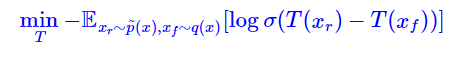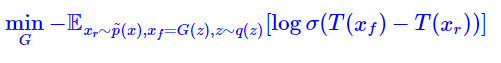Directorio artículo
Una variedad de divergencia
entropía
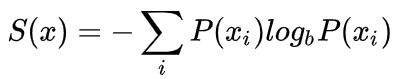
La cantidad de información realizado por la distribución P
/
utilizando el número mínimo de bytes requeridos para codificar la distribución basada en P de la P muestra
entropía cruzada
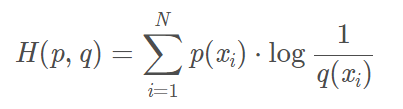
P distribución de la información desde la perspectiva de vista de la distribución de Q
/
muestra de uso basado en la distribución P Q "longitud de código promedio" requerido para codificar el deseado
por qué la pérdida de entropía cruzada puede ser usado para medir? Referencia
de formación de distribución de muestras entropía P es constante, igual a una minimización de la entropía transversal mínima de KL divergencia, es decir, la cantidad de información con la distribución de corriente para adaptarse a la distribución de la pérdida de datos de entrenamiento.
marea KL
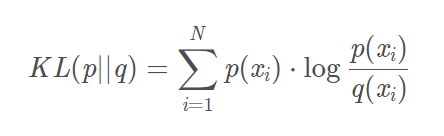
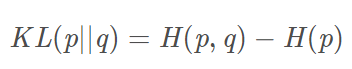
asimetría no negativo
distribución Q usando cantidad aproximada de pérdida de información cuando la distribución de la P
/
basado codifica Q "longitud adicional necesaria para el código" distribución de la muestra P.
JS divergencia
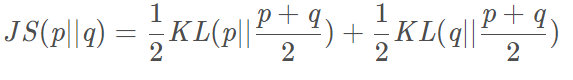
Cuanto más similares más pequeña es la simetría entre 0-1
principio GAN
La pérdida del discriminador GAN inicial definido, podemos obtener la forma óptima del discriminador; en el discriminador óptimo, puede definir el generador de GAN original en una pérdida equivalente minimizar la distribución real
Y la generación distribuida
divergencia JS entre.
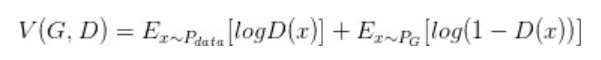
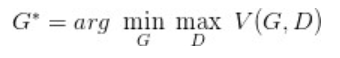
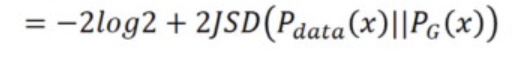
Fijo G, D óptima se determina y, a continuación sustituyendo DV max (G, D), para dar la divergencia JS, mínimo -2log2
minimizar la fórmula anterior, es decir, JS divergencia optimizado, entonces debe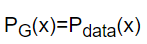
problemas de formación
- G, Entrenamiento D el uno del otro
después de la actualización G, JS divergencia se corresponde con una más pequeña, pero también afecta a la V (G, D) curva, y que la siguiente MAXV (G, D) puede llegar a ser grande, y que es D la capacidad para adaptarse tanto la distribución peor
actualizado solución varias veces D, G actualiza - JS resolución de problemas divergencia más-ruido
cuadro se hace de bajo dimensional vector para generar alta dimensión, ya y Casi imposible tener un solapamiento no despreciable, por lo que no importa lo lejos que son constantes JS divergencia , que finalmente llevan al generador de gradiente de (aproximadamente) es 0, el gradiente desaparece. - Mejorados pérdida generador conduce a la inestabilidad y el colapso escasez diversidad modo
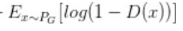
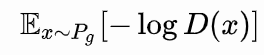
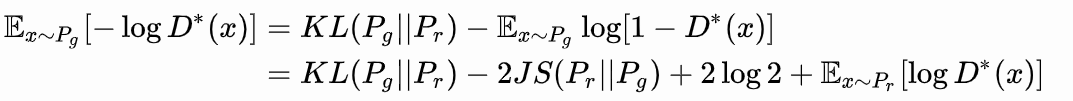
iguales para minimizar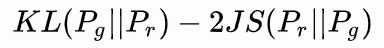
sino también minimizar KL, sino también para maximizar la inestabilidad JS gradiente
KL problemas anteriores: asimétrica
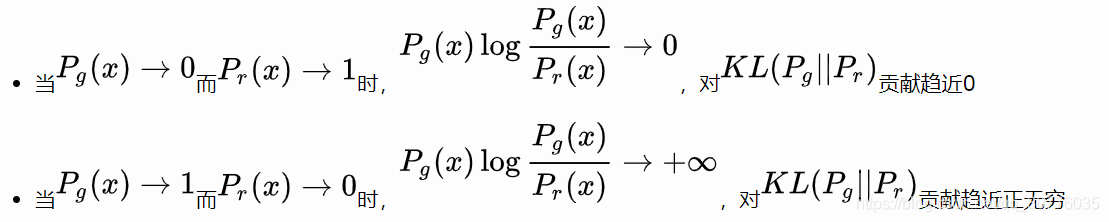
primera generación es no existe ningún conjunto de datos de la muestra real, el segundo es el error generado no hay datos reales en la muestra, entonces yo preferiría no generar muestra de la diversidad, no prueba y error.
Wgan
Tierra-Mover (EM) distancia

En todo posible distribución conjunta, en busca de muestras reales y generar la distancia de muestra deseado, teniendo el deseado límite inferior.
Es decir, la distribución óptima de las articulaciones, Pr trasladó al consumo mínimo de Pg.
Wasserstein en comparación KL divergencia distancia, la superioridad de JS divergencia es que, incluso si las dos distribuciones no se superponen, siendo la distancia para reflejar Wasserstein distancia de la misma.
Wgan
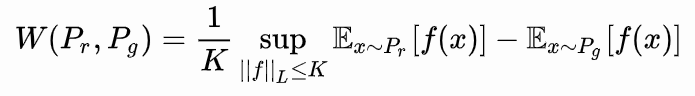
muestras reales tomadas para f (x), para generar una muestra se toma -f (x) del sector, existen restricciones en el parámetro de gradiente w.
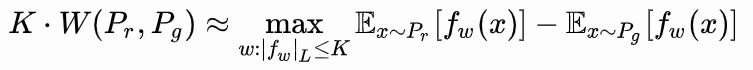
Laplace continua
La diferencia entre el GAN originales:
1. función de pérdida
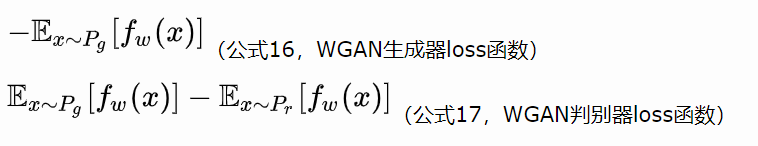
-
parámetro Laplace trunca a condiciones conocer
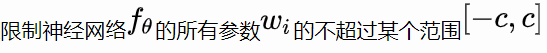
-
Extracción del discriminador sigmoide
debido a que el original D (x) es 0, el valor de ajuste, y donde el accesorio es Wassertain distancia discriminador.
GAN relativistas