0. generating jar package

1. Add sftp connection
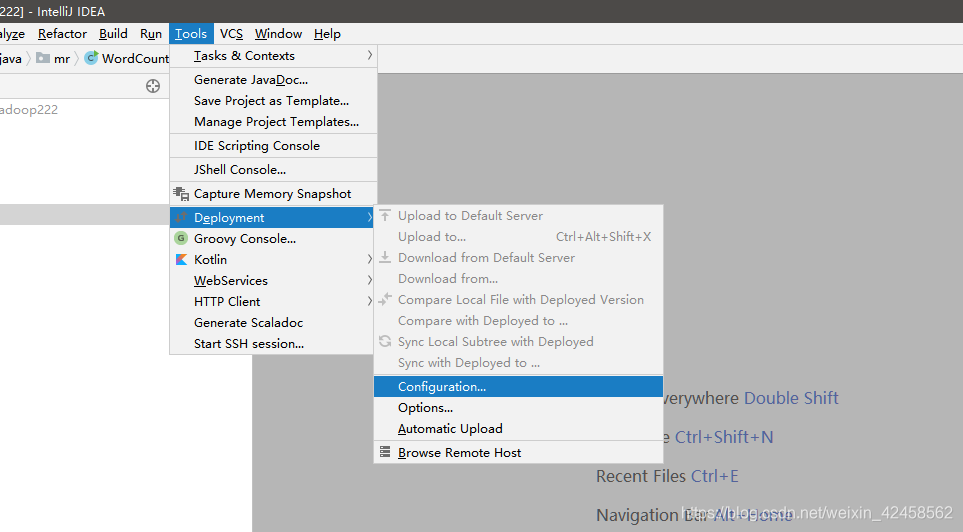

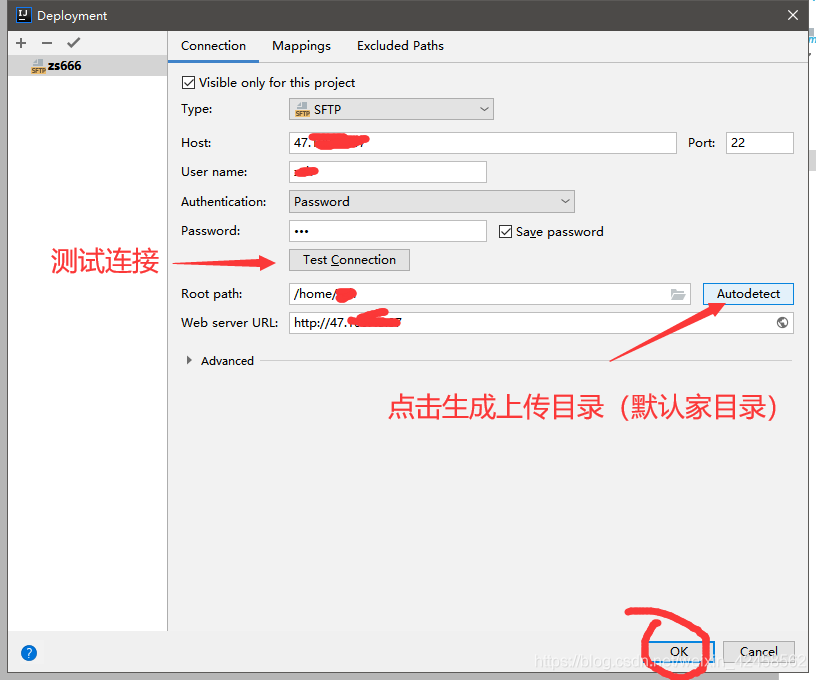
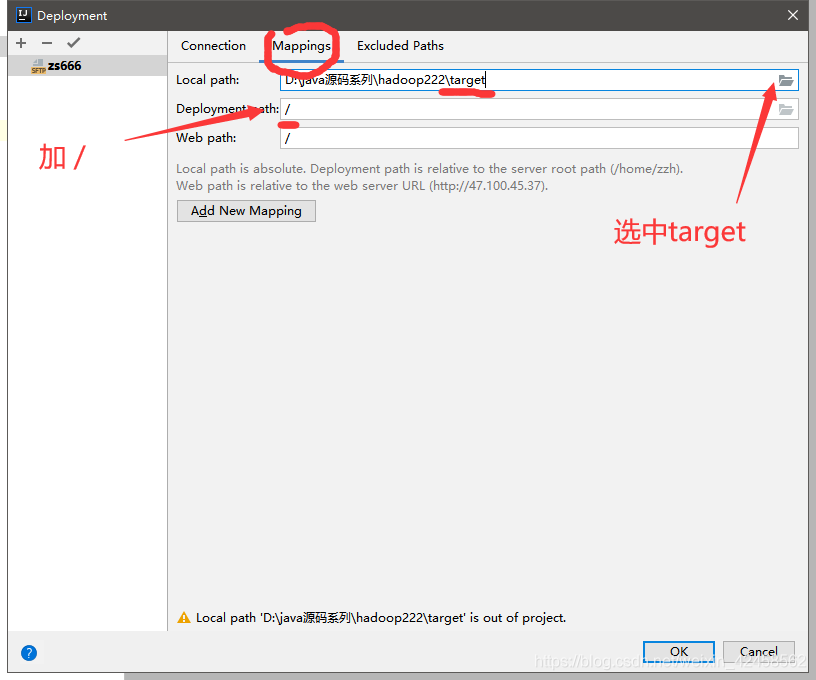
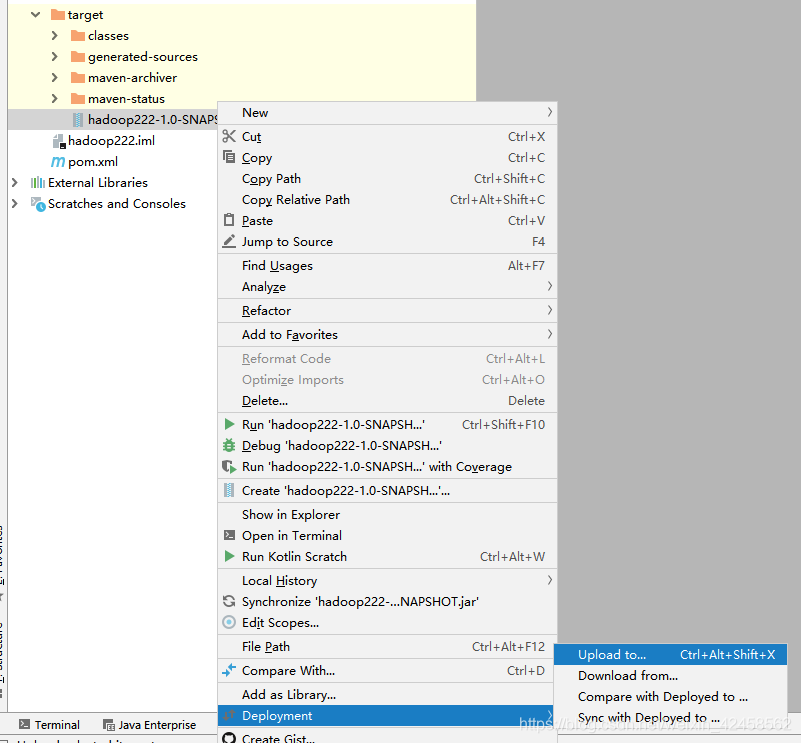
2. Step 0 Upload jar packets generated
Jar package running on 3.linux
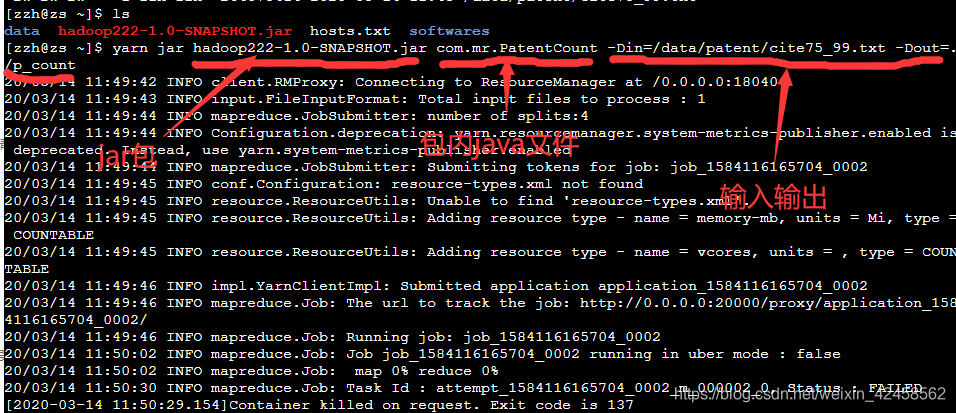
yarn jar hadoop222-1.0-SNAPSHOT.jar com.mr.PatentCount -Din=/data/patent/cite75_99.txt -Dout=./p_count
Wait for completion
Share java source code:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @description: .使用MR程序计算专利统计
**/
public class PatentCount extends Configured implements Tool{
public static void main(String[] args) throws Exception{
System.exit(ToolRunner.run(new PatentCount(),args));
}
@Override
public int run(String[] args) throws Exception{
// 作业配置
Configuration conf=this.getConf();
// 指定数据输入和输出的路径
Path input=new Path(conf.get("in"));
Path output=new Path(conf.get("out"));
// 创建Job【作业】对象
Job job=Job.getInstance(conf,"专利统计");
job.setJarByClass(this.getClass());
// Map阶段的配置
// 配置Map阶段要执行的任务
job.setMapperClass(PatentCountMapper.class);
// 配置Map阶段数据输出的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 指定Map阶段读取原始数据的方式
job.setInputFormatClass(TextInputFormat.class);
// 配置Map阶段要读取的数据的路径
TextInputFormat.addInputPath(job,input);
// Reduce阶段的配置
job.setReducerClass(PatentCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,output);
// 提交作业
return job.waitForCompletion(true)?0:1;
}
// Map阶段
// Map阶段的map方法每执行一次,则处理一行数据;
// Mapper类有四个泛型参数:
// 前两个是数据进入Map阶段的k1和v1的数据类型,一般分别为LongWritable【被处理的当前行
// 数据的偏移量】和Text【当前这一行数据】;
// 后两个指的是数据被Map任务处理完成之后的中间结果数据k2和v2的数据类型,视需求而定;
static class PatentCountMapper
// k1 v1 k2 v2
extends Mapper<LongWritable,Text,Text,IntWritable>{
private Text k2=new Text();
private IntWritable v2=new IntWritable();
@Override
protected void map(
LongWritable k1, // 该参数【变量】中所存储是当前处理的某一行数据的偏移量
Text v1, // 该参数【变量】中所存储的是当前被处理的某一行数据
Context context // 用于联系Map阶段和Shuffle阶段的对象
) throws IOException, InterruptedException{
// 编写Map阶段的处理逻辑
String[] strs=v1.toString().split("[,]");
// Text k2=new Text(strs[1]);
// IntWritable v2=new IntWritable(1);
this.k2.set(strs[1]);
this.v2.set(1);
context.write(this.k2,this.v2);
}
}
// Reduce阶段
// 前两个泛型参数表示数据进入Reduce的k2和v2的数据类型,该泛型参数由Map阶段的
// 输出的泛型参数所决定,Reduce阶段输入的k2和[v2]的泛型参数跟Map阶段输出的
// k2和v2的泛型参数是一致的;
// 后两个泛型参数表示Reduce阶段输出的k3和v3的数据类型,由需求而定;
static class PatentCountReducer
// k2 v2 k3 v3
extends Reducer<Text,IntWritable,Text,IntWritable>{
private Text k3=new Text();
private IntWritable v3=new IntWritable();
@Override
protected void reduce(
Text k2, // 专利编号
Iterable<IntWritable> v2s, // 相同的专利编号对应的v2的集合
Context context // 用于联系Reduce阶段和MR框架的对象
) throws IOException, InterruptedException{
this.k3.set(k2.toString());
int sum=0;
for(IntWritable v2: v2s){
sum+=v2.get();
}
this.v3.set(sum);
context.write(this.k3,this.v3);
}
}
}
Data format is as follows:

idea MapReduce programs running locally (local virtual machine)
to modify windows hosts
The four configuration files in xml resources in
idea in mapred-site.xml plus
<!--idea本地配置-->
<property>
<name>mapreduce.job.jar</name>
<value>D:\\java源码系列\\hadoop222\\target\\hadoop222-1.0-SNAPSHOT.jar</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
