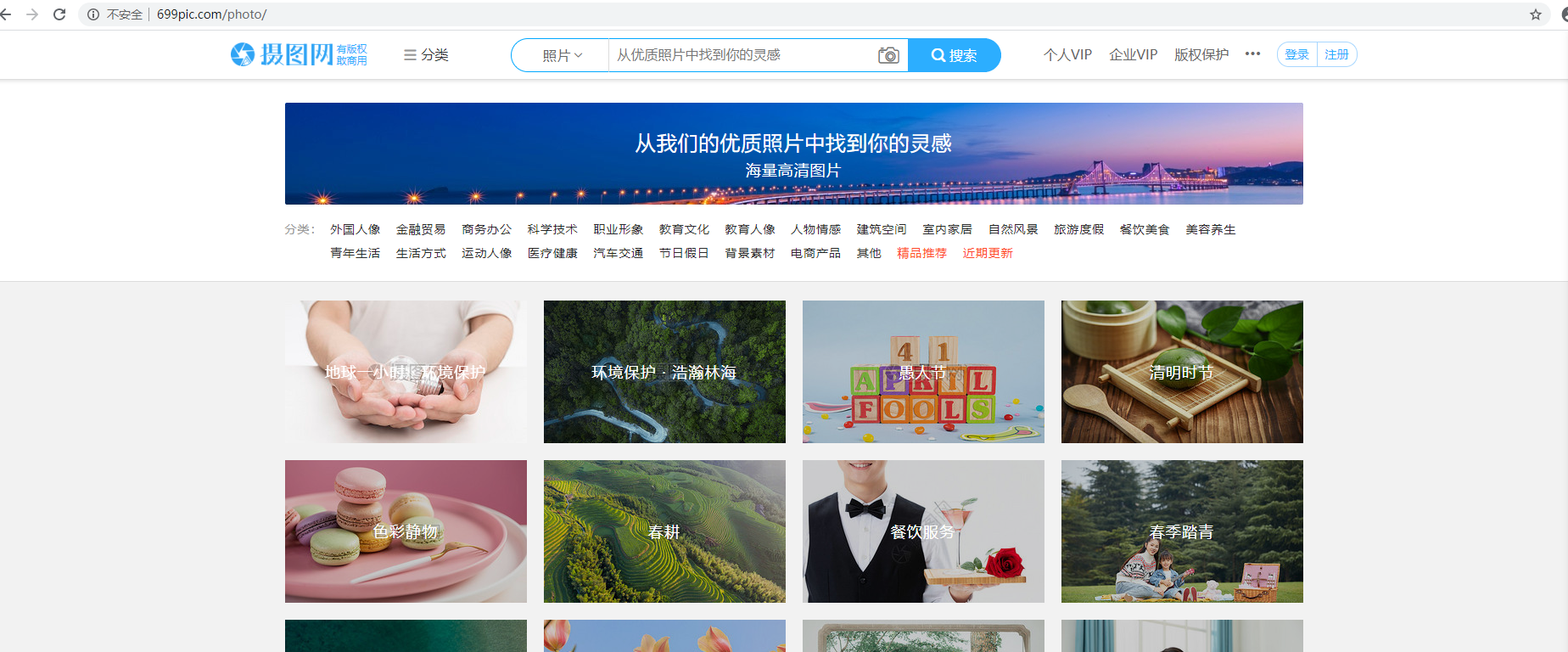
Aquí dar un simple Liezi, para capturar la imagen de título a casa!

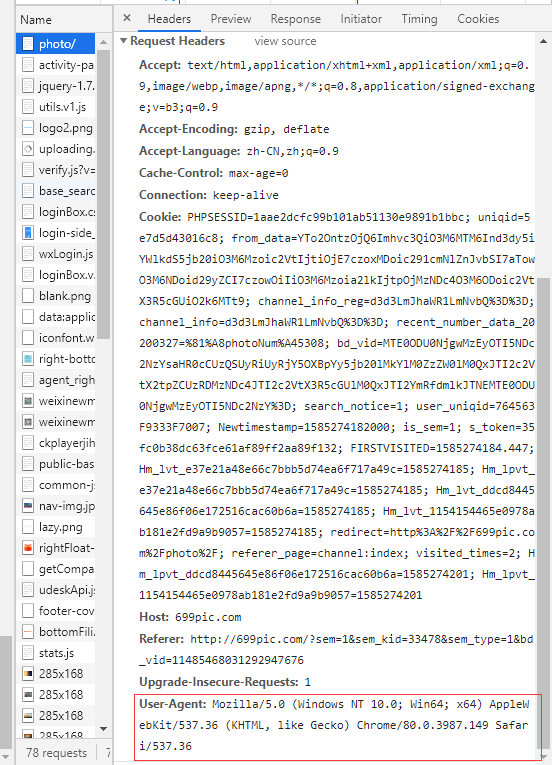
El primer paso es la necesidad de hacer primero reptil camuflaje UA, UA inicia una solicitud al sitio haciéndose pasar disfrazado como un navegador, hay una encabezados de parámetros cuando la solicitud de petición de envío, podemos poner este parámetro en User-Agent cabeceras de este parámetro
cabeceras = { ' User-Agent ' : ' Mozilla / 5.0 (Windows NT 10,0; Win64; x64) AppleWebKit / 537.36 (KHTML, como Gecko) Chrome / 80.0.3987.149 Safari / 537.36 ' }
Puede encontrar este parámetro en el navegador herramienta de captura de paquetes
Bueno, entonces podemos enviar una solicitud de una página para obtener las páginas de datos!
Importación solicitudes de LXML importación eTree cabeceras = { ' del Agente User-- ' : ' Mozilla / 5.0 (Windows NT 10,0; Win64; x64-) AppleWebKit / 537.36 (KHTML, como el Gecko) Chrome / 80.0.3987.149 Safari / 537.36 ' } URL = ' http://699pic.com/photo/ ' Respuesta = requests.get (URL = URL, cabeceras = cabeceras) .text página de datos # adquiridos en este momento la
Lo siguiente que necesitamos para llegar a la página de destino etree difusión generada
árbol = etree.HTML (respuesta)
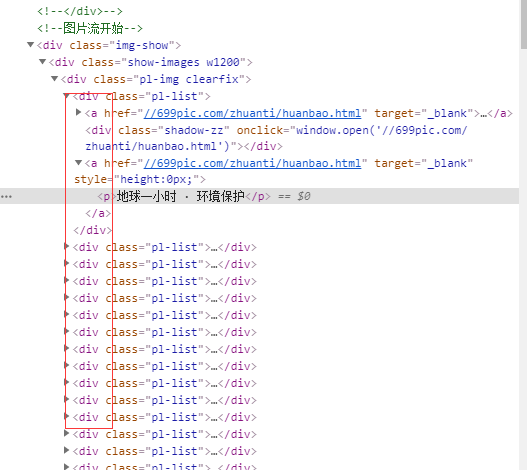
A partir de este gráfico podemos ver que esto es una fotografía de cada div y estamos en la misma div, el título está en el interior de cada uno de etiquetas div p, div entonces podemos poner esto en un solo lugar, la circulación eran conseguirlo?
El resultado es obvio, por supuesto que puede
div_list = tree.xpath ( ' // div / div / div / div [@ class = "img-espectáculo"] ' ) print (div_list) para div en div_list: Nombre = div.xpath ( ' ./a[2] / p / texto () ' ) [0] de impresión (nombre)
El primero de ellos es una colección div_list div imagen, almacenada en la impresión mirado a una lista de

Esta lista es entonces reciclado, se puede sacar de los elementos correspondientes en el valor p lista.
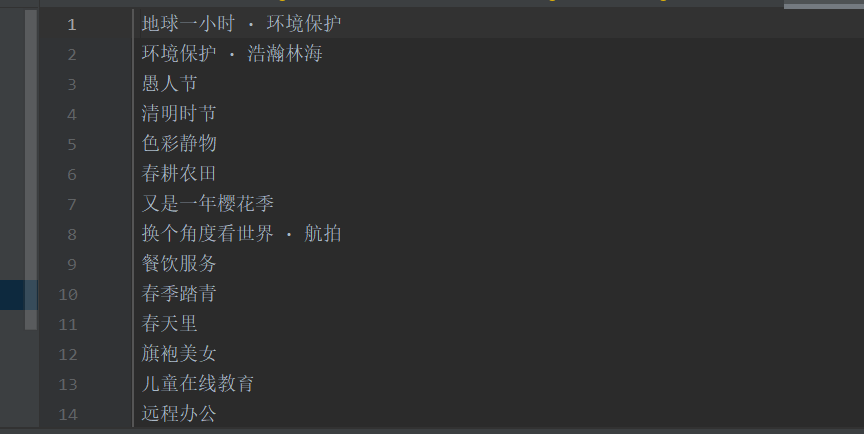
El efecto neto:
Todo el código se muestra a continuación:
importación solicitudes de lxml importación eTree cabeceras = { ' User-Agent ' : ' Mozilla / 5.0 (Windows NT 10,0; Win64; 64) AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 80.0.3987.149 Safari / 537.36 ' } url = ' http://699pic.com/photo/ ' respuesta = requests.get (url = url, cabeceras = cabeceras) .text árbol = etree.HTML (respuesta) div_list = tree.xpath ( ' // div [@ class =" img-espectáculo "] / div / div / div ' ) print (div_list) f= Abierto ( ' name.txt ' , ' w ' , que codifica = ' utf-8 ' ) para div en div_list: nombre = div.xpath ( ' ./a [2] / p / texto () ' ) [0] f.write (nombre + ' \ n ' )