Artículo Actualizado: 03/29/2020
Por convención, adjuntar un enlace de archivos en el texto de la primera.
Nombre del archivo: Chispa-2.4.5-bin-sin -hadoop.tgz
Tamaño del archivo: 159 MB
Enlace de descarga: https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.5/spark- la sin - bin-2.4.5 hadoop.tgz
SHA256: 40f58f117efa83a1d0e66030d3561a8d7678f5473d1f3bb53e05c40d8d6e6781
Nombre de archivo: SBT-1.3.8.tgz.7z
Tamaño del archivo: 54,9 MB
Enlace de descarga: https://www.lanzous.com/iameoaf
SHA256: 9E0662C84E6B99F2BAB0F51EC1F8C93FA89C5CE5400AD01CF2A98A63A816346D
Directorio artículo
- En primer lugar, descargar los archivos necesarios
- En segundo lugar, instalar la chispa
- 1, extracto de == Instalación
- 2, la configuración de modificar los archivos Spark spark-env.sh
- 3, ejecutar el ejemplo
- 4, iniciar la línea de comandos de chispa
- 5, resolver dos WARN
- En tercer lugar, la instalación de SBT
- Cuatro, la programación de chispa aplicación independiente
- 1, los procedimientos de preparación Scala
- 2, usando el programa de Scala SBT empaquetado
- 3, la ejecución del programa (si no la forma de resolver)
- 4, la solución no se mueve para ver la versión SBT
- 5, solución empaquetador lenta (cambiando espejo interno)
- 6, cada archivo en el SBT
- 五, Enjoy!
En primer lugar, descargar los archivos necesarios
1, descarga de chispa
1, sparkse puede ir a la web oficial http://spark.apache.org/downloads.html sí mismos para encontrar la versión correcta.
2, sparktambién se puede utilizar el texto de la primera spark-2.4.5-bin-without-hadoop.tgzrecta.
2. Descargar SBT
1, sbtse puede ir a la web oficial https://www.scala-sbt.org/ sí mismos para encontrar la versión correcta.
2, sbttambién se puede utilizar el texto de la primera sbt-1.3.8.tgz.7zrecta.
En segundo lugar, instalar la chispa
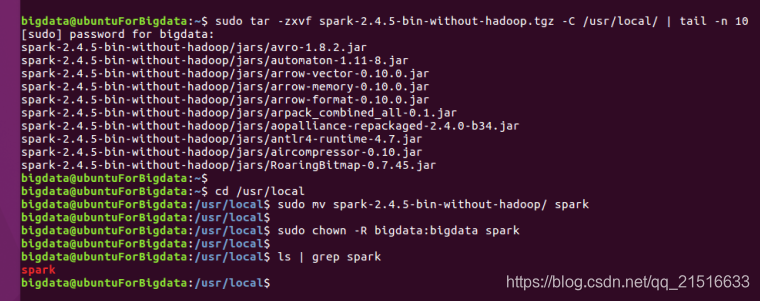
1, extracto de == Instalación
Nota 1: El tail -n 10único punto de vista de la salida el pasado 10 resultante, no se puede escribir.
Nota 2: La usernamenecesidad de sustituir su nombre de usuario.
sudo tar -zxvf spark-2.4.5-bin-without-hadoop.tgz -C /usr/local/ | tail -n 10
cd /usr/local
sudo mv spark-2.4.5-bin-without-hadoop/ spark
sudo chown -R username:username spark
2, la configuración de modificar los archivos Spark spark-env.sh
Nota: En el sparkcaso directorio y copiar spark-env.sh.templateel archivo y eliminar el .templatesufijo. Si bien se muestra una primera línea de este archivo de abajo para agregar export xxxxel código.
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
3, ejecutar el ejemplo
1, ejecute el siguiente comando en el directorio de chispa.
bin/run-example SparkPi
# bin/run-example SparkPi 2>&1 | grep "Pi is"
Nota: También puede utilizar la línea de comandos comentado que los resultados de filtración directa.
2, acabo de empezar a ir mal, y teniendo en cuenta la siguiente manera.
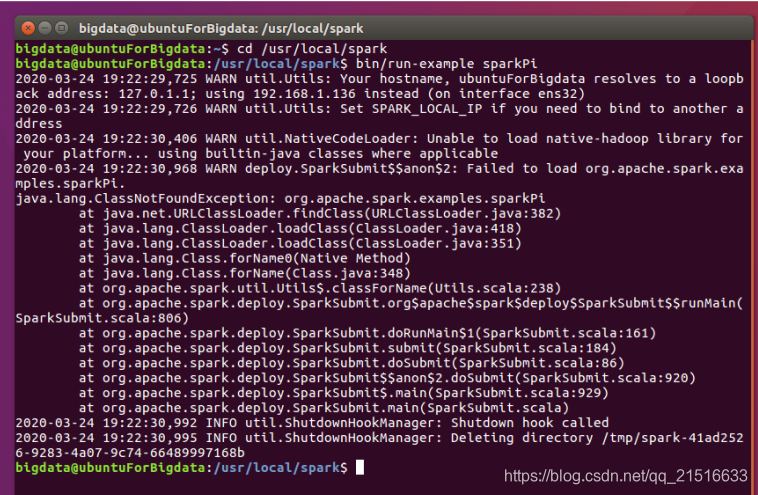
Luego utilizo el nmtuicomando para configurar la red para el modo manual, y escribe IP, puerta de entrada a volver a ejecutar el programa en él.
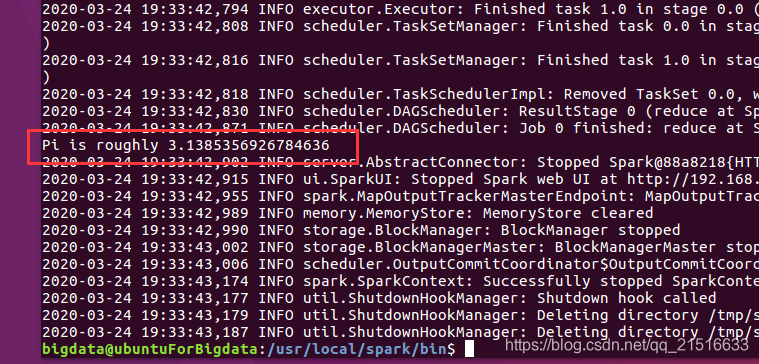
Resultados de operación y se encontró que asumo 3.1415926un pequeño hueco, pero si esto es así, oh, no está mal.
4, iniciar la línea de comandos de chispa
Nota: En /usr/local/spark/el siguiente comando para iniciar el directoriospark
./spark-shell --master local[2]
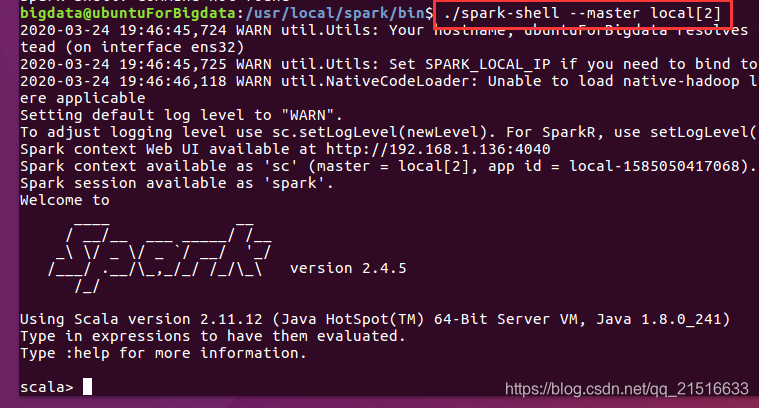
1, entonces también se puede acceder a la interfaz gráfica en el navegador, la dirección que hay en la información de salida anterior, aquí es 192.168.1.136:4040
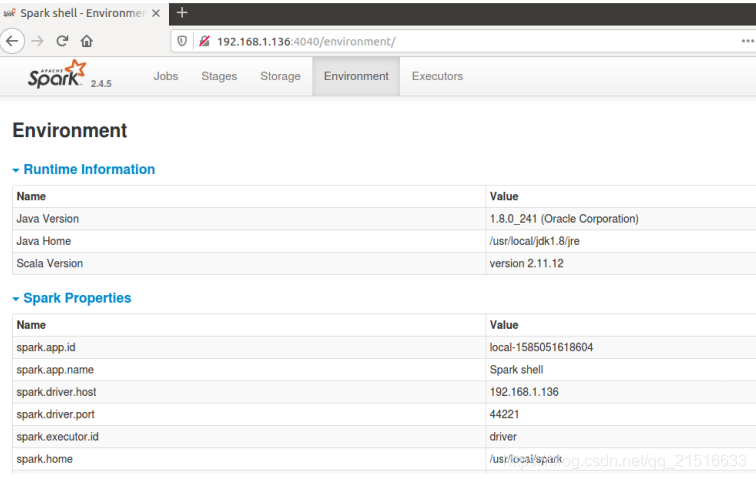
5, resolver dos WARN
1, en la salida del comando, que WARN util.Utils: Your hostname, xxxxx resolves to a loopback address: 127.0.1.1;
Solución:
En el conf/spark-env.shfichero de configuración Agregar SPARK_LOCAL_IP, tales como:
SPARK_LOCAL_IP="192.168.1.136"
Empezar de nuevo cuando él no puede verlo -
2, en la salida del comando, que spark Unable to load native-hadoop library for your platform...
Solución:
En el conf/spark-env.shfichero de configuración Agregar LD_LIBRARY_PATH, tales como:
LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
Nota: Su premisa es $HADOOP_HOMEque ya existe.
Empezar de nuevo cuando él no puede verlo -
En tercer lugar, la instalación de SBT
1, el extracto de la carpeta especificada
ls | grep sbt #查看当前文件夹是否有sbt安装包
sudo tar -zxvf sbt-1.3.8.tgz -C /usr/local
sudo cp /usr/local/sbt/bin/sbt-launch.jar /usr/local/sbt
sudo chown -R bigdata:bigdata /usr/local/sbt
sudo vim /usr/local/sbt/sbt
sudo chmod u+x /usr/local/sbt/sbt
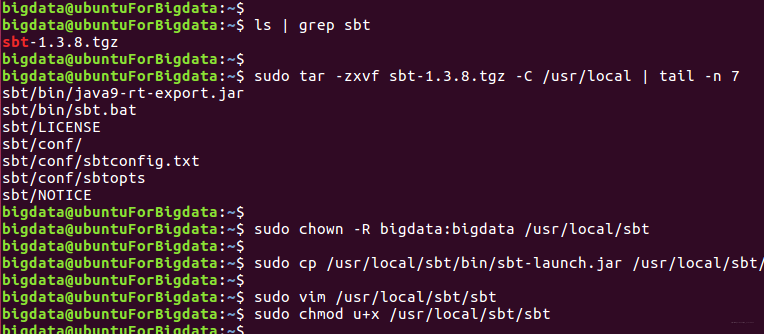
2, establecer y ejecutar la secuencia de comandos SBT
Script lee de la siguiente manera:
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"
Nota: El script necesita agregar permisos de ejecución, hay un paso en el código en la pantalla.
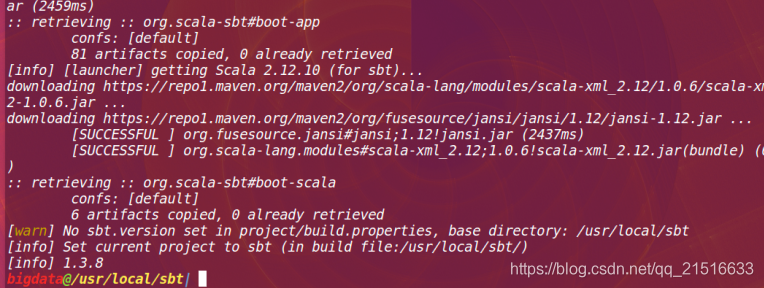
A continuación, ejecute:
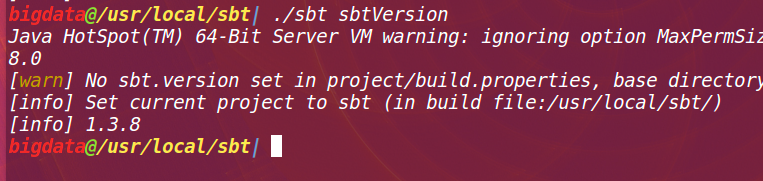
./sbt sbtVersion
Los primeros resultados de la ejecución son las siguientes:
los segundos resultados de la ejecución son las siguientes:
Cuatro, la programación de chispa aplicación independiente
1, los procedimientos de preparación Scala
1, establecer primero un directorio raíz
cd ~
mkdir -p ./sparkapp/src/main/scala
2, archivo de escritura SimpleApp.scala
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
2, usando el programa de Scala SBT empaquetado
1, la acumulación ~/sparkapp/simple.sbtguión (cualquier nombre aquí), de la siguiente manera:
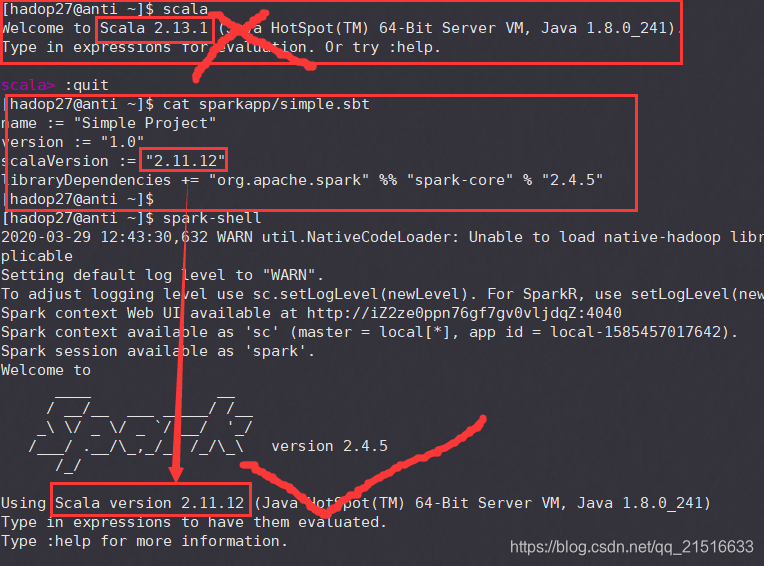
Nota 1: La versión Scala de la tercera línea aquí es que Scala versión se inicia cuando la salida de chispas!
Nota 2: La cuarta versión de línea de la chispa aquí es su chispa para iniciar la versión de pantalla de salida.
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.5"
2, ser empaquetado
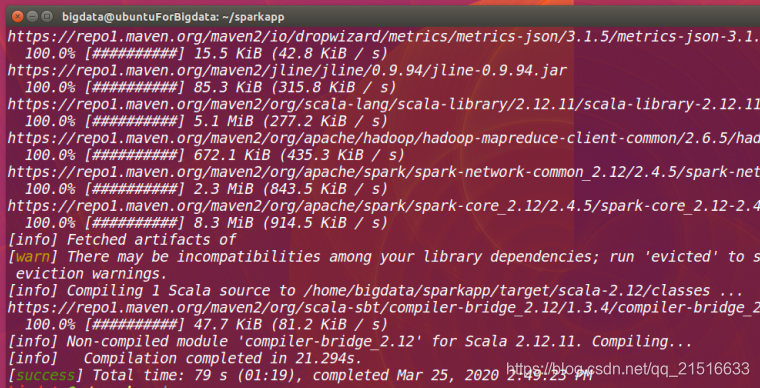
/usr/local/sbt/sbt package
Nota: La primera vez que se ejecuta, se puede descargar un archivo de red, esperando durante mucho tiempo.
resultados de la ejecución son las siguientes:
3, la ejecución del programa (si no la forma de resolver)
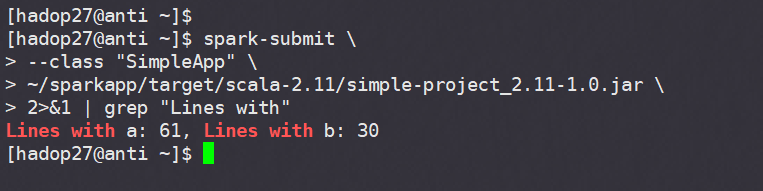
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
resultados de la ejecución son las siguientes:
我运行失败了,还在解决中。。。。。头大
Anormal de pantalla:
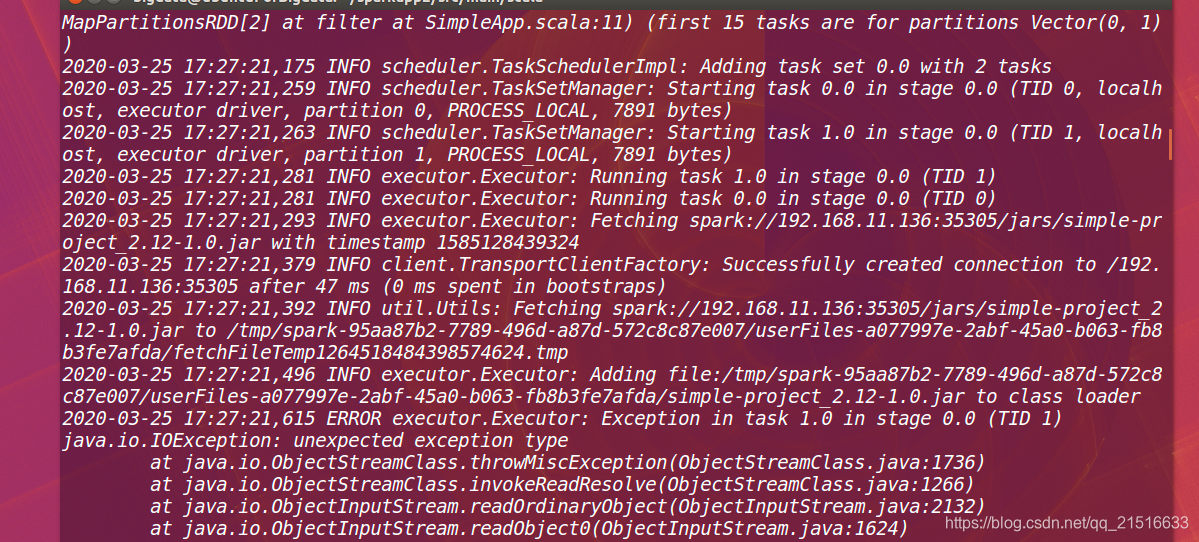
2020-03-29更新:问题已经解决。
El problema: En el simple.sbtarchivo, especifique la scalaversión debe ser spark-shellla versión Scala de la salida, en lugar de la versión Scala propia instalado por separado.
El resultado:
4, la solución no se mueve para ver la versión SBT
1) tratar de cambiar la fuente
Probé personalmente antes no cambiar la fuente, ejecutar sbt sbtVersioncomandos tienen que esperar media hora + .
Por supuesto, esta vez bajo diferentes entornos de red es diferente, puede ser mucho más rápido.
Después de que el intercambio de fuente, a la espera de 1 minuto 45 segundos comenzaron a volver a cargar la información, 2 minutos 26 segundos para completar la información de versión de visualización.
Ver cómo cambiar la fuente Paso cinco.
2) eliminar el perfil de nuevo
Si utiliza el sbt sbtVersioncomando para ver la versión SBT, no ha sido refrescado información de salida,
puede intentar instalar el archivo generado cuando el SBT antes de eliminar y luego volver a ejecutar el comando.
Los tres principales archivos a eliminar ~/.sbt, ~/.ivy, ~/.ivy2
se refiere específicamente al profesor Lin Ziyu blog: instalar la última versión de las herramientas y métodos de SBT Experiencia
5, solución empaquetador lenta (cambiando espejo interno)
Si una sbt packagevez ha sido rascador no es bueno, puede ser una conexión de origen de espejo poco lento. A continuación, puede seleccionar la imagen país.
En el ~/.sbt/repositoriesdocumento (si no crear su propia) añadir el siguiente:
Nota: el código siguiente en el principio repodebe ser capaz de costumbre, he cambiado no afectó a la ejecución del programa.
[repositories]
repo:https://maven.aliyun.com/repository/public
El paquete se ejecutará el comando de nuevo mucho más rápido.
Nota 1: Cuando me lleno de pruebas, las nuevas necesidades de los programas para descargar un paquete de N segundos biblioteca.
Nota 2: reenvasado (sin necesidad de descargar el archivo) un programa necesita 24+ segundos.
6, cada archivo en el SBT
Nota 1: En el siguiente directorio de instalación SBT SBT / conf / sbtopts archivo:
# ------------------------------------------------ #
# The SBT Configuration file. #
# ------------------------------------------------ #
# Disable ANSI color codes
#
#-no-colors
# Starts sbt even if the current directory contains no sbt project.
#
-sbt-create
# Path to global settings/plugins directory (default: ~/.sbt)
#
#-sbt-dir /etc/sbt
# Path to shared boot directory (default: ~/.sbt/boot in 0.11 series)
#
#-sbt-boot ~/.sbt/boot
# Path to local Ivy repository (default: ~/.ivy2)
#
#-ivy ~/.ivy2
# set memory options
#
#-mem <integer>
# Use local caches for projects, no sharing.
#
#-no-share
# Put SBT in offline mode.
#
#-offline
# Sets the SBT version to use.
#-sbt-version 0.11.3
# Scala version (default: latest release)
#
#-scala-home <path>
#-scala-version <version>
# java version (default: java from PATH, currently $(java -version |& grep versi
on))
#
#-java-home <path>
Nota 2: El documento encima de la ubicación y el uso de cada archivo de SBT.
