Spike system
Spike system has the following difficulties:
- Good experience, 404 system error, system error does not occur timeout
- Instantaneous high concurrent flow
FIG lower structure of the general Internet services:
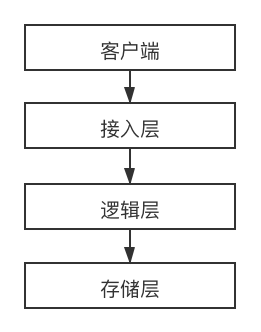
the user to do an action, usually through the access layer and logical layer, and then to the storage layer. We reduce the amount of data requested by the access layer, and then we reduced by the logical layer, such layers decreasing, the pressure request to the storage layer of the very small.
Reading & Writing spike system is less the case, we can use the cache.
Average user spike fails, the frequent retries, it will intensify the pressure back end. Retry strategy need to determine, for example, we limit the users within a certain number of seconds in the front of the request can only be submitted once. But such a strategy can only be stopped by ordinary users, the programmer is able to prevent.
We can intercept the access layer, the request count and weight according to uid. A uid, within a certain number of seconds can only submit one request. How to do that for other requests? Cache, you can, for repeated requests to return the same page by page caching to ensure a good user experience (no 404), but also to ensure the robustness of the system (make good use of the page cache, the request interception). But the cache may bring inconsistent data, because there are multiple sites. But some high-end programmers, control broiler requesting how to do (to not consider the issue of real-name system). Access layer needs to be increased expansion machine, may be necessary to abandon the request, for example, 70% of the requests to return directly try again later.
Intercept logical layer, via the request queue. Or using memcached redis Kangzhu request.
Of course, sometimes you can also do some optimization of business rules.
For example, time segments to different users open request. For example, the first spike into several times, so avoid requesting too concentrated, different users can choose different time periods to request (limit each user can only buy once).
Further, the data on the particle size. We know that users generally have not only concerned, without regard to how many there are. So in the granularity of the data, to make a coarse-grained "Yes" "No" button.
Too many requests, we can request the user randomly discarded in the front.
User authentication, users are not eligible for direct return, already carved up the user returns.
Be frequency-controlled single-user / single IP, to prevent a malicious user.
Logic spike

to sum up
Mainly in the following two points:
- The request interceptor system in the upper
- Reading and writing less use of cache
