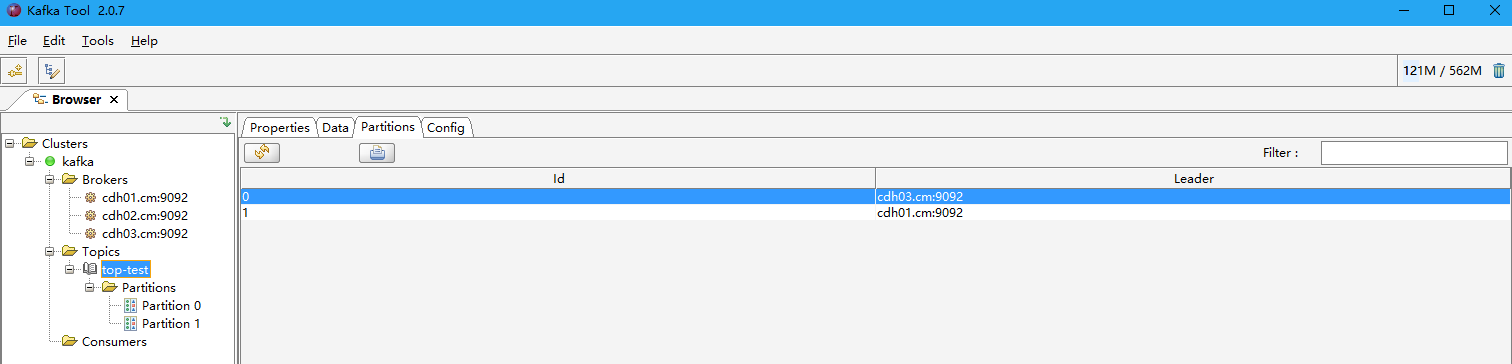
4.1 Creación de tema
#创建top-test主题,2个分区,2个副本
kafka-topics --create --zookeeper cdh01.cm:2181,cdh02.cm:2181,cdh03.cm:2181 --topic top-test --partitions 2 --replication-factor 2
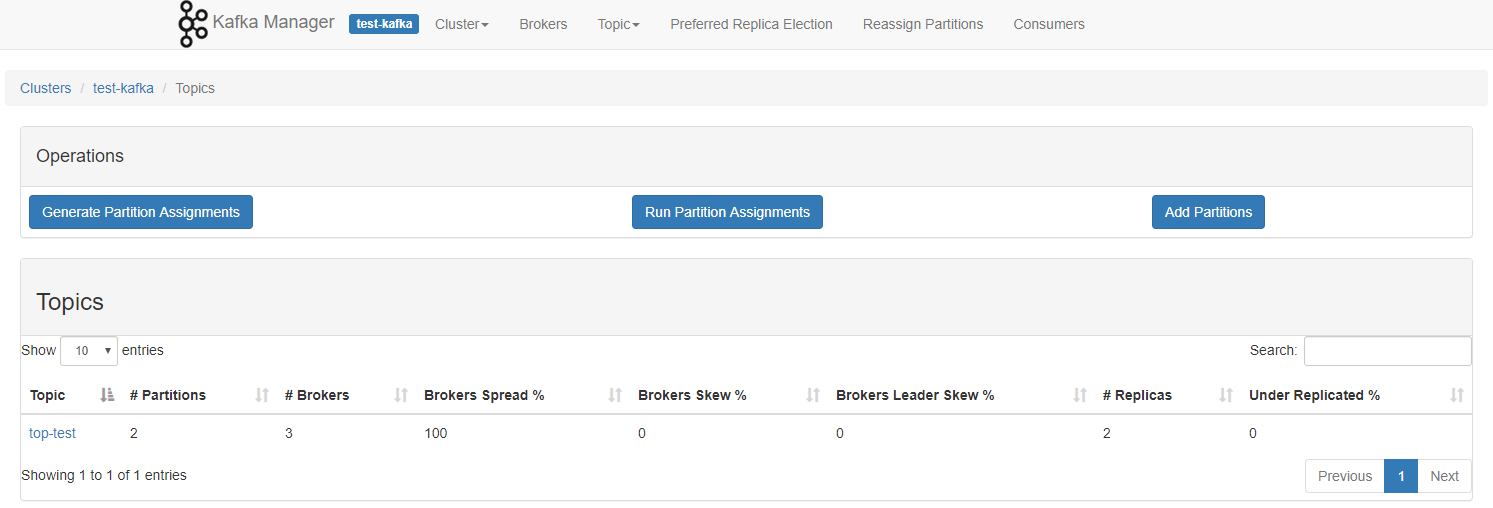
4.2 Ver Tema
kafka-topics --list --zookeeper cdh01.cm:2181,cdh02.cm:2181,cdh03.cm:2181
4.3 Borrar tema
kafka-topics --delete --zookeeper cdh01.cm:2181,cdh02.cm:2181,cdh03.cm:2181 --topic top-test
4.4 Ver los detalles del tema
kafka-topics --describe --zookeeper cdh01.cm:2181,cdh02.cm:2181,cdh03.cm:2181 --topic top-test

4.5 Productor - Consumidor
#生产者
kafka-console-producer --topic top-test --broker-list cdh01.cm:9092,cdh02.cm:9092,cdh03.cm:9092
#消费者(--from-beginning 从头开始读取)
kafka-console-consumer --topic top-test --bootstrap-server cdh01.cm:9092,cdh02.cm:9092,cdh03.cm:9092 --from-beginning --group g1
- En primer lugar, una pluralidad de entrada de datos en el lado del productor, de entrada aa-> ff I aquí, el efecto es el siguiente



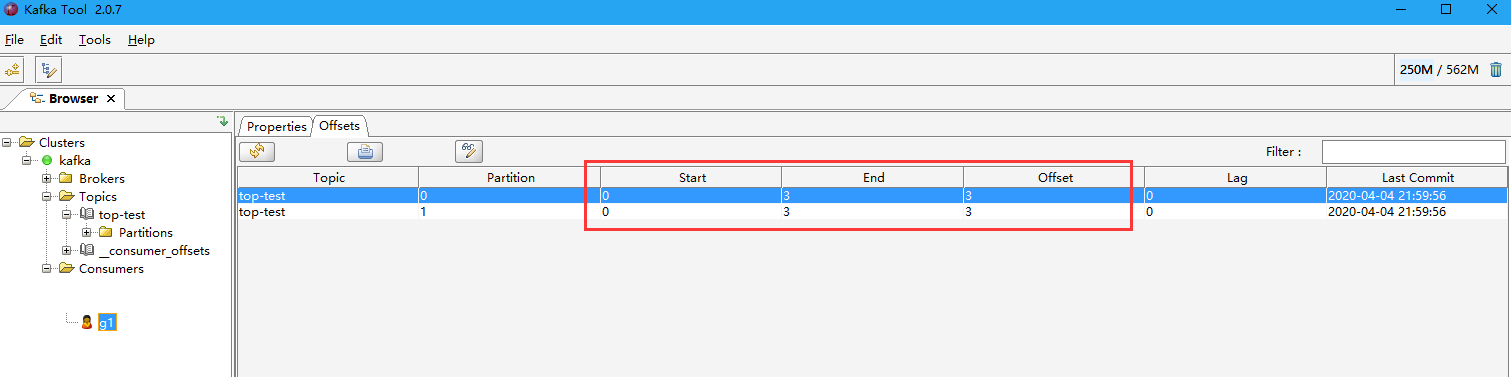

flujo de trabajo 5 Kafka
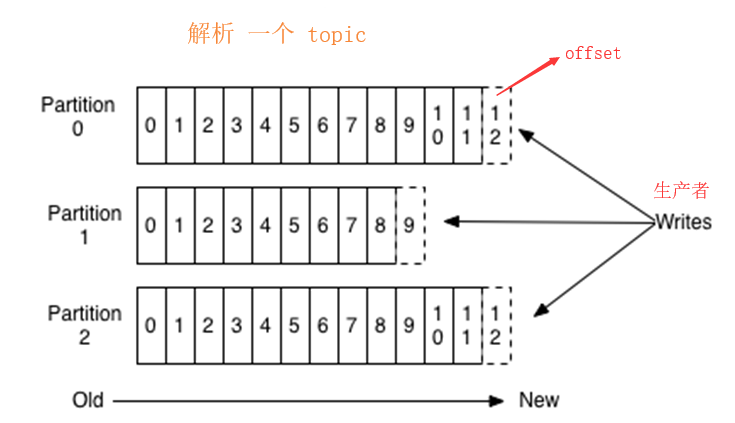
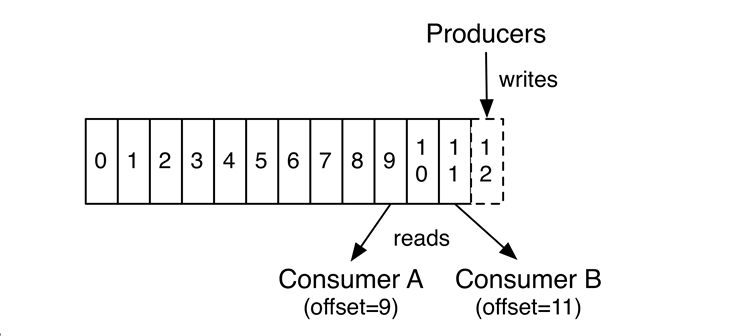
kafka cada partición se compensan de 0 a asegurar que el orden regional, no puede garantizar el orden mundial;
productor zk no se ha registrado, los consumidores registrados en zk.
tema es un concepto lógico, y en el concepto de partición física, cada partición correspondiente a un archivo de registro, el archivo de registro se almacena en los datos de producción. los datos de producción del productor se añade continuamente al final del archivo de registro, y cada uno tiene sus propios datos compensados. Los grupos de consumidores cada consumidor va a consumir su propia grabación en tiempo real a la cual offset, con el fin de recuperarse cuando se produce un error, continúan consumiendo desde la última posición. La figura siguiente:


5.1 proceso de producción de noticias
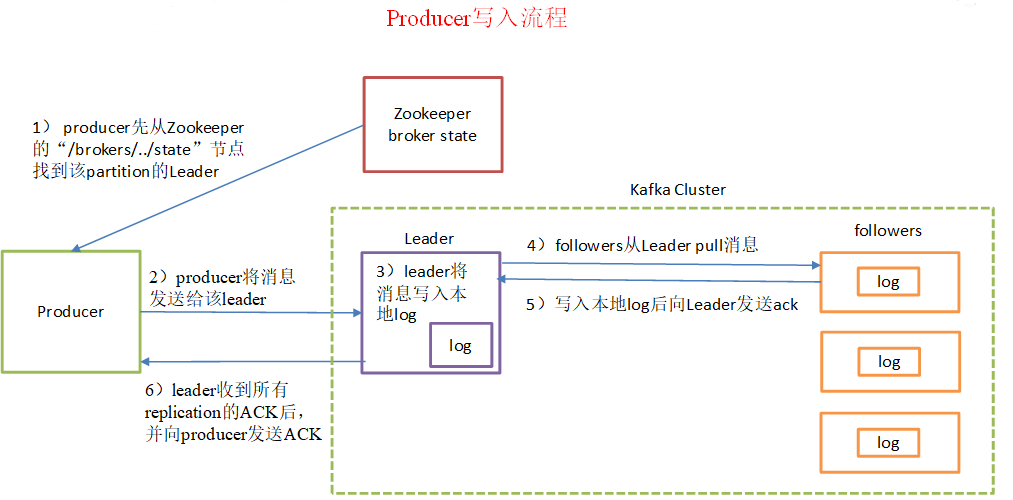
Paso 1 explicó: productor empleado del zoológico de iniciar el nodo "/brokers/.../state" encuentra la partición líder correspondiente al tema;
4-6 a paso para asegurar la fiabilidad de los datos, kafka ack seleccionado debe todo sido enviado con éxito para completar la sincronización.
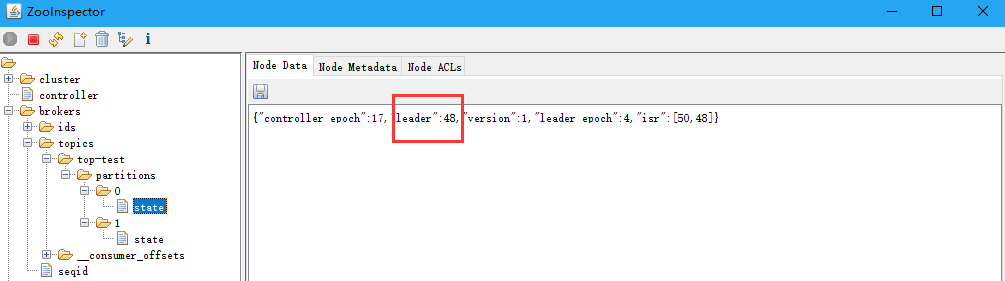

-
La partición razón
- Convenientemente extendido en un clúster, cada partición puede ser ajustado para encajar en la máquina, y pueden tener una pluralidad de composición partición tema, de modo que todo el clúster se puede adaptar a cualquier tamaño de los datos;
- Puede mejorar la concurrencia porque se puede leer y escribir en unidades de partición.
-
principio de partición
-
patition especifica, se utiliza directamente;
-
patition no se especifica, pero la clave especificada, la clave a través de un valor hash para patition
-
patition y la clave no se especifica, un selecto patition de votación.
-
5.2 proceso de información al consumidor
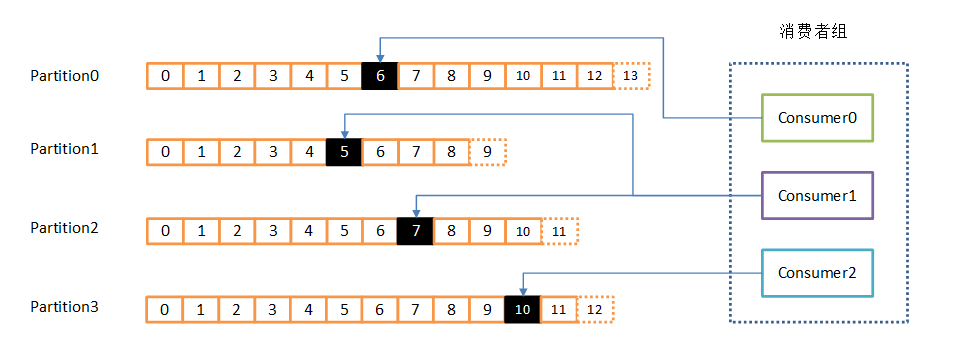
Los consumidores están muy por el trabajo en grupo de los consumidores grupo de consumidores, por uno o más consumidores, forman un grupo, un tema común de los consumidores. Cada partición sólo puede ser leída por el grupo en un consumidor al mismo tiempo, pero el grupo múltiple puede consumir esta partición al mismo tiempo. En el dibujo, un grupo compuesto por tres consumidor, el consumidor ha leído tema dos particiones, los otros dos para leer una partición. Un consumidor lee una partición, también llamado un consumidor es una partición del propietario.
En este caso, los consumidores pueden expandir horizontalmente lee gran número de mensajes simultáneamente. Además, si falla un consumidor, a continuación, los otros miembros del grupo se cargará automáticamente el balance de leer partición fallaron antes de los consumidores leen.
- consumo
- consumidor que utiliza el modo de tracción (pull), los datos leídos desde el corredor.
- empuje modelo (push) es difícil de adaptar a diferentes tasas de consumo de los consumidores, porque la tasa de transmisión de mensajes se determina por el corredor. Su objetivo es entregar el mensaje lo más rápido posible, pero es probable que esto causa al consumidor la oportunidad de procesar el mensaje, el rendimiento típico es una denegación de servicio, y la congestión de la red. Mientras que el modo de extracción puede estar en un consumo de energía gasto tasa de consumo adecuado de acuerdo con el mensaje.
- Para Kafka, modelo de extracción es más apropiado, que está diseñado para corredor de simplificar, los consumidores pueden controlar independientemente la velocidad de consumo del mensaje, mientras que el consumidor puede controlar sus patrones de consumo - también puede ser uno de los gastos de consumo de volumen, mientras que también elegir un diferente presentación para lograr una semántica diferente de transmisión.
- Las deficiencias tiran modo es que, si no hay datos de kafka, los consumidores pueden caer en la circulación, que hemos estado esperando para recibir datos. Para evitar esto, tenemos en nuestros parámetros de la petición de extracción, permite al consumidor a petición bloqueado "sondeo largo" en espera de la llegada de los datos (y, opcionalmente, a la espera de un número determinado de bytes para asegurar una gran tamaño de transferencia).
- consumidores nodo compensados información almacenada en el grupo de clientes en el cuidador del zoológico.
5.3 Guardar un mensaje
Como el productor de la producción de noticias seguirá añadiendo al final de los archivos de registro para evitar la ubicación de los datos y el problema de bajo rendimiento causado por archivo de registro es demasiado grande, Kafka toma de indexación fragmentación y mecanismo, cada patition en el segmento múltiple.
Cada segmento corresponde a dos archivos -> "Índice y .log." Archivo. Estos archivos se encuentran en una carpeta patition, que patition carpeta nombrar regla es: nombre del tema - el número de partición.
".Index y .log" desplazamiento de archivo del primer segmento de mensaje llamado actualmente de la siguiente manera:
00000000000000000000.index
00000000000000000000.log
00000000000000135489.index
00000000000000135489.log
00000000000000268531.index
00000000000000268531.log
La siguiente estructura esquemática de la ".index y .log" file:
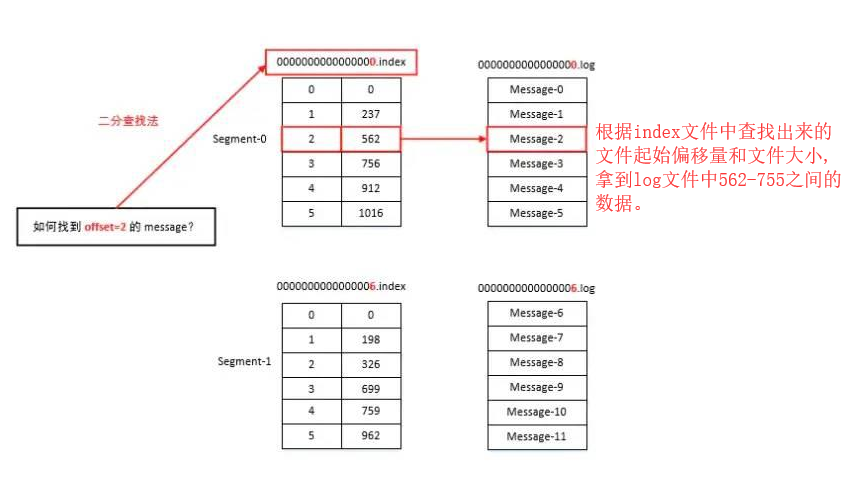
completo