prefacio
Heredando Partitioner <MapKEYOUT, MapVALUEOUT>
número para lograr la salida del documento final de la división de los datos!
datos de prueba
id ----tel ------ ip -------------dns -------up -- down -status
1 13736230513 192.196.100.1 www.zhengkw.com 2481 24681 200
2 13846544121 192.196.100.2 264 0 200
3 13956435636 192.196.100.3 132 1512 200
4 13966251146 192.168.100.1 240 0 404
5 18271575951 192.168.100.2 www.zhengkw.com 1527 2106 200
6 84188413 192.168.100.3 www.zhengkw.com 4116 1432 200
7 13590439668 192.168.100.4 1116 954 200
8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200
9 13729199489 192.168.100.6 240 0 200
10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200
11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200
12 15959002129 192.168.100.9 www.zhengkw.com 1938 180 500
13 13560439638 192.168.100.10 918 4938 200
14 13470253144 192.168.100.11 180 180 200
15 13682846555 192.168.100.12 www.qq.com 1938 2910 200
16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200
17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 404
18 18390173782 192.168.100.15 www.sogou.com 9531 2412 200
19 13975057813 192.168.100.16 www.baidu.com 11058 48243 200
20 13768778790 192.168.100.17 120 120 200
21 13568436656 192.168.100.18 www.alibaba.com 2481 24681 200
22 13568436656 192.168.100.19 1116 954 200
Frijol
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @ClassName:FlowBean
* @author: zhengkw
* @description: flowbean
* @date: 20/02/24上午 11:39
* @version:1.0
* @since: jdk 1.8
*/
public class FlowBean implements Writable {
//电话号码
private long telNum;
//上行流量
private long upFlow;
//下行流量
private long downFlow;
//流量和
private long totalFlow;
/**
* @param dataOutput 序列化数据
* @descrption: tel作为key 其他的数据作为val
* @return: void
* @date: 20/02/24 上午 11:44
* @author: zhengkw
*/
/**
* @param dataInput
* @descrption:序列化
* @return: void
* @date: 20/02/24 上午 11:45
* @author: zhengkw
*/
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readLong();
this.downFlow = dataInput.readLong();
this.totalFlow = dataInput.readLong();
}
/**
* @param dataOutput
* @descrption:反序列化数据
* @return: void
* @date: 20/02/24 下午 3:05
* @author: zhengkw
*/
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(totalFlow);
}
public FlowBean() {
super();
}
public FlowBean(long upFlow, long downFlow) {
this();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.totalFlow = upFlow + downFlow;
}
public void setTelNum(long telNum) {
this.telNum = telNum;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public void setTotalFlow(long upFlow, long downFlow) {
this.totalFlow = upFlow + downFlow;
}
public long getTelNum() {
return telNum;
}
public long getUpFlow() {
return upFlow;
}
public long getDownFlow() {
return downFlow;
}
public long getTotalFlow() {
return totalFlow;
}
@Override
public String toString() {
return upFlow + "\t" +
downFlow + "\t"
+ totalFlow
;
}
}
Mapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @ClassName:FlowMapper
* @author: zhengkw
* @description: flowMapper继承
* @date: 20/02/24上午 11:53
* @version:1.0
* @since: jdk 1.8
*/
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
Text k = new Text();
FlowBean v = new FlowBean();
/**
* @param key
* @param value 一行的数据
* @param context 传给reduce的封装数据
* @descrption: map阶段只负责分割数据 按照key来分组 val一般是元数据指标! totalFlow并不是元数据里的 所以要在reduce阶段处理
* @return: void
* @date: 20/02/24 下午 12:12
* @author: zhengkw
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行
String line = value.toString();
//切分 1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200
String[] strings = line.trim().split("\t");
//选取
k.set(strings[1]);//key
// 取出上行流量和下行流量
long upFlow = Long.parseLong(strings[strings.length - 3]);
long downFlow = Long.parseLong(strings[strings.length - 2]);
// v.set(downFlow, upFlow);
//封装flowbean
// flowBean.setTelNum(Long.parseLong(strings[1]));
v.setUpFlow(Long.parseLong(strings[strings.length - 3]));
v.setDownFlow(Long.parseLong(strings[strings.length - 2]));
v.setTotalFlow(Long.parseLong(strings[strings.length - 3]), Long.parseLong(strings[strings.length - 2]));
//封装输出 key,val--> 13xxxxxx , (upflow , downflow)
context.write(k, v);
}
}
Reducir
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @ClassName:FlowReduce
* @author: zhengkw
* @description: 重写reduce reduce阶段是统计 计算map分割好的数据
* @date: 20/02/24下午 12:09
* @version:1.0
* @since: jdk 1.8
*/
public class FlowReduce extends Reducer<Text, FlowBean, Text, FlowBean> {
FlowBean fb = new FlowBean();
/**
* @param key 手机号
* @param values flowbean封装的数据
* @param context
* @descrption:
* @return: void
* @date: 20/02/24 下午 12:13
* @author: zhengkw
*/
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long sum_upFlow = 0;
long sum_downFlow = 0;
long sum_totalFlow = 0;
//数据源是values 累加 up down & total
for (FlowBean fb : values
) {
//上行累加
sum_upFlow += fb.getUpFlow();
// 下行累加
sum_downFlow += fb.getDownFlow();
}
//总数据量
sum_upFlow = sum_upFlow + sum_downFlow;
//封装
fb.setTotalFlow(sum_upFlow, sum_downFlow);
fb.setUpFlow(sum_upFlow);
fb.setDownFlow(sum_downFlow);
fb.toString();
context.write(key, fb);
}
}
particionador
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @ClassName:ProvincePartitioner
* @author: zhengkw
* @description:将手机号按照前三位规则划分为5个区!
* @date: 20/02/25下午 3:52
* @version:1.0
* @since: jdk 1.8
*/
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int i) {
String prNum = text.toString().substring(0, 3);
// int partion = 4;
if ("136".equals(prNum)) {
return 0;
} else if ("137".equals(prNum)) {
return 1;
} else if ("138".equals(prNum)) {
return 2;
} else if ("139".equals(prNum)) {
return 3;
} else {
return 4;
}
}
}
Conductor
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @ClassName:FlowDriver
* @author: zhengkw
* @description: 驱动
* @date: 20/02/24下午 1:08
* @version:1.0
* @since: jdk 1.8
*/
public class FlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Path input = new Path("F:/input");//输入路径
Path output = new Path("F:/output1");//输出路径
//args = new String[]{input.toString(), output.toString()};
Configuration conf = new Configuration();
//判断文件输出目录是否存在
FileSystem fs = FileSystem.get(conf);
if (fs.exists(output)) {
fs.delete(output, true);
}
//conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR,"\t");
//反射创建对象
Job job = Job.getInstance(conf);
//设置3个类
job.setJarByClass(FlowDriver.class);
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReduce.class);
//设置2个输入输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//指定partitioner类和ReduceTask的数量
job.setPartitionerClass(ProvincePartitioner.class);
job.setNumReduceTasks(5);
// job.setInputFormatClass(KeyValueTextInputFormat.class);
//指定输入输出路径
FileInputFormat.setInputPaths(job, input);
FileOutputFormat.setOutputPath(job, output);
//将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
resultado

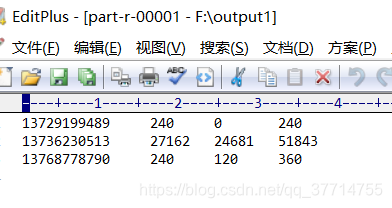
resumen
-
Particionador utiliza para escribir el escenario ubicado fase aleatoria de desbordamiento shuffle reducir (copia-especie).
-
Partición fue entregado a reduceTask procesamiento posterior, es necesario establecer el número de inicio reduceTask! número ReduceTask determina el número de particiones, el número de partición es una clase Partitoner
getPartition () está provisto, como es el operación de módulo, es decir, el número de partición sólo puede ser [0, reduceTask-1] toma un número entero positivo! -
Si no se define de particionamiento, la HashPartitioner por defecto a la partición!
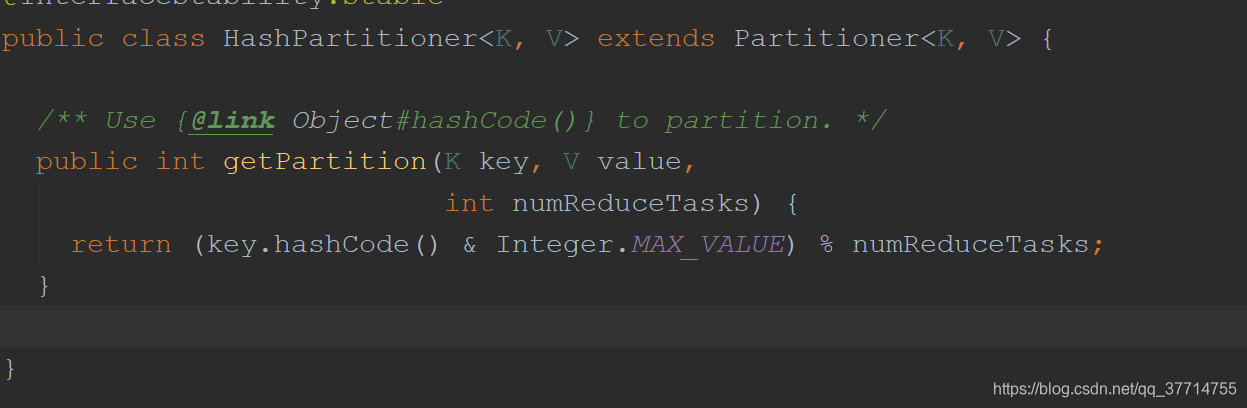
-
Establecer las dos propiedades siguientes en el trabajo Conductor Nota!
//指定partitioner类和ReduceTask的数量
job.setPartitionerClass(ProvincePartitioner.class);
job.setNumReduceTasks(5);
