- Outline
LSTM in machine learning application of the above is very broad, from stock analysis, semantic analysis and so on machine translation into all aspects of it comes in through the front of the structure for the analysis LSTM, this section describes some of the LSTM a small application that sequence generation. In fact, sequence generation ability is a generic term for a number of applications, such as: the machine and let the machine after learning music to create music based on the model of their own learning (producer of a job soon it ....), let the machine learning a language and then let the learning Word to produce their own models to speak, and so on. In fact, this is the essence of LSTM network structure of a one-to-many's. This section is mainly to explain the application of this kind of network structure.
- Sequence generation network architecture analysis
Before we actually write code and implement, our primary task is how to build a network structure of a sequence generation. A sequence generation of network structure is actually divided into two parts, the first part is encoding (modeling), that is, we modeled network, which network structure is a many-to-many; the second part of the decoding process, it is a structure of one-to-many. So this particular network architecture is like? Let's look at the following pictures
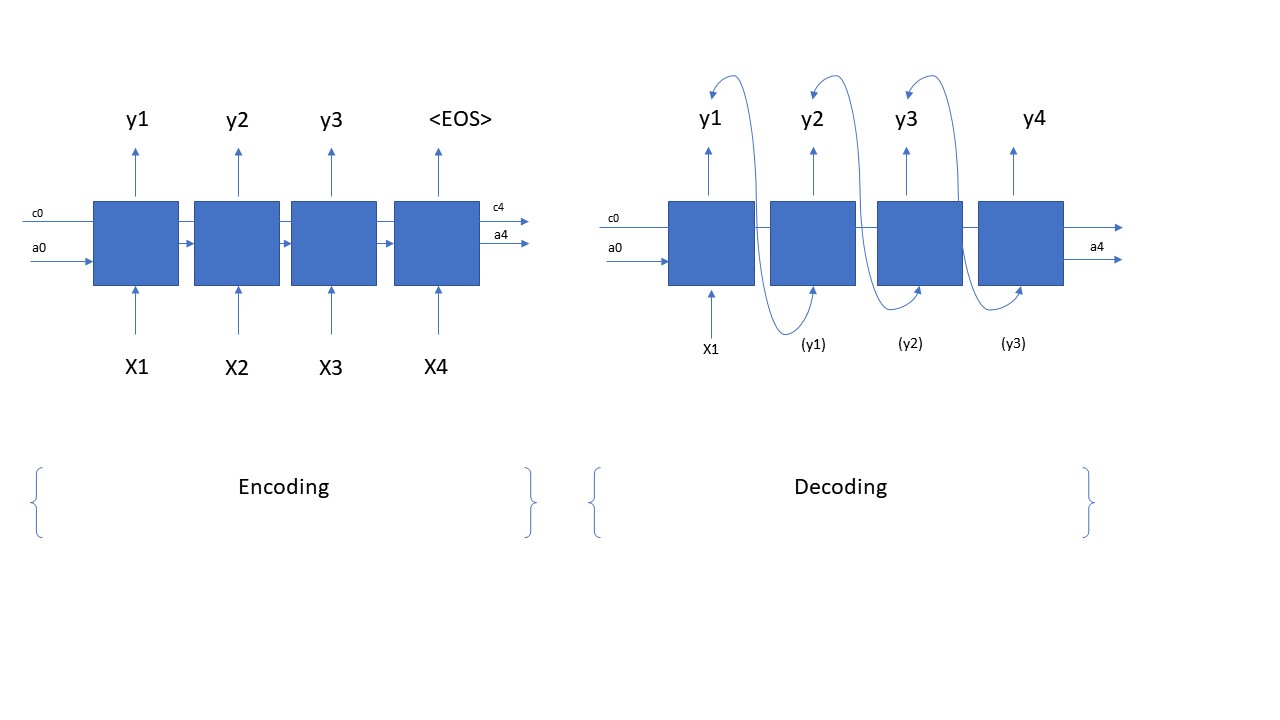
The above picture shows the whole process is a sequence generation and structure from encoding to decoding of. In our this application, our encoding input each time step is a character, the output is the word corresponding to input data comes from our training data; wait until we trained, we will train come LSTM cell to construct a decoding network, that is, we just enter a word, it is based on our model before learning to automatically predict we say something, is not it cool? ? Of course, at the encoding stage, our LSTM specific number of time steps, based on our input data of the shape determined; in the decoding stage specific number of time step is by our own to decide, we need to use a for loop to determine our time steps in the decoding phase. From the figure, we can clearly be seen also at the time of decoding, we have only one input X, time behind the step input is the output of a previous time step. The above sequence is how a whole generation of structure. Then down, we will analyze some of its code to see how we use the code to implement the above network structure.
- Sequence generation code analysis
From the above analysis, we can see that sequence generation is composed of two parts, so naturally we certainly scored the code into two parts to implement the network structure in the figure above, then the next we take a look at the first step, that is, how Python is achieved by encoding the structure of the code as shown below, we look at the code to slowly analysis:
#define shared variables
n_a=64 n_values = 78 # dimensions of out single input reshapor = keras.layers.Reshape((1, n_values)) # Used in Step 2.B of djmodel(), below LSTM_cell = keras.layers.LSTM(n_a, return_state = True) # Used in Step 2.C, return_state muset be set densor = keras.layers.Dense(n_values, activation='softmax') # Used in Step 2.D
#multiple inputs (X, a, c), we have to use functional Keras, other than sequential APIs def create_model(Tx, n_a, n_values): """ Implement the model Arguments: Tx -- length of the sequence in a corpus n_a -- the number of activations used in our model n_values -- number of unique values in the music data Returns: model -- a keras instance model with n_a activations """ # Define the input layer and specify the shape X = keras.Input(shape=(Tx, n_values))#input omit the batch_size dimension, X is still 3 dimensiones (with batch_size dimension). # Define the initial hidden state a0 and initial cell state c0 a0 = keras.Input(shape=(n_a,), name='a0') c0 = keras.Input(shape=(n_a,), name='c0') a = a0 c = c0 # Step 1: Create empty list to append the outputs while you iterate outputs = [] # Step 2: Loop for t in range(Tx): # Step 2.A: select the "t"th time step vector from X. x = keras.layers.Lambda(lambda x: X[:,t,:])(X) # Step 2.B: Use reshapor to reshape x to be (1, n_values) (≈1 line) #LSTM layer as the default dimension is input (batch_size, Tx, n_values), wherein batch_size is omitted, that is, (Tx, n_values). If (Tx, n_values), then, LSTM () Tx default cycle times, and therefore, we will reshape it into (1, n_values), it will not be the cycle. = X reshapor (X) # the Step 2.C: The LSTM_cell the Perform One of STEP A, _, C = LSTM_cell (X, initial_state = [A, C]) # the Step 2.D: The hidden to the Apply densor Output State of LSTM_Cell OUT = densor (A) Shape # apos IS OUT (m,. 1, n_values) # the Step 2.E: The Output to the Add "Outputs" outputs.append (OUT) # the Step. 3: Model instance the Create Model keras.Model = ( = Inputs [X-, A0, cO], = Outputs Outputs) return Model
From the above code, we can see, first of all we have to define shared variable, for example a, c of dimension, LSTM_cell, so these variables in our model in either encoding or decoding are common, not He said a LSTM layer to contain a number of LSTM_cell, this is the wrong understand (although we painted the picture above is so, but this is in order to facilitate understanding could draw a lot more LSTM_cell, in fact the same LSTM_cell, I hope not misunderstand). First we need to build this network parameters are, Tx = time_steps; n_a = dimension a, c of the vector; and we n_values = vector of each input dimension. Since our network has three inputs, namely, X, a, c, so we must first define these three inputs, and setting their shape, their attention in setting shape when it is not required to have a batch_size; then we went for loop, the first time step of extracting each input value, i.e. thing Lambda layer made of the above code, and because we are the values extracted for each time step, each time step, only LSTM will cycle once, so we still have to reshape it (1, n_values); we then sends the processed transmitted to LSTM_cell input value, and returns the hidden state a, and the memory cell c, and finally through a dense layer we calculated output and the output of each step put into outputs this list. This is the step we build the entire network of the encoding. Well, since we analyzed the above encoding stage, completed the training process and we LSTM been LSTM we want, then we take a look at our next decoding process, namely, how to generate (predict with LSTM get training ) our sequence friends, let's look at the following code, and then slowly analysis
def sequence_inference_model(LSTM_cell, n_values = 78, n_a = 64, Ty = 100): """ Uses the trained "LSTM_cell" and "densor" from model() to generate a sequence of values. Arguments: LSTM_cell -- the trained "LSTM_cell" from model(), Keras layer object densor -- the trained "densor" from model(), Keras layer object n_values -- integer, number of unique values n_a -- number of units in the LSTM_cell Ty -- integer, number of time steps to generate Returns: inference_model -- Keras model instance """ # Define the input of your model with a shape (it is a one-to-many structure, the input shape is (1,n_values)) x0 = keras.Input(shape=(1, n_values)) # Define a0, c0, initial hidden state for the decoder LSTM a0 = keras.Input(shape=(n_a,), name='a0') c0 = keras.Input(shape=(n_a,), name='c0') a = a0 c = c0 x = x0 # Step 1: Create an empty list of "outputs" to later store your predicted values (≈1 line) outputs = [] # Step 2: Loop over Ty and generate a value at every time step for t in range(Ty): # Step 2.A: Perform one step of LSTM_cell a, _, c = LSTM_cell(x, initial_state=[a, c]) # Step 2.B: Apply Dense layer to the hidden state output of the LSTM_cell out = densor(a) # Step 2.C: Append the prediction "out" to "outputs". out.shape = (None, 78) outputs.append(out) # Step 2.D: Select the next value according to "out", and set "x" to be the one-hot representation of the # selected value, which will be passed as the input to LSTM_cell on the next step. We have provided # the line of code you need to do this. x = keras.layers.Lambda(one_hot)(out) # Step 3: Create model instance with the correct "inputs" and "outputs" inference_model = keras.Model(inputs=[x0, a0, c0], outputs=outputs) return inference_model
inference_model = sequence_inference_model(LSTM_cell, densor, n_values = 78, n_a = 64, Ty = 50)
inference_model.summary()
x_initializer = np.zeros((1, 1, 78))
a_initializer = np.zeros((1, n_a))
c_initializer = np.zeros((1, n_a))
pred = inference_model.predict([x_initializer, a_initializer, c_initializer])
The inference model is based LSTM above trained to to predict, which share parameter weights and BIAS LSTM above training come in, which values to predict the back according to one word x0 input to output, specifically the output number values are determined according to user setting Ty, of course, it may also be more refined our output management, for example, if the EOS met, we stop the output directly. Even with our previous LSTM, but because of the different structure, we still have to go to build a new inference model, that is, to re-build a decoding structure. Decoding from the structure we can see, we still have three inputs, i.e. x0, a0, c0. There are simpler than encoding the place is so we do not need to go to reshape input, our input is standard shape, namely that (batch_size, Tx, n_values), (batch_size, n_a), (batch_size, n_a) , and it direct input into the input to Lstm densor and can not necessary to perform a number of aspects of the arranged shape, followed by an encoding point here is not the same, is the need to each time step are output as the next time step are input, i.e., the above code x = tf.keras.Lambda (one_hot) (out). Because this is an inference model, so we do not need to re-fitting it, it can directly call the method can predict predict it.
- to sum up
For the sequence generation-related applications of it, we must first find in the mind of this pattern, that it is a 2-part, a encoding, a decoding; to train the model and then encoding, decoding using the model to predict. For the input layer input, be sure to pay attention to and understand their input data of shape, must be consistent; for variable share together is important to understand, for example LSTM_cell, densor, etc., they are composed of the most basic model Hopefully this LSTM , all share, not every time step has independent entity. If the above steps for content and understand the words for the sequence generation-related applications can then apply the same pattern to achieve, the only change needed is to look at the value dimension.