1 Introducción
hbase proporcionan scripts de shell convenientes y API Java y otras maneras a hbase operar, pero para que se han acostumbrado al desarrollo de las operaciones de bases de datos relacionales, hay algunos costos de aprendizaje, si puede funcionar como MySQL y así sucesivamente a través de SQL hbase operación, a continuación, en gran medida a reducir el costo de hbase. Apache Phoenix componentes para completar este requisito, el funcionario anotada como "Phoenix -nos pusieron en la parte posterior de SQL NoSQL", a través de la explicación oficial, Phoenix alto rendimiento, en relación con el hbase nativa de exploración no es mucho peor, y por similares componentes colmena, impala, etc., ha mejorado significativamente el rendimiento, detalles, lea https://phoenix.apache.org/performance.html .
sitio de Apache Phoenix Oficial: https://phoenix.apache.org/
Phoenix admite SQL declaración: https://phoenix.apache.org/language/index.html
Phoenix es compatible con los tipos de datos: https://phoenix.apache.org/language/datatypes.html
funciones Phoenix apoyado: https://phoenix.apache.org/language/functions.html
configuración de la instalación 2
2.1 Instrucciones Ambientales
Hbase utilizar dos anfitriones, nombre de host e IP son:
maestro 172.18.68.119
slave01 172.18.68.88
maestro como un nodo maestro, slave01 como un nodo esclavo, es decir, como un hbase HRegionServer.
ubicación de la instalación hbase: / home / hadoop / hbase
2.2 Descargar
Seleccionar http://www.apache.org/dyn/closer.lua/phoenix/ proporcionada en el sitio web oficial de los servidores réplica para descargar e instalar la versión correspondiente de la versión HBase. 1.3.1 uso local, por lo que el descargado Apache-Phoenix-4.11.0-HBase-1.3 / un paquete tar.gz.

2.3 Instalación de Configuración
2.3.1 carga de dominar Phoenix
SecureCRT el uso de herramientas u otra transmisión de paquetes de carga descargada nodo maestro alquitrán hbase en el clúster.
$ Cd / home / hadoop /
$ Mkdir Phoenix
$ Cd Phoenix
$ rz
$ Tar -zxvf Apache-Phoenix-4.11.0-HBase-1,3-bin.tar.gz
$ Mv apache-Phoenix-4.11.0-HBase-1.3-bin / Phoenix
2.3.2 Copia Phoenix-core-4.11.0-HBase-1.3.jar a RegionServer
El Phoenix-core-4.11.0-HBase-1.3.jar en el directorio lib cúmulo hbase hbase de todos los servidores de la región. En un entorno de prueba, amo y slave01 son tan regionserver.
$ Cd / home / hadoop / Phoenix / Phoenix
Cp $ Phoenix-core-4.11.0-HBase-1.3.jar / home / hadoop / hbase / lib copiar al maestro
$ Scp -r [email protected]: inicio / / hadoop / hbase / lib copian en slave01
2.3.3 reinicio hbase
$ Cd / home / hadoop / hbase / bin
$. / Stop-hbase.sh
$. / Start-hbase.sh
3 comandos Phoenix uso de la línea
3.1 entrar en la línea de comandos
$ Cd / hadoop / Phoenix / directorio de inicio / / bin en el cubo de la Phoenix
$. / Sqlline.py un maestro del maestro es el nombre de host del nodo en el Zookeeper
3.2 sqlline.py ejecutar secuencia de comandos SQL
Puede utilizar el archivo de secuencia de comandos SQL sqlline.py, de la siguiente manera:
$ Cd / home / hadoop / Phoenix / Phoenix
$ Bin / sqlline.py masterexamples / STOCK_SYMBOL.sql
STOCK_SYMBOL.sql documento dice lo siguiente:
|
3.3 psql.py ejecutar secuencia de comandos SQL
archivo de datos CSV puede ser cargado por el guión psql.py en el directorio bin contiene el fénix o realizar secuencia de comandos SQL, de la siguiente manera:
$ Cd / home / hadoop / Phoenix / Phoenix
$bin/psql.py master ../examples/WEB_STAT.sql ../examples/WEB_STAT.csv ../examples/WEB_STAT_QUERIES.sql
其中WEB_STAT.sql、WEB_STAT.csv、WEB_STAT_ QUERIES.sql是phoenix提供的samples下的文件,文件内容如下:
WEB_STAT.sql 为创建表的sql脚本文件
|
WEB_STAT.csv 为数据文件
|
WEB_STAT_ QUERIES.sql为查询脚本文件
|
3.4 phoenix表操作
3.4.1 创建表
CREATE TABLE IF NOT EXISTS us_population (
stateCHAR(2) NOT NULL,
cityVARCHAR NOT NULL,
populationBIGINT
CONSTRAINTmy_pk PRIMARY KEY (state, city));
在phoenix中,默认情况下,表名等会自动转换为大写,若要小写,使用双引号,如"us_population"。
3.4.2 显示所有表
!table或
!tables
3.4.3 插入记录
upsert into us_population values('NY','NewYork',8143197);
3.4.4 查询记录
select * from us_population ;
select * from us_population wherestate='NY';
3.4.5 删除记录
delete from us_population wherestate='NY';
3.4.6 删除表
drop table us_population;
3.4.7 退出命令行
!quit
具体语法参照官网
https://phoenix.apache.org/language/index.html#upsert_select
3.5 phoenix表映射
默认情况下,直接在hbase中创建的表,通过phoenix是查看不到的,如图1和图2,US_POPULATION是在phoenix中直接创建的,而test是在hbase中直接创建的,默认情况下,在phoenix中是查看不到test的。
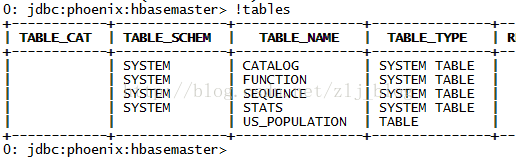
图1 phoenix命令行中查看所有表

图2 hbase命令行中查看所有表
如果需要在phoenix中操作直接在hbase中创建的表,则需要在phoenix中进行表的映射。映射方式有两种:视图映射和表映射。
hbase 中test的表结构如下,两个列簇name、company.
Rowkey |
name |
company |
||
empid |
firstname |
lastname |
name |
address |
3.5.1 hbase命令行中创建表
$ cd /home/hadoop/hbase/bin
$ ./hbase shell 进入hbase命令行
create 'test','name','company' 创建表,如下图
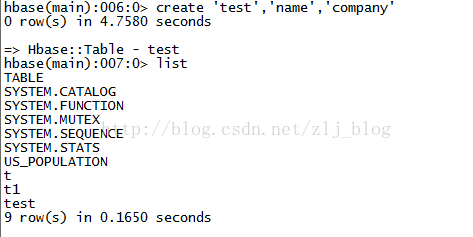
下面的视图映射和表映射均基于该表。
3.5.2 视图映射
Phoenix创建的视图是只读的,所以只能用来做查询,无法通过视图对源数据进行修改等操作。而且相比于直接创建映射表,视图的查询效率会低,原因是:创建映射表的时候,Phoenix会在表中创建一些空的键值对,这些空键值对的存在可以用来提高查询效率。
1)创建视图
create view"test"(empid varchar primarykey,"name"."firstname" varchar,"name"."lastname"varchar,"company"."name" varchar,"company"."address"varchar);
2)删除视图
drop view "test";
3.5.3 表映射
使用Apache Phoenix创建对HBase的表映射,有两种方法:
1) 当HBase中已经存在表时,可以以类似创建视图的方式创建关联表,只需要将create view改为create table即可。
2)当HBase中不存在表时,可以直接使用create table指令创建需要的表,并且在创建指令中可以根据需要对HBase表结构进行显示的说明。
第1)种情况下,如在之前的基础上已经存在了test表,则表映射的语句如下:
create table "test"(empid varchar primarykey,"name"."firstname"varchar,"name"."lastname"varchar,"company"."name" varchar,"company"."address"varchar);
第2)种情况下,直接使用与第1)种情况一样的create table语句进行创建即可,这样系统将会自动在Phoenix和HBase中创建person_infomation的表,并会根据指令内的参数对表结构进行初始化。
使用create table创建的关联表,如果对表进行了修改,源数据也会改变,同时如果关联表被删除,源表也会被删除。但是视图就不会,如果删除视图,源数据不会发生改变。
4 SQuirrel使用
如果希望通过客户端以图形化的界面操作Phoenix的话,可以下载并安装SQuirrel。
SQuirrel SQL Client是一个用Java写的数据库客户端,可以通过一个统一的用户界面来操作MySQL 、PostgreSQL 、MSSQL、 Oracle等任何支持JDBC访问的数据库。使用起来非常方便。
SQuirrel下载页面:http://squirrel-sql.sourceforge.net/#installation。
SQuirrel的安装步骤(参考https://phoenix.apache.org/installation.html):
1)移除SQuirrel的lib文件夹下的phoenix-[oldversion]-client.jar(如果有的话),然后拷贝phoenix-[newversion]-client.jar到SQuirrel的lib文件夹下,phoenix-[newversion]-client.jar须与欲连接的hbase的lib下的phoenix版本一致。
2)windows下,运行squirrel-sql.bat启动SQuirrel,在启动界面下,切换到Drivers选项卡,点击+号添加新的驱动。
3)在添加驱动对话框中,设置name为Phoenix,设置Example URL为 jdbc:phoenix:localhost,其中的localhost为hbase使用的Zookeeper主机名。
4)设置Class Name文本框的内容为 “org.apache.phoenix.jdbc.PhoenixDriver”, 如图4.1,然后点击“OK”关闭。
5)切换到Aliases选项卡,点击+新建一个alias。
6)在对话框中,name:任何名称,Driver:选择phoenix,username、password可省略,或者填任意值均可。
7)URL的内容为:jdbc:phoenix: zookeeperquorum server,例如,要连接本机的hbase,URL为:jdbc:phoenix:localhost,如图4.2。
8)点击Test,在新对话框中选择connect,如果一切设置正确的话,应该连接成功,然后点击OK关闭对话框。
9)双击新建的phoenix alias,点击connect,然后就可以通过phoenix的sql语句操作hbase了,如图4.3。
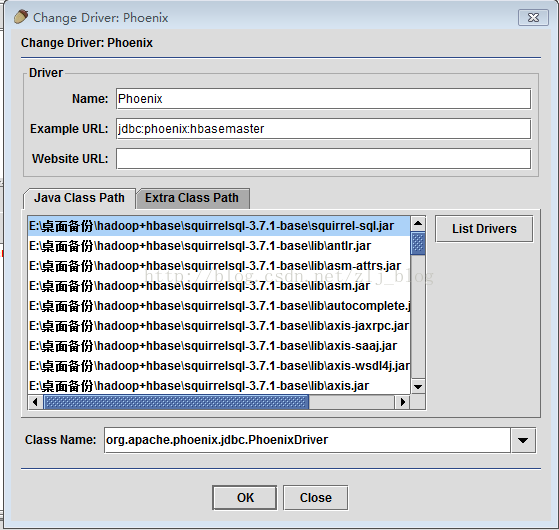
图4.1 新建Driver

图4.2 新建Alias
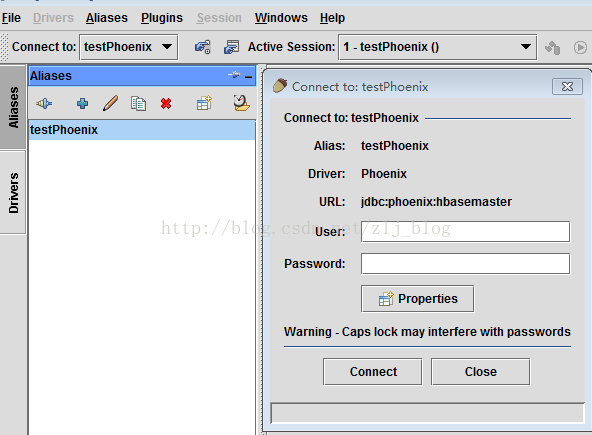
图 4.3 建立连接
为防止原文丢失找不到,特转载自:https://blog.csdn.net/zlj_blog/article/details/76173844
