1. Gradiente
-
Debemos observar la magnitud de los cambios de datos, entonces apareció la derivada, pero algunas funciones contiene una serie de variables, existe este derivado para cada variable, es decir, las derivadas parciales. (Ilustración)
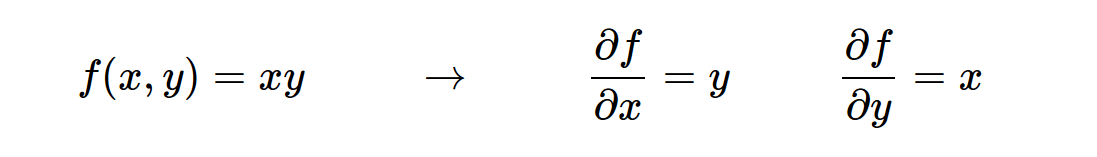
-
vector del gradiente es derivada parcial, y puede estar en la forma de vectores, almacena una pluralidad de derivadas parciales de las variables, junto conocido como gradiente. (Ilustración)

-
Por alguna función especial gradiente, nota, por ejemplo
Max, es uno de datos de gran tamaño para la derivada parcial es 1, y luego multiplicando el valor volviendo, si una pequeña, multiplicado por las derivadas parciales de la posterior 0 valor, es el resultado natural de un 0.
2. regla de la cadena
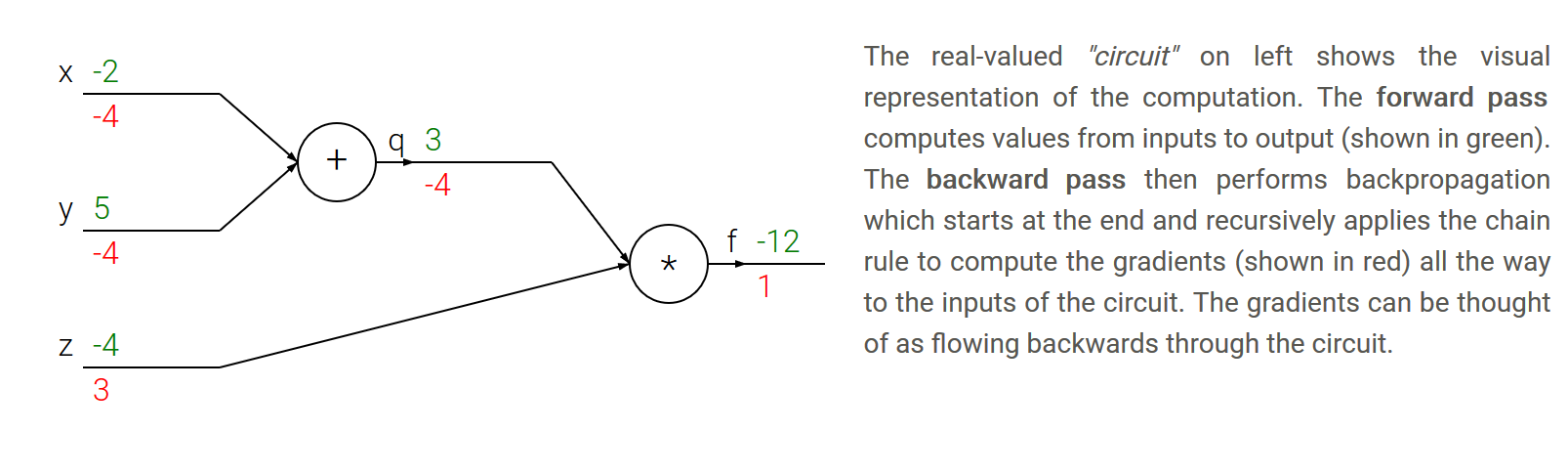
- regla de la cadena: regla de la cadena nos dice que la manera correcta de poner juntos estos gradientes expresiones de multiplicación (ilustración)
3. retropropagación
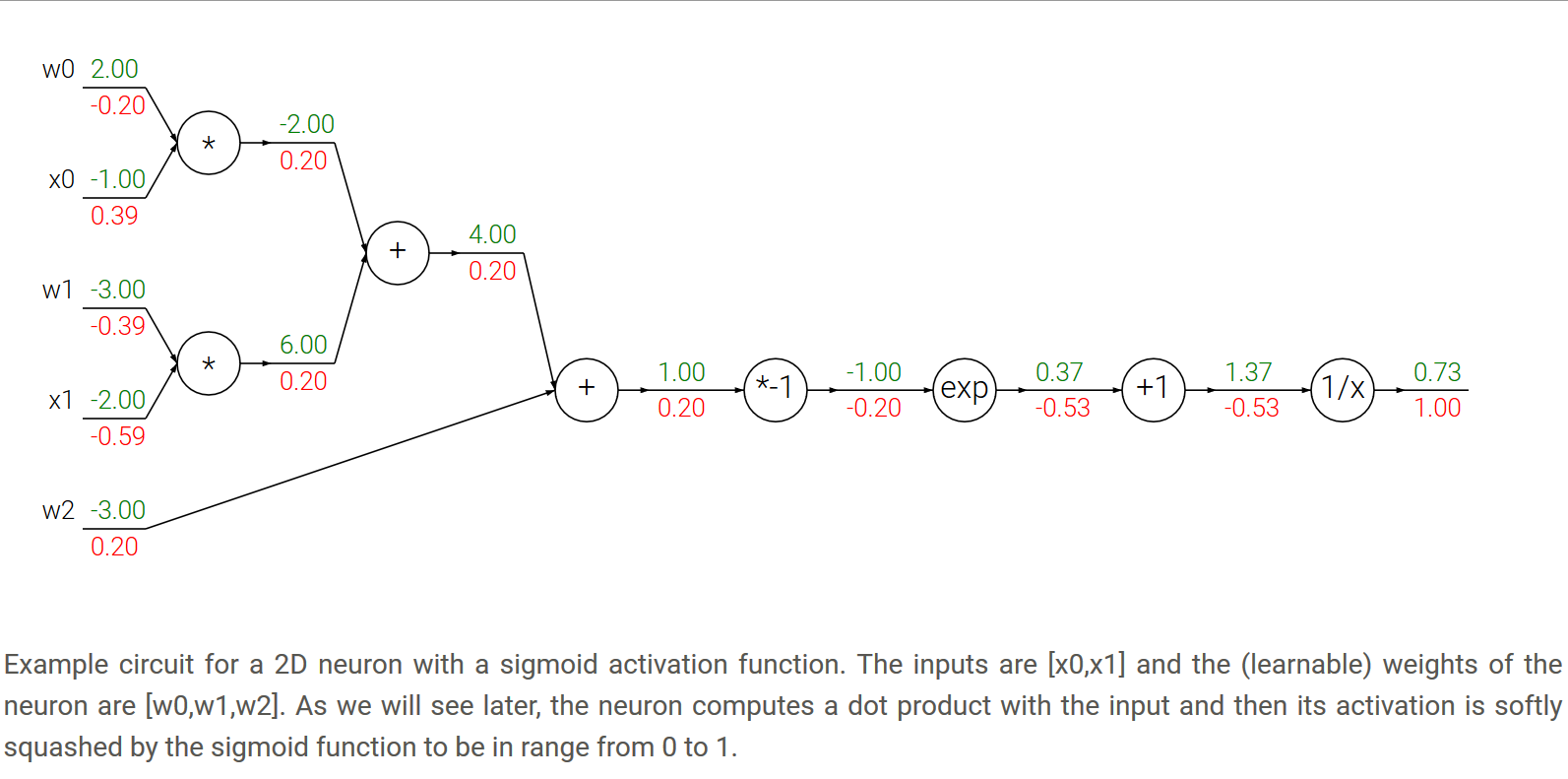
- Sencillo, la propagación del frente En primer lugar, a continuación, se puede propagar inversa, el primer paso es un gradiente de recibida llegó por detrás, el segundo paso es un gradiente en los nodos de computación a sí mismos, multiplicando ambos la derivada parcial se obtiene en el nodo actual.
- Una ilustración ejemplo para explicar.
4. Patrones en el flujo hacia atrás
- añadir puerta: sumador trasero llegó valor de gradiente, el valor actual se multiplica directamente por 1, y los resultados, es decir, después de la tecla para aumentar, el valor de volver a partir del valor de la puerta pase sin cambios.
- puerta max: Este es el valor bastante especial, gradiente a uno de los nodos de variable 1, gradiente 0 uno más pequeño, el resultado final se multiplica por el valor de volver, para dar un gradiente de pase hacia adelante final, es decir, el gradiente del nodo.
- puerta multiplican: Esto es más fácil de entender, el gradiente del nodo actual son como la función normal de las derivadas parciales de encontrar, y luego multiplicando el valor de volver, respectivamente, dan respectivo gradiente final.
5. Los gradientes de operaciones vectorizadas
- simple caso
# forward pass
W = np.random.randn(5, 10)
X = np.random.randn(10, 3)
D = W.dot(X)
# now suppose we had the gradient on D from above in the circuit
dD = np.random.randn(*D.shape) # same shape as D
dW = dD.dot(X.T) #.T gives the transpose of the matrix
dX = W.T.dot(dD)