P537 ~ 578.
contorno
En este capítulo se describen los métodos y las ideas mucho expansión del sistema, no se limita a la base de datos.
En primer lugar, tratar de hacer una optimización independiente (optimización de SQL o hardware), debido a que la expansión traerá la complejidad de la actualización de la máquina. En segundo lugar, considere la lectura y la escritura por separado , es decir, un multi-estrategia maestra preparada, escribe el maestro a la base de datos, leído por la biblioteca. otra vez, considerar el segmento de datos, los datos en diferentes tipos de fragmentación de memoria.
Planificación de la capacidad
Preparación para la expansión, el pico planificar, calcular cómo se requieren muchos servidores.
Stand-alone expansión
- La optimización de SQL, añadir un índice.
- hardware mejorado
optimización independiente hay un límite
Sub-bibliotecas fragmentación
- La división de negocios relativamente independiente en diferentes bibliotecas
- Los datos de acuerdo con diferentes tipos de cortar en rodajas
Genera un identificador único global
- Generada mediante el uso de la auto-energizar ID Redis
- Uso ID copo de nieve (copo de nieve), se basan en el reloj del sistema
- Uso GUID, no se recomienda, GUID largo y desordenado, inserto bajo rendimiento puede ser considerado GUID ordenada.
instancias de MySQL más de una máquina
A veces, un ejemplo de una máquina no puede reproducir todo el rendimiento, la acumulación de varias instancias
El uso de MySQL Cluster
Como NDB Cluster, Percona XtraDB Cluster, Clustrix etc.
uso NoSQL
Un simple parte de la estructura de datos, los requisitos de alto rendimiento de la tarea a ser implementado en NoSQL
archivo de datos
Los datos inactivos archivar limpieza
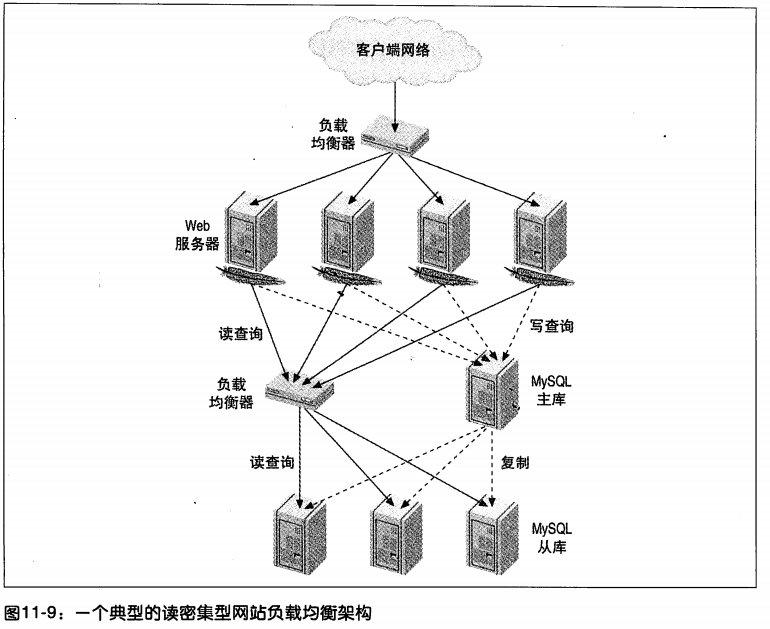
Equilibrio de carga
Como el uso de Nginx equilibrador de carga