¿Qué es un árbol de decisión / árbol de decisión (árbol de decisión)?
Un árbol de decisión es una estructura de árbol similar al diagrama de flujo: en la que cada nodo interno representa un atributo en la prueba, cada rama representa un atributo de salida, y cada hoja nodo representante de la clase o la distribución de clase. El nivel superior es la raíz del árbol.

Es la clasificación de un algoritmo métodos
Árbol de decisiones de construcción


¿Por qué la edad como la raíz de la misma?
En primer lugar, comprender la siguiente entropía (entropía) del concepto:
la información y el resumen, la forma de medir?
En 1948, Shannon propuso el concepto de "entropía de la información (entropía)" de
la información de la cantidad de información y la incertidumbre que tiene una relación directa de averiguar una cosa muy, muy incierto, o estamos nada saber las cosas que hay que saber mucho de la información ==> una medida de la cantidad de información equivalente a la cantidad de incertidumbres
ejemplo: adivinar la Copa del Mundo, si no sabe nada acerca de estos equipos, adivinar cuántas veces?
posibilidades de ganar de cada equipo no son iguales
bits (bits) para medir la cantidad de información
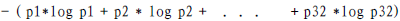
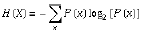
mayor será la incertidumbre de las variables, mayor es la entropía
algoritmo de inducción de árbol de decisión (ID3)
nodo determinación seleccione Propiedades
cantidad adquisición de información (información de ganancia): Ganancia (A ) = Información (D) - Infor_A (D)
por la A para clasificar adquirió tanta información como el nodo

, por ejemplo: En primer lugar, nuestro objetivo es ver si comprar un ordenador, por lo como una clasificación basada en la etiqueta de clase (5 Ge no, Ge 9 sí)

a continuación, añadir condiciones de edad
- 5 jóvenes, en donde dos sí, hay tres 3
- 4 Media, de los cuales 4 sí
- 5 de alto nivel, en el que tres sí, 2 no hay dos que
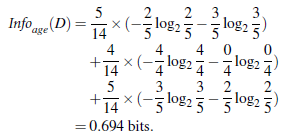
resta es decir, información sobre la edad de la subasta:
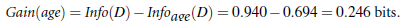
Del mismo modo, la ganancia (ingresos) = 0,029, Ganancia (los alumnos) = 0,151, Ganancia (credit_rating) = 0,048
Por lo tanto, el nodo raíz como la edad primera seleccionado

rama repetición
algoritmo:
- Solo árbol nodo representativo de muestras de formación (paso 1).
- Si las muestras están en la misma clase, el nodo se convierte en la hoja, y con la referencia de clase (pasos 2 y 3). Como el Oriente compró la computadora todo sí, directamente en las hojas
- De lo contrario, la ganancia de información utiliza el algoritmo basado en una medida llamada entropía como información heurística, optar por mejores muestras classify de atributos (paso 6). Este atributo se convierte en el nodo de "test" o atributo "determinación" (paso 7). En esta versión del algoritmo,
- Todas las propiedades se clasifican los valores, es decir, discretas. atributo continuo debe ser discreto.
- Para cada valor conocido de la propiedad de prueba, crear una rama, y por lo tanto dividir la muestra (paso 8-10).
- Utilizando el mismo algoritmo de proceso de forma recursiva formado en cada uno de los árboles de decisión muestra dividida. Una vez que una propiedad aparece en un nodo, no tendría que tener en cuenta (paso 13) de cualquier descendiente del nodo.
- paso partición recursiva sólo si las siguientes condiciones son verdaderas paradas :
- (A) a todas las muestras de un nodo dado pertenece a la misma categoría (paso 2 y 3).
- (B) no propiedad residual se puede utilizar para más dividir la muestra (paso 4). En este caso, el voto mayoritario (paso 5). Por eso, cuando cinco Sí1 un no, sí marcados
- Este implica la conversión de un nodo dado a una hoja, y se marcó con una clase en una muestra donde la mayor parte de ella. Alternativamente, la muestra puede ser almacenada en el tipo de nodo de distribución.
- © M.
- test_attribute = ai no muestra (paso 11). En este caso, la mayoría de las muestras en las clases
- Crear una hoja (paso 12)
Otros algoritmos:
C4.5: Quinlan
de clasificación y regresión árboles (la CART): (L. Breiman, J. Friedman, R. Olshen, C. piedra)
En común: ambos son algoritmo voraz, de arriba hacia abajo (enfoque de arriba hacia abajo)
Diferencia: Diferentes métricas de selección de atributos: C4.5 (relación de ganancia), CART (índice de Gini), ID3 (información de ganancia)
¿Cómo lidiar con las propiedades de las variables continuas?
La edad = 1, 2, 3, 4, 5, 6, 7, 8
necesidad de valores de umbral de <= 4,> 4
ramas de los árboles y las hojas de corte (a) evitar el sobreajuste
- En primer lugar la poda
- después de la poda
árbol de decisión ventajas : intuitiva, fácil de entender, eficientes conjuntos de datos a pequeña escala
árbol de decisión desventajas :
- Las variables continuas mal acuerdo
- Cuando más categorías, el error se incrementaron más rápido
- Puede escalar en general
código
Para la matriz de datos se convierte como se muestra:

from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO
# Read in the csv file and put features into list of dict and list of class label
allElectronicsData = open(r'AllElectronics.csv', 'rt')
reader = csv.reader(allElectronicsData)
headers = next(reader)
print(headers)
['RID', 'age', 'income', 'student', 'credit_rating', 'class_buys_computer']
print('-' * 30)
featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row)-1]) # 取每行最后一个值class label加入labelList
rowDict = {}
for i in range(1, len(row)-1): # 第0列为索引,所以从第1列开始
#print(row[i])
rowDict[headers[i]] = row[i]
#print('rowDict:', rowDict)
featureList.append(rowDict)
print(featureList)
# Vetorize features
vec = DictVectorizer() # 自动将字典形式转为0,1形式
dummyX = vec.fit_transform(featureList) .toarray()
print("dummyX: " + str(dummyX))
dummyX: [[0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
print(vec.get_feature_names())
['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes']
#print(dummyX.shape) # 14*10
print("labelList: " + str(labelList))
labelList: ['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no']
# vectorize class labels
lb = preprocessing.LabelBinarizer() # 将label转为0,1
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY))
dummyY: [[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]
# Using decision tree for classification
# clf = tree.DecisionTreeClassifier()
clf = tree.DecisionTreeClassifier(criterion='entropy') # 构建决策树(ID3)
clf = clf.fit(dummyX, dummyY)
print("clf: " + str(clf))
# # Visualize model 生成.dot文件,可使用Graphviz转为pdf将树可视化
# with open("allElectronicInformationGainOri.dot", 'w') as f:
# f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
oneRowX = dummyX[0, :]
oneRowX = oneRowX.reshape(1, -1) # sklearn数据要求为二维
print("oneRowX: " + str(oneRowX))
oneRowX: [[0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]]
newRowX = oneRowX
newRowX[0, 0] = 1
newRowX[0, 2] = 0
print("newRowX: " + str(newRowX)) # 构件一个新数据
newRowX: [[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]]
predictedY = clf.predict(newRowX)
print("predictedY: " + str(predictedY)) # 预测新数据的label(买还是不买)
predictedY: [1]
Fig Tree Visualización:

Instalación Graphviz
entorno de configuración variable de
conversión en la visualización del árbol de puntos de archivos PDF: punto -Tpdf iris.dot -o outpu.pdf
