table of Contents
Multi-graphic detailing each cluster mysql program
The benefits of clusters
- High availability: fault detection and migration, multi-node backup.
- Scalability: New database nodes convenient, easy expansion.
- Load balancing: a service access switch a node, sharing a single node database pressure.
To consider the risk of cluster
- Network: The division of the cluster may also be due to a network failure is split into a plurality of portions, each of the nodes connected to one another, the nodes lost connection between the parts.
- Split brain: failure leading to cluster database nodes run independently of each other is called "split-brain." This may result in inconsistent data and can not be repaired, for example when two independent database nodes update the same row on the same table.
@
A, mysql factory produced
1,MySQL Replication
mysql replication (MySQL Replication), it is a function that comes with mysql.
Introduction Principles:
Binlog replication is master-slave realized by the master repository data reproducing asynchronous replication. That is, when the main library to perform a sql command, in the same execution again from the library, so as to achieve master-slave replication. In this process, Master write operation on the data recorded in the binary log files (the binlog), generates a log dump thread from a library used to i / o threads pass binlog. From the i / o requests binlog threads library to the main library, and writes the obtained binlog relay log log (relaylog), the thread from the library sql, relaylog reads the log file, and parsed into specific operation, the main operation of the same, to achieve the same final data.
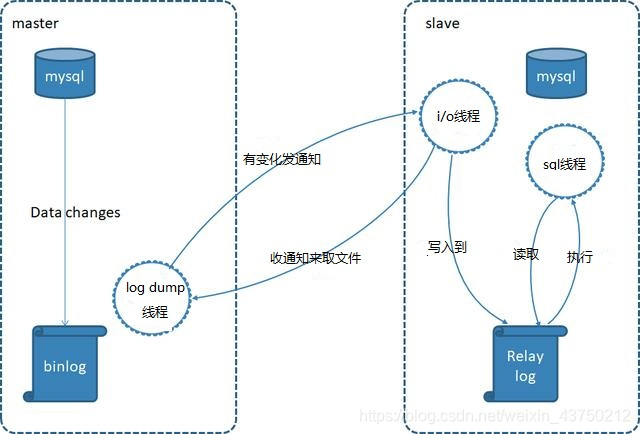
MySQL Replication from a multi-master configuration, the main aim is to achieve a multi-point data backup (not fail-over and load balancing). Compared to a single mysql, a main advantage of the multi from the following:
- If you let the background reads from the database, so that the write operation to connect the main database, separate read and write can play a role, this time from multiple databases can do load balancing.
- May be a temporary interruption of the copy process from the database to back up data, which does not affect the external service master data (If you perform backup on the master, need to master in readonly state, which means that all the write requests need to block) in .
On all cluster program, its advantages are:
- Master-slave replication is mysql own, without the help of a third party.
- Deleted data can be recovered from the binlog log.
- Configuration is simple and convenient.
The disadvantage is as follows:
- Binlog data obtained from the library and from the replay, it is certainly written with the main library there is a time delay data, so the data from the database always lags behind the main library.
- The main bank and the delay between the high demand from the network database, if the network delay is too high, increase the above-described hysteresis, resulting in inconsistent final data.
- A single master node hung up, we will not provide external writing services.
2,MySQL Fabirc
mysql fabric (MySQL Fabirc), is the official mysql.
This is based on the MySQL Replication, fault detection and increase the transfer, automatic data fragmentation. But still is a master multi-slave configuration, MySQL Fabirc only one master node, the master node when the difference is hung up in the future, will choose from one of the nodes when the master node.
On all cluster program, its advantages are:
- Mysql tools provided by the official without third-party plug-ins.
- Deleted data can be recovered from the binlog log.
- After hanging up the master node can be automatically selected when a master node does not affect the continued offer writing services from the external node from.
The disadvantage is as follows:
- Binlog data obtained from the library and from the replay, it is certainly written with the main library there is a time delay data, so the data from the database always lags behind the main library.
- The main bank and the delay between the high demand from the network database, if the network delay is too high, increase the above-described hysteresis, resulting in inconsistent final data.
- May 2014 launch of the product, database junior, not many application cases, all kinds of information online is relatively small.
- Services and support in the same query is only a fragment, the updated transaction data can not be fragmented across the query statement returns the data can not be cross-fragmentation.
- Failure recovery 30 seconds or more (in this way are InnoDB storage engine).
3,MySQL Cluster
mysql cluster (MySQL Cluster) mysql official also provided.
MySQL Cluster is a multi-master multi-slave structure
On all cluster program, its advantages are:
- Mysql tools provided by the official without third-party plug-ins.
- Excellent high availability, 99.999% availability, automatic segmentation data, redundant data can be cross-node (which data sets are not stored on a particular instance MySQL, but are distributed in a plurality of Data Nodes, i.e. a table the data may be distributed over multiple physical nodes, no data will be backed up on the plurality of redundancy data nodes. any of the data change operation, will be synchronized in a set of data nodes, in order to ensure data consistency).
- Excellent scalability, automatic segmentation data can facilitate the expansion of the database level.
- Excellent load balancing can be used for both read and write operations are intensive applications, you can use SQL and NOSQL interface to access the data.
- A plurality of main nodes, there is no single point of failure, a node failure recovery is typically less than one second.
The disadvantage is as follows:
- Architectural patterns and principles are complex.
- Use only storage engine NDB, and InnoDB normal use, there are many significant gaps. For example, in a transaction (which only supports transaction isolation level Read Committed, that is, before submitting a transaction, can not find the changes made within the transaction), foreign key (although the latest NDB storage engine has support foreign keys, but there are performance issues as the records associated with the foreign key in another possible fragment node), on a different table limit, it could lead to the development of daily accidents. Click to view the specific gaps Compare
- As a distributed database system, there is a lot of data between each node communications, such as access for all is to go through more than one node (there is at least one SQL Node and a NDB Node) to complete, so the internal network between nodes high bandwidth requirements.
- Data Node data will be as far as possible in memory, large memory requirements, and restart when the data node will load data into memory takes a long time.
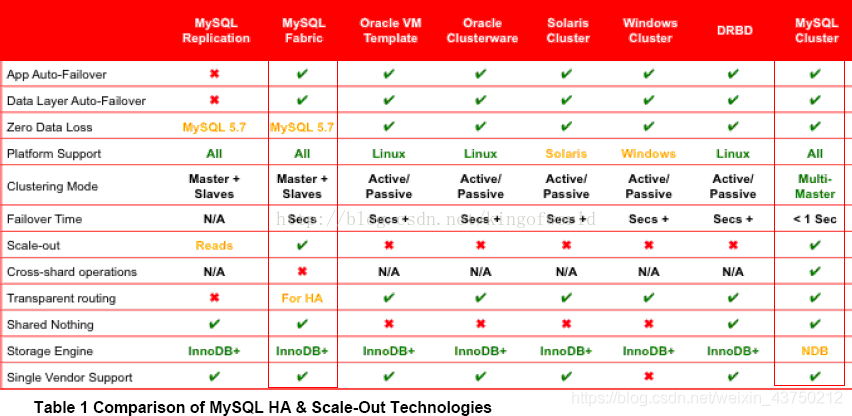
Comparison of the difference between the official three brothers as shown below;
Two, mysql third-party optimization
4,MMM
MMM is based on MySQL Replication, optimize it.
MMM (Master Replication Manager for MySQL) is more than double from the main structure, which is Google's open source project, using the Perl language to make extensions to MySQL Replication, provides a dual master failover and dual master the daily management of the script, the main to monitor and make mysql master-master replication failover.
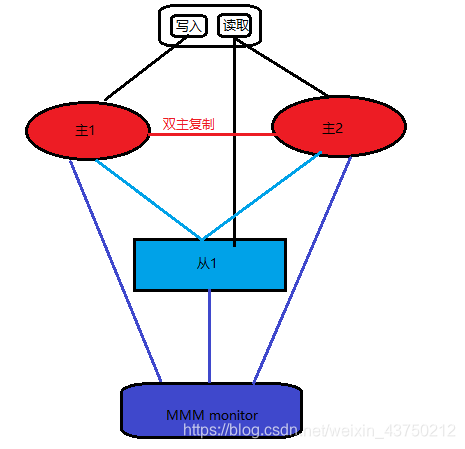
Note: double master node here, although called a dual-master replication, but on the same time services allow only one master write, to provide services on another portion of the read main Alternatively, the main alternative to accelerate the main switching timing in the main preheating.
On all cluster program, its advantages are:
- Automatic Failover primary master switch, generally less than 3s handover preparation machine.
- Multiple load-balancing read from the node.
The disadvantage is as follows:
- We can not fully ensure data consistency. The main hang 1, MMM monitor 2 has been switched to the main up, but at this time if the double-master replication, the master behind the main data 1 2 (i.e., has not been fully copied), the main case 2 has become the master of node, provide external writing services, resulting in inconsistent data.
- Because it is a floating virtual IP technology, similar Keepalived, so RIP (Real IP) to and VIP (Virtual IP) on the same network segment. If you are in different segments you can also, need to use virtual routing technology. But absolutely must be in the same room IDC, IDC room can not be set up across the cluster.
5, MHA
MHA is based on MySQL Replication, optimize it.
MHA (Master High Availability) is a multi-master multi-slave structure, which is Japan's DeNA youshimaton development, mainly to provide more primary node, but the lack of VIP (virtual IP), need to be used together keepalived and so on.
To build the MHA, replication requires a cluster must have at least three database servers, two from a master, i.e., to act as a master, acting as a backup master, the other one acts as the repository.
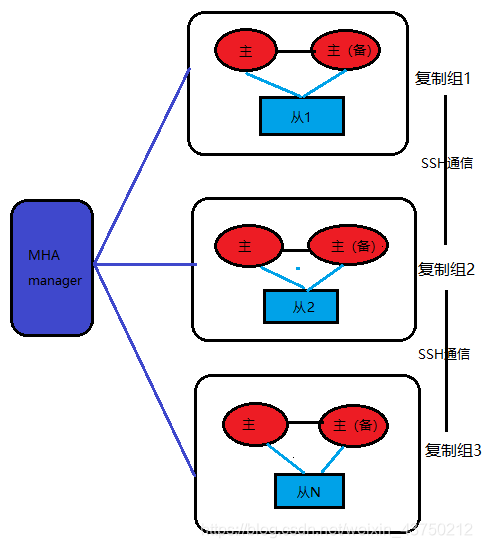
On all cluster program, its advantages are:
- You can automatically detect faults and transfer
- With automatic compensation data capabilities to ensure the greatest degree of consistency of data in the main library exceptions crash.
The disadvantage is as follows:
-
MHA architecture for read and write separation, best practices in application development and design issues when planning ahead to read and write separation, two connection pool in use, that is, read and write connection pool connection pool, you can choose a compromise that is introduced in SQL Proxy. But in any case need to change the code;
-
Load balancing may be used for the read F5, LVS, HAPROXY SQL Proxy or the like tools, as long as the read and write after peeling load balancing, and fault checking function to prepare new master recommended LVS
6, Galera Cluster
Galera Cluster Codership developed by MySQL multi-master cluster structure, the master node to each other node from the other nodes. Different from the main MySQL from native asynchronous replication, Galera uses a synchronous multi-master replication and synchronization for replication, transactional conflict and deadlock large probability of optimized replication is not based on official Galera replication binlog but plug , rewritten wsrep api.
Asynchronous replication, the main library will be propagated to update data from the database transaction is committed immediately, regardless of whether or reproducing successfully read data changes from the library. In this case, the main library shortly after the transaction is committed, not consistent master data from the library.
When synchronous replication, a single transaction to update the main library need to synchronize updates from the library at all. In other words, when the primary database transaction is committed, all nodes in the cluster data is consistent.
For read operations, reading data from each node is the same. For a write operation, when data is written to a node, which will synchronize the cluster to other nodes.

On all cluster program, its advantages are:
- Multi-master to live, to any node can read and write, even if a node hung up, read and write does not affect other nodes do not need to do a failover operation, without interrupting the entire cluster to provide both service.
- Excellent scalability, the new node will automatically pull data online node (when a new node joins the cluster will choose a Donor Node to provide data for new node), and ultimately all the same cluster node data, without the need for manual backup restore .
The disadvantage is as follows:
- Strong data consistency can do, no doubt, it is also based on the expense of performance.
Third, relying on hardware with
Host of different data synchronization is no longer dependent on MySQL's native replication capabilities, but through synchronous disk data to ensure data consistency.
Then failure is handled by means of Heartbeat, which monitor and manage network connections between the various nodes, and monitor cluster services, or when a node failure occurs when the service is unavailable, the cluster service to start automatically in other nodes.
7,heartbeat+SAN
SAN: shared storage, a main library from the library storage use. SAN concept is to allow storage and a high-speed resolver establish direct connection between the (server), which is connected via a centralized data storage implementation.
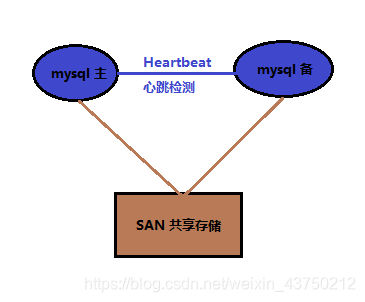
On all cluster program, its advantages are:
-
Ensure strong data consistency;
-
And decoupling mysql, not because of logical data inconsistencies mysql error occurs;
The disadvantage is as follows:
- SAN expensive;
8,heartbeat+DRDB
DRDB: This is a fast-level synchronous replication technology sector linux kernel implementation. Through the network between the host computer, copy the contents of the other disk. When the client writes data to the local disk, it will also send data to another host in the network disk, such as a local host (master) and the remote host (node apparatus) i.e., data synchronization can be guaranteed out.
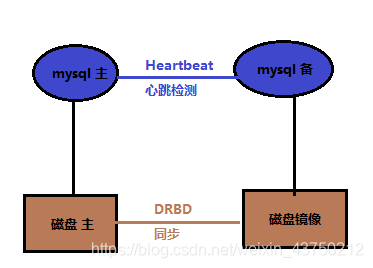
On all cluster program, its advantages are:
-
Compared to SAN storage network, low prices;
- Ensure strong data consistency;
-
And decoupling mysql, not because of logical data inconsistencies mysql error occurs;
The disadvantage is as follows:
-
Io greater impact on performance;
-
Does not provide a read operation from the library;
Fourth, other
9,Zookeeper + proxy
Zookeeper using distributed clustering algorithm to ensure data consistency, use zookeeper can effectively guarantee the high availability of proxy, can better avoid the network partition phenomenon.
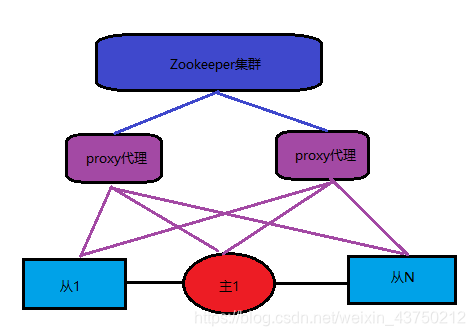
On all cluster program, its advantages are:
- Better scalability, can be extended to large clusters.
Its disadvantage is the lack of:
- Zookeeper set up a cluster in the configuration of a proxy, the logic of the whole system becomes more complex.
10,Paxos
Distributed consensus algorithm, Paxos algorithm problem is how to deal with a distributed system to agree on a value (resolution). This algorithm is considered to be the most effective kind of algorithm. Paxos and MySQL combined with strong consistency can be achieved in a distributed MySQL data.