SparkSql la función de ventana
Se refiere a una función de ventana de la llamada es un procesamiento de datos multi-línea y el retorno a las columnas columnas normales de proceso de polimerización;
sintaxis detallada:窗口函数() over([partition by 分区 order by 排序规则 ...])
función de ventana tiene tres categorías:
- función de ventana polimerizable
- función de ventana Rango
- función de ventana de análisis de datos
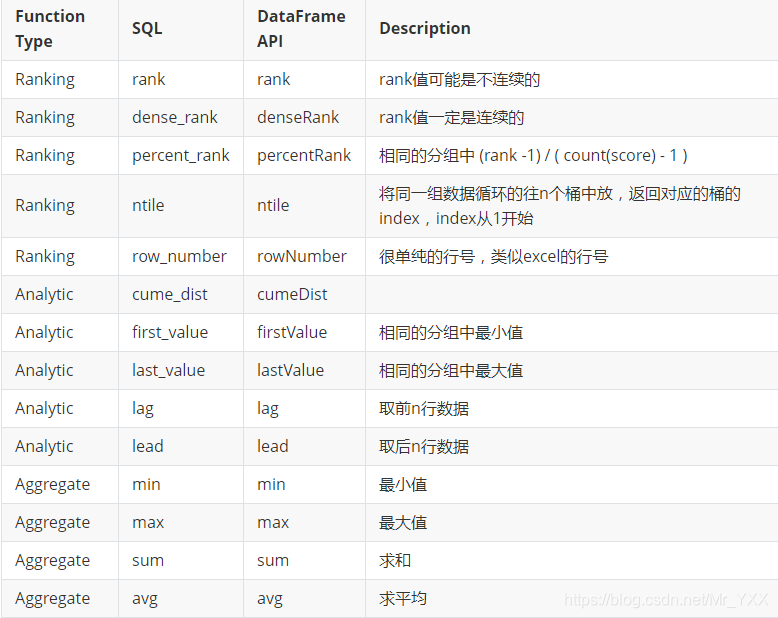
contar (...) sobre (partición por ... por fin ...) - el número total del paquete de solicitud. SUM (...)
sobre (Orden de reparto por ... ...) - y el paquete de petición. max (...)
sobre (Orden de reparto por ... ...) - valor máximo del paquete de solicitud. min (...)
sobre (Orden de reparto por ... ...) - después de que el paquete de solicitud mínimo. AVG (...)
sobre (Orden de reparto por ... ...) - valor medio del paquete de solicitud. Rango ()
sobre (Orden de reparto por ... ...) --rank valor puede ser discontinua. DENSE_RANK ()
sobre (Orden de reparto por ... ...) es el valor --rank continua. FIRST_VALUE (...)
sobre (Orden de reparto por ... ...) - encuentra el primer valor dentro del paquete. LAST_VALUE (...)
sobre (Orden de reparto por ... ...) - encontrar el último valor dentro del paquete. GAL ()
sobre (Orden de reparto por ... ...) - Retire las primeras n filas de datos. El plomo ()
sobre (Orden de reparto por ... ...) - Datos de n-línea se extrae. RATIO_TO_REPORT ()
sobre (partición por ... por ... la Orden) --Ratio_to_report ()
Molécula está entre paréntesis, más de () es el denominador en paréntesis. PERCENT_RANK () sobre (partición por ... por la Orden
...) -
viñetas de casos de cada aplicación de función ventana
- visitas rango) página de solicitud (un día antes de la página 10 por usuario
//测试数据
val rdd = spark.sparkContext.makeRDD(
List(
("2018-01-01", 1, "www.baidu.com", "10:01"),
("2018-01-01", 2, "www.baidu.com", "10:01"),
("2018-01-01", 1, "www.sina.com", "10:01"),
("2018-01-01", 3, "www.baidu.com", "10:01"),
("2018-01-01", 3, "www.baidu.com", "10:01"),
("2018-01-01", 1, "www.sina.com", "10:01")
))
Esquema de Solución
1. El número de veces que cada usuario para acceder a diferentes páginas
2. orden descendente para cada página del usuario hace clic, y la función de ventana utilizada en la función de clasificación
3. El número de veces obtenidos para cada usuario para acceder a las primeras páginas diez donde rango <n
Método uno: una llamada al método para lograr
import sp.implicits._
//导入窗口函数的支持
import org.apache.spark.sql.functions._
rdd
.toDF("time","uid","path","ztime")
.groupBy("uid","path") //根据用户 和访问的网址 分组
.count() //分组之后的聚合操作 通知每个用户访问每个网址的次数
//添加列 列名 rank 窗口函数rank():rank值可能是不连续的 over 创建的窗口
.withColumn("rank",rank() over(Window.partitionBy("uid").orderBy($"count" desc)))
.where("rank<=10") //访问页面次数前十 参数为条件表达式
.show()
+---+--------------+-----+----+
|uid| path|count|rank|
+---+--------------+-----+----+
| 1|www.hao123.com| 2| 1|
| 1| www.baidu.com| 1| 2| rank()(rank值可能是不连续的) 并列第二了 1用户再访问别的网址 rank值为4 1 2 2 4
| 1| www.sina.com| 1| 2| dense_rank(rank值一定是连续的) 1用户再访问别的网址 rank值为3 1 2 2 3
| 3| www.baidu.com| 1| 1|
| 3| www.sina.com| 1| 1|
| 2| www.baidu.com| 1| 1|
+---+--------------+-----+----+
Método dos: SQL puro lograr
//导入隐式转换 作用:将rdd转换成df 或 ds
import sp.implicits._
rdd
.toDF("time","uid","path","ztime")
//创建临时视图(表):只能在创建它的spark session中使用
.createOrReplaceTempView("t_path")
spark
.sql(
"""
|select
| *
|from
| (
| select
| uid,
| path,
| path_count,
| rank()
| over(partition by uid order by path_count desc) as rank
| from
| (
| select
| uid,
| path,
| count(path) as path_count
| from
| t_path
| group by
| uid,path
| )
| )
|where
| rank < 10
|""".stripMargin)
.show()
- AggregateOnWindow obtener sector salario medio de corriente básico, donde la información de usuario
//测试数据
val rdd = sp.sparkContext.makeRDD(
List(
(1,"zs",true,1,15000),
(2,"ls",false,2,18000),
(3,"ww",false,2,14000),
(4,"zl",false,1,18000),
(5,"win7",false,1,16000)
))
Método uno: una llamada al método para lograr
//导入隐式转换 作用:将RDD转换成DF
import sp.implicits._
//导入窗口函数的支持
import org.apache.spark.sql.functions._
rdd
.toDF("id","name","sex","dept","salary")
.withColumn("avg_Salary",avg("salary") over(Window.partitionBy("dept")
.orderBy($"salary" desc)
//窗口内的可视范围 lang的最大值和最小值
.rowsBetween(Window.unboundedPreceding,Window.unboundedFollowing)))
.show()
Segundo método :( lograr SQL puro)
spark
.sql(
"""
| select
| id,
| name,
| sex,
| dept,
| salary,
| avg(salary) over(partition by dept rows between unbounded preceding and unbounded following) as avg_salary
| from
| t_user
|""".stripMargin)
.show()
el uso ventana RowsBetween:
案例
A表里面有三笔记录 字段是 ID start_date end_date
数据是:
1 2018-02-03 2019-02-03;
2 2019-02-04 2020-03-04;
3 2018-08-04 2019-03-04;
根据已知的三条记录用sql写出结果为:
A 2018-02-03 2018-08-04;
B 2018-08-04 2019-02-03;
C 2019-02-03 2019-02-04;
D 2019-02-04 2019-03-04;
E 2019-03-04 2020-03-04;
(提示:请把问题看做是一个判断区间内有零散时间点的重新建立时间区间连续以及断点的问题)
Ideas de resolución de problemas:
- Desmontaje de datos en tiempo
- fecha ascendente
- Función de ventana (intervalos de tiempo sucesivos)
package method
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.Window
object SparkSQLWordCountOnWindowFunction2 {
def main(args: Array[String]): Unit = {
//1. 构建Spark SQL中核心对象SparkSession
val spark = SparkSession.builder().appName("wordcount").master("local[*]").getOrCreate()
import spark.implicits._
val rdd = spark
.sparkContext
.makeRDD(List(
(1, "2018-02-03", "2019-02-03"),
(2, "2019-02-04", "2020-03-04"),
(3, "2018-08-04", "2019-03-04")
))
val df = rdd
.flatMap(t3 => {
Array[String](t3._2, t3._3)
})
.toDF("value")
import org.apache.spark.sql.functions._
val w1 = Window.orderBy($"value" asc).rowsBetween(0,1)
df
.withColumn("next", max("value") over (w1))
.show()
spark.stop()
}
}
datos válidos van dentro de la ventana
de valor = 0 en la fila actual
** Valor = n en la línea actual n líneas **
valor en la línea actual = -n n líneas
resumen:
- la sintaxis SQL chispa es similar a la pura sintaxis SQL de base de datos DB
GlobalTempViewlvisión global yTempViewdiferencias
- visión global (global_temp almacena en la base de datos, que puede provocar la sesión a través de múltiples sesiones)
- vistas temporales (almacenados en la base de datos por defecto, sólo puede crear los usos de sesión sesión de chispa)
