Article Directory
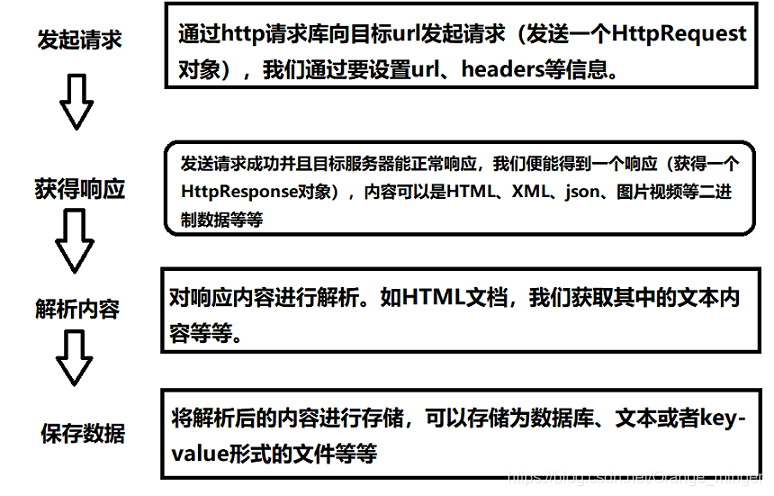
Reptiles whole process consists of three parts: the fetch page, the page parse, store data. Crawl pages need to request support libraries, parsing the page needs to resolve support libraries, databases and data storage needs to support connection to the database package.
1, common library request
- requests library: Python3 built another request library urllib, but more cumbersome to use this library, semantics is not very clear methods. So with requests library, which belongs to the third-party libraries, so you need to install.
- Selenium library: Selenium is a reptile can be automated library, this library is very powerful, you can use the browser to complete the library drive crawling. We can write some automated script, then the program will be able to indulge our crawling page.
- ChromeDriver: ChromeDriver is a driver, you want to automate the only reptiles Selenium enough, you also need to drive. ChromeDriver is driving Google browser.
- Like driving a drive, then there is Firefox, but I think that Firefox did not use up Google so smooth, no over again. Want crawling simple page, usually requests + Selenium + combination ChromeDriver is sufficient.
2, commonly used parsing library
- lxml library: lxml library supports parsing HTML and XML, XPath support analytical methods, and analytical efficiency is very high.
- Beautiful Soup library: The library supports HTML and XML parsing, it has the advantage that it has a powerful API, a lot easier than lxml, features and more powerful.
- pyquery library: equally powerful, its API and jQuery (a js framework) is very similar to the familiar front end is particularly convenient to use. I personally prefer using this library.
- tesserocr library: tesserocr Python is a library OCR recognition, identification codes and the like is mainly used.
3, common database
- The database includes a relational database and non-relational database. I used is MySQL, Redis and MongoDB.
- PyMySQL, PyMongoDB, redis-py library: These three libraries are connected to the database, similar to Java database-driven.
4, crawling APP associated libraries
- Charles: a capture editing tools, easy to use, easy to control a data request, modify simple and convenient data capture.
- mitmproxy: it is a support for HTTP and HTTPS packet capture program that can intercept the request and send a request, and so on.
- Appium: like Selenium, belonging to the end of APP automated testing tools.
5, the frame
- Frame: If the amount is not crawling, speed requirements are not large, such as library use requests + selenium completely meet the requirements. However, if the amount crawling up, many of the code is the code repetition, this time frame is adopted.
- pyspider: pyspider with the WebUI, script editor, task monitoring, project management, and more powerful.
- Scrapy: is a website for crawling data, extract structured data written application framework.
Please indicate the wrong place! Thought that it was in trouble if you can give a praise! We welcome comments section or private letter exchange!
