Antes de aprender el conocimiento del periodo hadoop de tiempo para aprender las bases teóricas de la operación real, al mismo tiempo, puede ser más hábil, ado se dijo para ejecutarse en uno de los hadoop mayoría de las palabras sencillas programa de recuento
En primer lugar me gustaría pegar el código fuente del programa para su código de referencia se divide en tres partes escritas en Ejecutar, mapa fase, reducir etapa
Mapa:
-
empaquetar wordsCount;
-
-
importación
java.io.IOException;
-
importación
java.util.StringTokenizer;
-
-
importación
org.apache.hadoop.io.IntWritable;
-
importación
org.apache.hadoop.io.LongWritable;
-
importación
org.apache.hadoop.io.Text;
-
importación
org.apache.hadoop.mapreduce.Mapper;
-
-
público
de clase WordsMapper extiende Mapper < LongWritable , texto , texto , IntWritable >
{
-
@Anular
-
protegida nula mapa (clave LongWritable, Valor de texto, Mapper <LongWritable, texto, texto, IntWritable> contexto .Context)
-
lanza
IOException, InterruptedException {
-
-
línea String = value.toString ();
-
StringTokenizer st = nuevo StringTokenizer (línea);
-
mientras que
(st.hasMoreTokens ()) {
-
palabra String = st.nextToken ();
-
context.write ( nuevo texto (palabra), nueva IntWritable ( 1 ));
-
}
-
-
}
-
-
}
Reducir:
-
empaquetar wordsCount;
-
-
importación
java.io.IOException;
-
-
importación
org.apache.hadoop.io.IntWritable;
-
importación
org.apache.hadoop.io.Text;
-
importación
org.apache.hadoop.mapreduce.Reducer;
-
-
público
de clase WordsReduce extiende Reductor < texto , IntWritable , texto , IntWritable >
{
-
-
@Anular
-
protegida vacío reducir (clave de texto, Iterable <IntWritable> iterador,
-
Reductor <texto, IntWritable, texto, IntWritable> contexto .Context)
lanza
IOException, InterruptedException {
-
// método TODO de talones que generan automáticamente
-
int
I =
0
;
-
para
(IntWritable i: iterador) {
-
suma = suma + i.get ();
-
}
-
context.write (clave, nueva IntWritable (suma));
-
}
-
}
-
empaquetar wordsCount;
-
-
-
importación
org.apache.hadoop.conf.Configuration;
-
importación
org.apache.hadoop.fs.Path;
-
importación
org.apache.hadoop.io.IntWritable;
-
importación
org.apache.hadoop.io.Text;
-
importación
org.apache.hadoop.mapreduce.Job;
-
importación
org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
-
importación
org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
-
importación
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
-
importación
org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
-
-
public
class Run {
-
-
pública estática vacíos principales (args String []) lanza la excepción
{
-
// método TODO de talones que generan automáticamente
-
Configuración Configuración = nueva configuración ();
-
Profesión Profesión = nuevo trabajo (configuración);
-
job.setJarByClass (Run.class);
-
job.setJobName ( "cuentan palabras!" );
-
-
job.setOutputKeyClass (Text.class);
-
job.setOutputValueClass (IntWritable.class);
-
-
job.setInputFormatClass (TextInputFormat.class);
-
job.setOutputFormatClass (TextOutputFormat.class);
-
-
job.setMapperClass (WordsMapper.class);
-
job.setReducerClass (WordsReduce.class);
-
-
FileInputFormat.addInputPath (trabajo, nueva trayectoria ( "hdfs: //192.168.1.111: 9000 / usuario / entrada / wc /" ));
-
FileOutputFormat.setOutputPath (trabajo, nueva trayectoria ( "hdfs: //192.168.1.111: 9000 / usuario / resultado /" ));
-
-
job.waitForCompletion ( verdadero );
-
}
-
}
Ejecutar el interior de las rutas de entrada y de salida en función de su modificado para
Este programa no tendrá que explicarlo se puede encontrar en todas partes
En primer lugar ejecutar en hadoop este programa de dos maneras
Método uno: para compilar su propio software y hadoop conectado (utilizo a MyEclipse enlace hadoop), ejecute el programa directamente. tutoriales MyEclipse estarán conectados hadoop daré un enlace para su referencia al final del artículo.
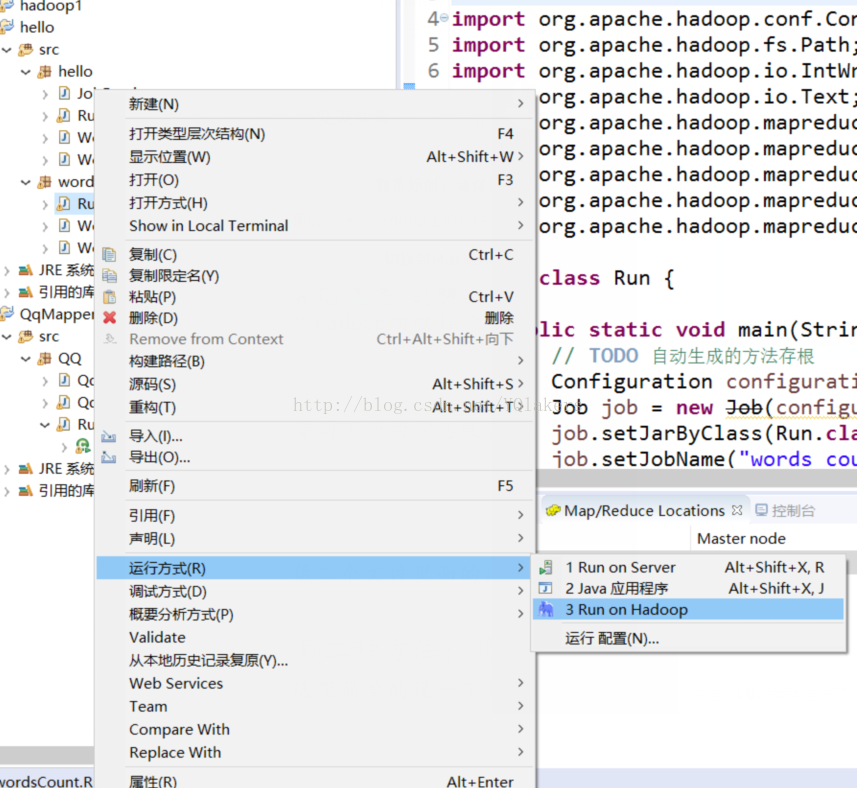
Ver el siguiente mensaje que significa que tienen éxito , entonces, entonces su salida de la plegadora, que será capaz de ver los resultados de la operación
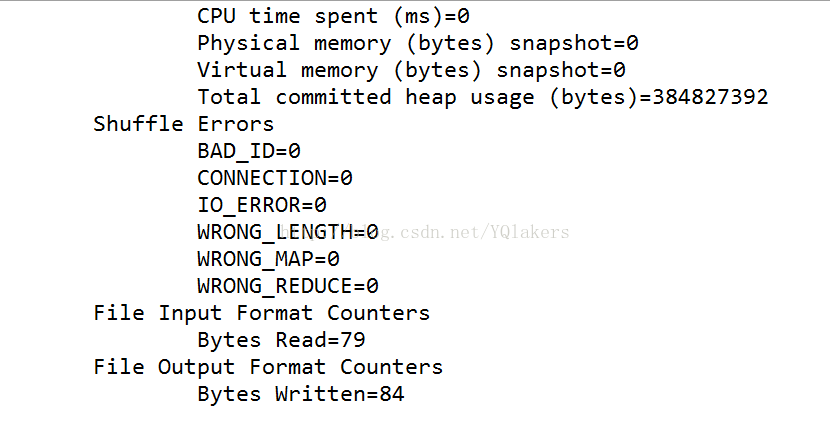
El segundo archivo que es la salida de contenido
El segundo método: la mapreduce empaquetado en un fichero JAR
Aquí un método discurso breve de los envases
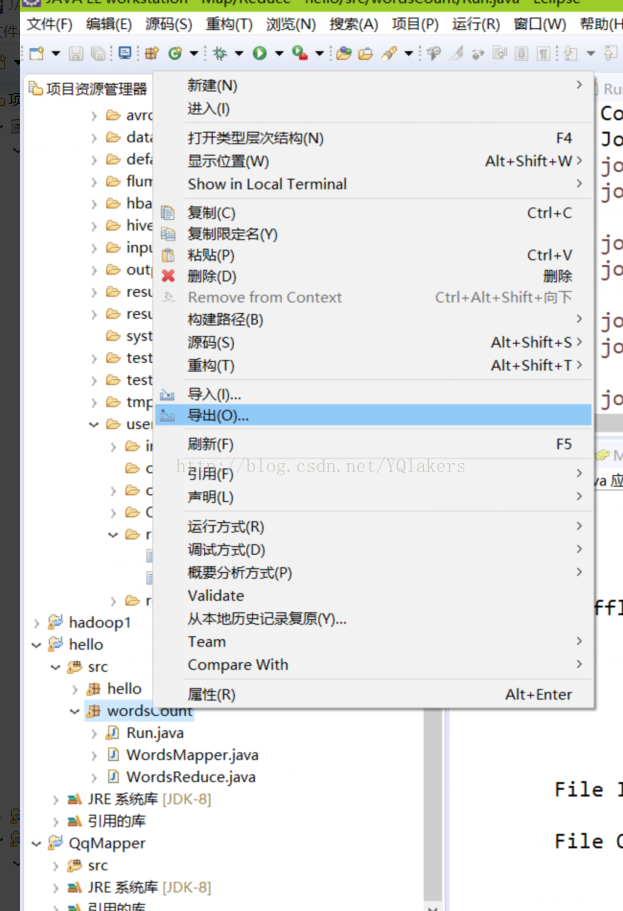
A continuación, el siguiente paso puede completarse
En los archivos jar de embalaje para instalar su máquina hadoop (mi grupo hadoop está instalado en la máquina virtual Linux) después de usar SSH pase sobre el frasco:
Hadoop archivo ejecutable en el directorio bin bajo el directorio de instalación de Hadoop, y luego hacer lo siguiente en él:

Bajo el comunicado para explicar mi concha
/home/xiaohuihui/wordscount.jar: la ubicación del archivo JAR después de la (ubicación de la máquina virtual de difusión) paquete
wordsCount / Ejecutar: El nombre del lugar de su paquete frasco principal función (función principal es Run.class) puede abrir el visor de archivo jar sabrá
También puede agregar una ruta de entrada y salida de archivos, pero que he creado después de esta declaración en mi programa
Ver la siguiente salida después de la cáscara si se ejecuta la declaración anterior, entonces felicitaciones a usted, el éxito! !
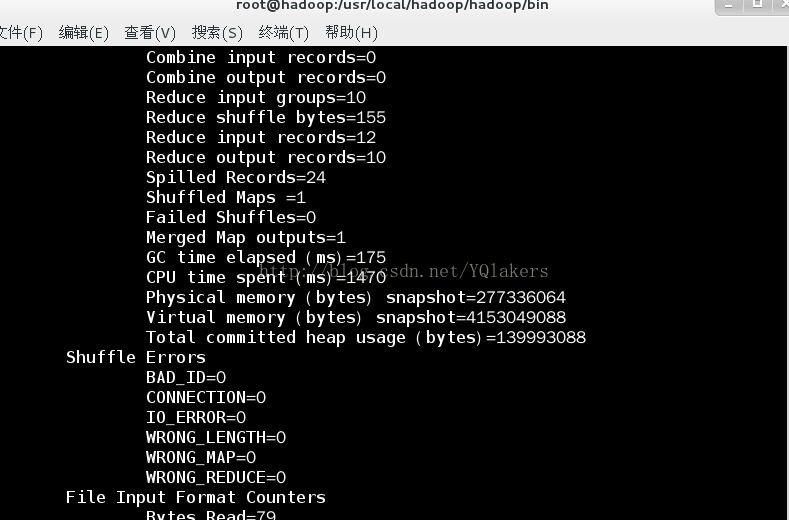
Se puede ver los resultados en su Eclipse conectados vista hadoop, también puede hdfs página para ver el sistema de archivos (localhost: 50070).
También hay un paso muy importante es, antes de ejecutar para asegurar que su hadoop ha comenzado, lo que pueda para ver si su proceso de hadoop cúmulo ha sido iniciado por JPS
Eclipse 连接 hadoop: http: //blog.csdn.net/xjavasunjava/article/details/12320045
