1. El concepto de agrupación
1.1 ¿Qué es un cluster
同一个业务,部署在多个服务器上(不同的服务器运行同样的代码,做同一件事情)。
1.2. ¿Por qué cúmulo
- Prevent punto único de fallo
- Concurrente alta procesamiento - demasiadas peticiones el servidor no puede manejar
- El procesamiento de grandes cantidades de datos (problemas en expansión) - demasiada memoria de un servidor no puede manejar los datos
- mejorar la eficiencia
1.3. Las características y capacidades del clúster
Las agrupaciones presentan dos de las siguientes características principales:
- Escalabilidad - rendimiento del servicio de clúster no se limita a una sola entidad, la nueva entidad de servicio puede añadirse dinámicamente a la agrupación, mejorando así el rendimiento de la agrupación. Agregar servidor de forma dinámica
- Alta disponibilidad - Servicio de Cluster redundante entidad por el cliente se reunió del fácilmente fuera de servicio de alerta. En un clúster, el mismo servicio puede ser proporcionado por múltiples entidades de servicio. Si una entidad de servicio falla, otra entidad de servicio se hará cargo de la falla entidad de servicio. Las agrupaciones presentan el servicio de una entidad mal para restaurar la función a otra entidad de servicio de disponibilidad de las aplicaciones realza
al acceder al servidor colgó, el clúster puede ser utilizado normalmente tienen la capacidad de encontrar la cantidad de servidores continúan proporcionando servidor.
Para las funciones de escalabilidad y alta disponibilidad, dos grupos deben tener las siguientes características:
Equilibrio de carga - Balanceo de carga puede una distribución más equilibrada de tareas con la informática y recursos de la red en un entorno agrupado.
Recuperación de Errores - por alguna razón, los recursos para llevar a cabo una tarea falla, los otros recursos de servicio para realizar la misma tarea entidad luego completar la tarea. Esto no puede trabajar debido a los recursos de una entidad a otra entidad recursos para completar la tarea de continuar proceso transparente que se llama recuperación de errores.
1.4. Similitudes y diferencias y clusters distribuidos?
El mismo punto:
Son procesamiento altamente concurrente, y requieren múltiples servidores juntos. Al mismo tiempo hay generalmente distribuidos y agrupados en un solo sistema.
diferencias:
Distribuidos en diferentes servidores manejar diferentes negocios. Y cuando el mismo negocio de procesamiento de clúster.
Figura distribuida: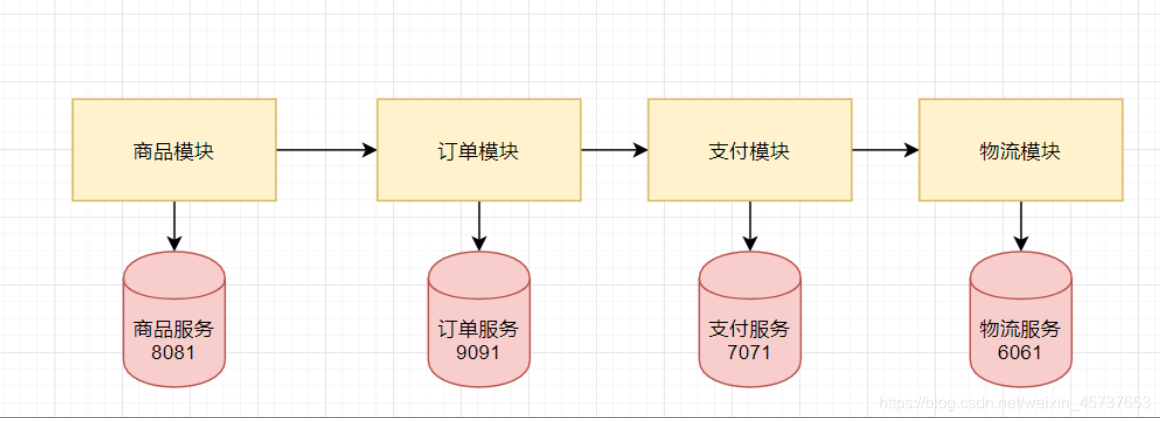
mapa de grupo: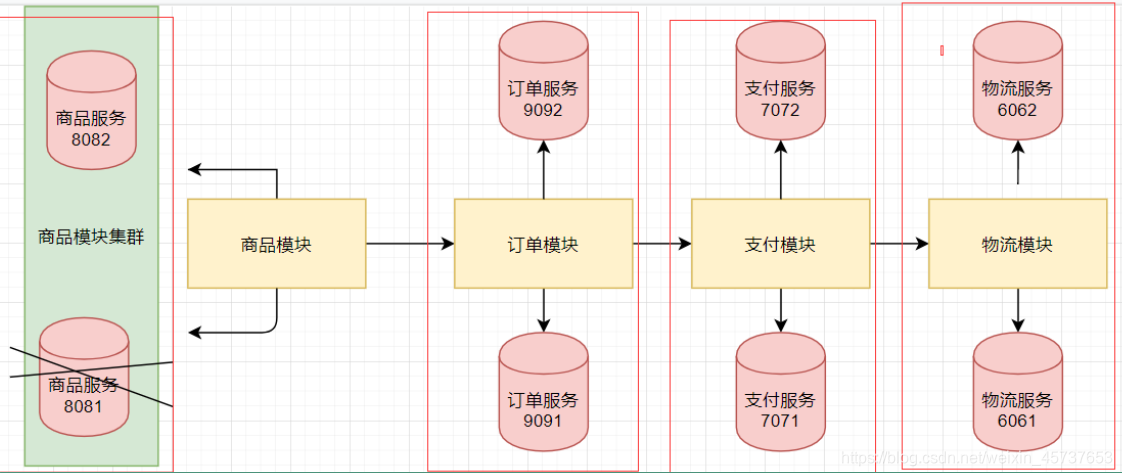
2.Redis selección de programa clúster
2.1. La replicación maestro-esclavo
Diagrama del análisis: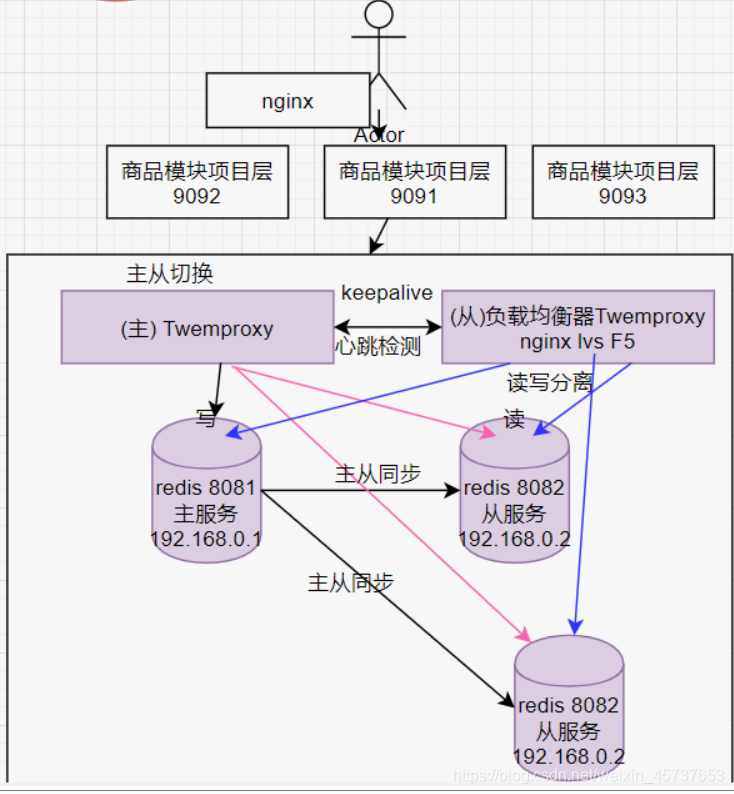
Ventajas:
resolver el problema de la alta concurrencia
desventajas:
- Gran capacidad de memoria - el mismo contenido desde el interior put primaria
- Si Redis servicio principal colgada desde el servidor principal no tomará la iniciativa a subir, y si se hace, es necesario añadir componentes adicionales tales como keepalvie (conmuta automáticamente de la primaria)
- Redis expansión y más problemas
2.2. Modo Sentinel
Redis 2.8 ofreceHerramienta Sentinelque viene control automatizadoyla recuperación de errores.
Diagrama del análisis:
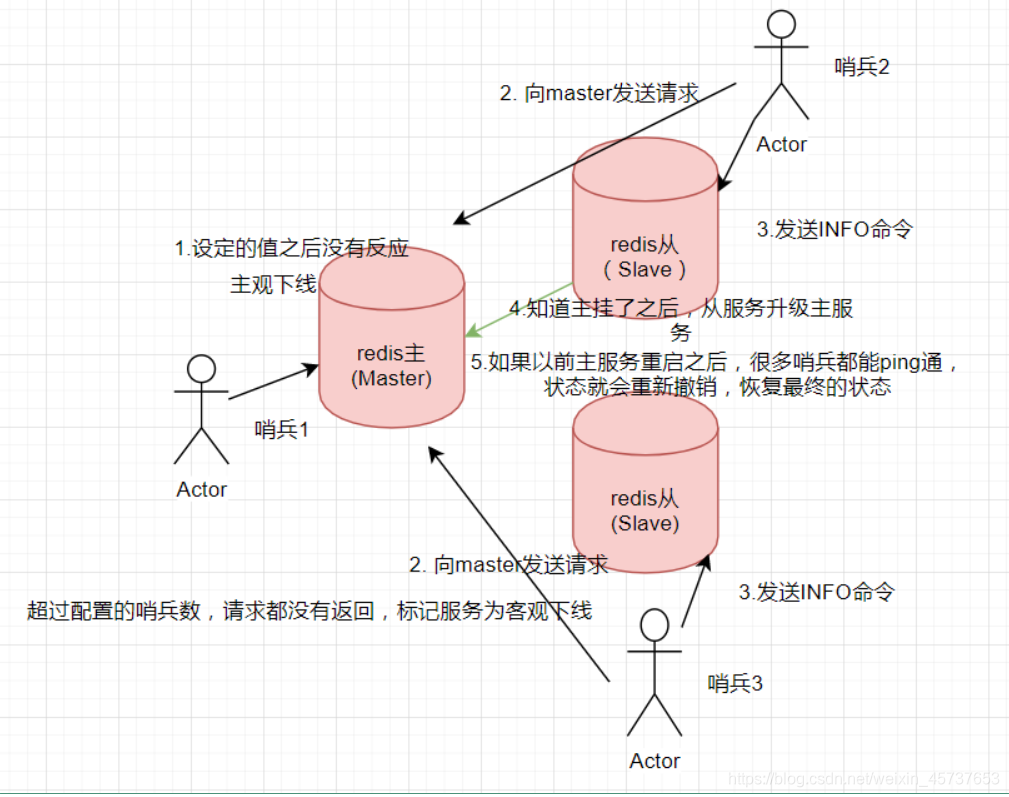
ventajas:
- Resolver el problema de la alta concurrencia
- Standby problema de conmutación resuelto
desventajas:
memoria de expansión no se han resuelto
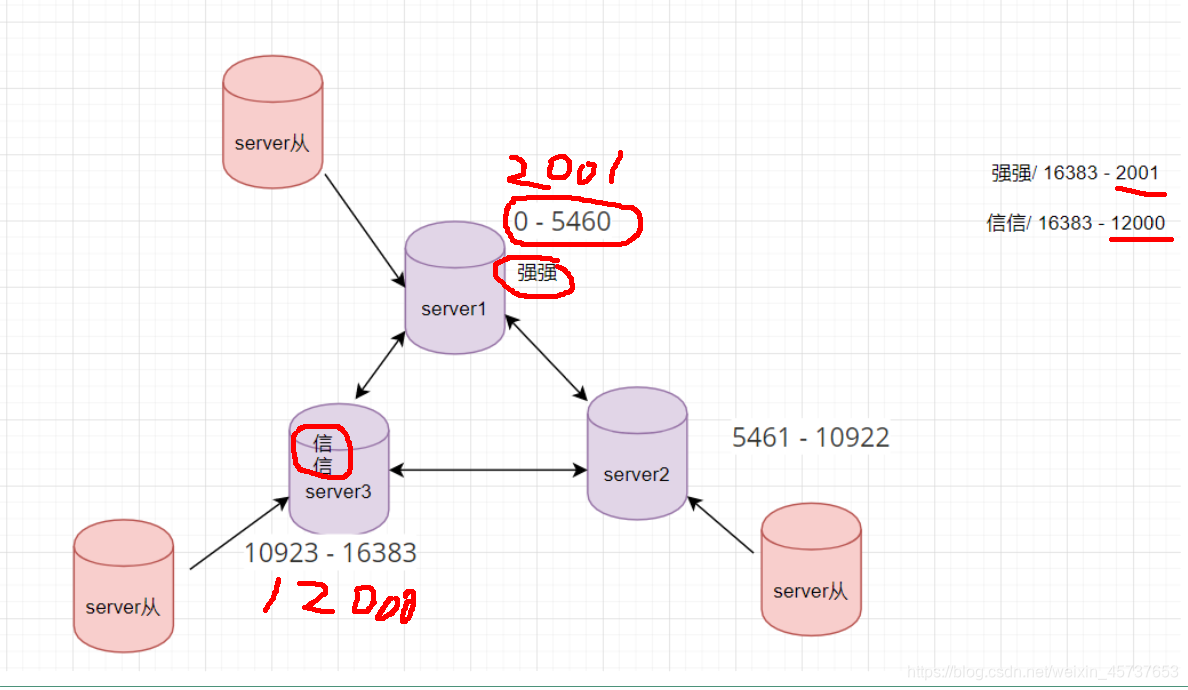
2.3.Redis-Cluster
Se unió al modo de clúster en redis3.0, implementadoRedis Distributed Storage, Que cadaEl contenido de diferentes nodos de almacenamiento redis.
usos Redis-ClusterSin estructura central
Un concepto de diseño: Mecanismo de almacenamiento distribuido - artesa (Es decir, un recipiente para el almacenamiento de datos)
Diagrama del análisis:
la penetración de la caché
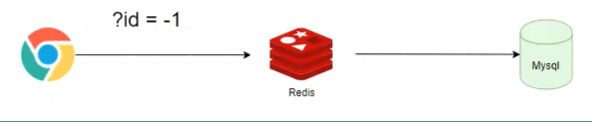
- Atacante datos de consulta frecuentes a un inexistente con el software? = Id-1 de los datos, los Redis no existe, no hay MySQL, pero cada vez que las peticiones son peticiones a MySQL, lo que resulta en una gran presión de Mysql
== == Soluciones
- Aumentar la petición de prueba: Si los parámetros no son legítimas retorno directo un mensaje de error.
- solicitada con frecuencia de interceptación: dirección IP tantas peticiones formuladas en 1s, establecen la lista negra.
- De acuerdo con la forma de pensar la lógica de negocio: Se puede añadir la verificación de identidad o código de autenticación de verificación
- Un almacén de datos no existe en la clave nulo Redis, y establece una fecha de caducidad
desglose caché
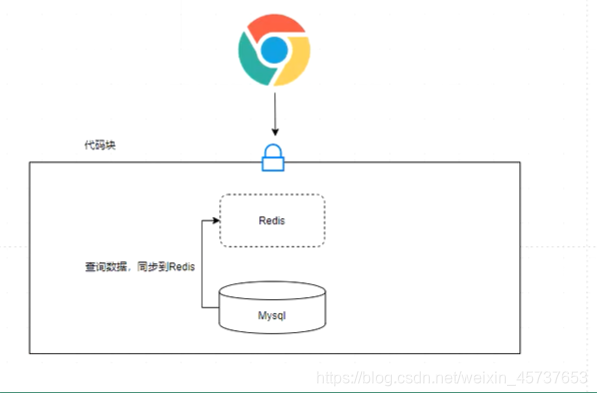
- desglose Cache (los mismos datos) se refiere a la base de datos de caché pero no hay datos existentes (por lo general el tiempo de caché expira), entonces debido a la particular gran número de usuarios simultáneos, mientras que los datos de caché de lectura no se lee, hay al mismo tiempo a la base de datos leer datos, causa una base de datos para aumentar la presión del momento, lo que resulta en una presión excesiva.
== == Soluciones
- (Key) establece de forma permanente la memoria caché de la memoria caché
- bloques más mutex código: Cuando una solicitud se encuentra en, pasará a través de los datos Redis MySQL Query, y pondrá los datos en una Redis, las solicitudes posteriores pueden obtener los datos de la Redis
avalancha
-
Caché avalancha se refiere a las grandes cantidades de datos en el tiempo de caducidad de la caché y consulta enormes cantidades de datos, la base de datos causando una presión excesiva incluso hasta la máquina. Y la caché es diferente ruptura, la ruptura se refiere a la concurrencia caché comprobar los mismos datos, diferentes datos de la caché avalancha expirado, están encontrando una gran cantidad de datos con el fin de revisar la base de datos.
solución:
-
Vencimiento en caché los datos de tiempo establecidos al azar, para evitar al mismo tiempo una gran cantidad de datos expiró fenómeno.
-
Si la base de datos de caché se distribuye despliegue, los datos hotspot uniformemente distribuidos y realizan diferentes base de datos de caché.
-
Conjunto de datos caliente nunca expira.
