REVIEW: Apache Druid is a set of time-series databases, data warehouses, and full-text retrieval system features in one of the analytical data platform. This article will take you to simply understand the characteristics of the Druid, usage scenarios, technical features and architecture. This will help you to store program data selection, in-depth understanding of Druid storage, in-depth understanding of time-series storage.
Apache Druid is a high-performance real-time analysis database.
Overview
-
A modern cloud native, native stream, analytical database
Druid is for quick queries and fast data ingestion workflow and design. Druid strong in a strong UI, operational query is run, and high-performance concurrent processing. Druid can be considered as a substitute for open source to meet diverse user data warehouse scenarios.
-
Easy integration with existing data pipelines
Druid message bus may be acquired from the streaming data (e.g., Kafka, Amazon Kinesis), or from the data file Lake bulk load (e.g. HDFS, Amazon S3, and other similar data sources).
-
100 times faster than conventional solutions performance
Druid benchmark data query for data intake and greatly exceeds traditional solutions.
Druid's architecture combines the data warehouse, the best characteristics of time series database and retrieval system.
-
Unlock new workflow
Druid for the Clickstream, APM (application performance management system), supply chain (supply chain), network telemetry, digital marketing and other event-driven scenarios to unlock new ways to search and workflow. Druid designed for rapid ad hoc queries in real-time and historical data and build.
-
Deployed on AWS / GCP / Azure, hybrid cloud, k8s and rental server
Druid * NIX can be deployed in any environment. Whether internal environment or cloud environments. Druid deployment is very easy: the expansion to volume reduction by the addition or deletion of service.
scenes to be used
Apache Druid suitable for real-time data extraction, high performance and high availability requirements of a high query scene. Thus, as it is usually Druid analysis system having a GUI rich, or as a background requires high concurrent rapid polymerization API. Druid is more suitable for the event data.
The more common usage scenarios:
-
Click stream analysis (web and mobile analysis)
-
Risk control analysis
- Telemetry network analysis (Network Performance Monitor)
- Storage server metrics
- Supply Chain Analysis (manufacturing index)
- Application Performance
- Business Intelligence / OLAP analysis system for real-time online
The following will analyze in detail these usage scenarios:
User activity and behavior
Druid often used in the click-stream, stream access, and streaming activity data. Specific scenarios include: measure user engagement, release tracking A / B test data for the product, and understand how users use. Druid approximate calculation can be done accurately and user indicators, for example, count index will not be repeated. This means that, as Nikkatsu user can calculate the approximate value index (average accuracy of 98%) to view the overall trend, or precisely calculated to demonstrate to stakeholders in a second. Druid can be used for "funnel analysis" to measure how many users do some action, but did not do another operation. This is useful for product tracking registered users.
Network flow
Druid often used to collect and analyze network flow data. Druid be used to manage the flow of data in any combination of segmentation attribute. Druid is able to extract a lot of network flow records, and quickly to dozens of combinations and ordering property, which helps network flow analysis at query time. These properties include some of the core attributes such as IP and port number, including some additional add enhanced properties, such as location, services, applications, devices and ASN. Druid can handle non-stationary mode, which means you can add any properties you want.
digital marketing
Druid often used to store and query data online advertising. These data usually come from advertising service provider, and understand its measure campaign results, click on the penetration, conversion rate (consumption) and other indicators is essential.
Druid was originally designed to be a powerful user-oriented analytical data for advertising applications. In terms of advertising data storage, Druid has a large number of production practice, a large number of users around the world PB-level data stored on thousands of servers.
Application Performance Management
Druid often used to track the application may generate operational data. And user activity using a similar scenario, these data can be about how user and application interaction, which can be an indicator of the data reported by the application itself. Druid drill can be used to discover how the properties of different components of the application, locating bottlenecks, and identify problems.
Unlike many conventional solutions, Druid has a smaller memory capacity, less complexity characteristics, greater data throughput. It can quickly analyze thousands attribute application events, and the computational complexity of the load, performance and utilization metrics. For example, 95 percent based on the query API terminal delays. We can be divided in any organization and cut temporary attribute data, such as in days segmentation data for the time, such as statistical portrait of the user, such as by data center location statistics.
Things indicators and equipment
Driud as time-series database solutions to store index data processing apparatus and the server. Collect real-time machine-generated data, perform a quick interim analysis, to measure performance, optimize hardware resources, and locate faults.
Many different traditions and time-series database, the Druid is essentially an analysis engine. Druid combines the time-series database, column-based database concept analysis, and retrieval system. It supports time-based partitioning, columnar storage, indexing and search in a single system. This means that the time of the inquiry, digital convergence, filtering based on the query and retrieval will be particularly fast.
You can include one million unique dimension values in your indicators, and in any random combination of dimensions (dimension dimension Druid is similar to time-series database tag) group and filter. You can tag group and based on rank, and calculate the number of complex indicators. And you can search and filter faster than traditional time-series database on the tag.
OLAP and Business Intelligence
Druid often used for business intelligence scenarios. The company deployed Druid to speed up queries and enhanced applications. Based on Hadoop and SQL engine (such as Presto or Hive) different, Druid high concurrency and sub-second query design, enhanced by interactive UI data query. This makes the Druid is more suitable for real visual interactive analysis.
technology
Apache Druid is an open source distributed data storage engine. Druid's core design combines OLAP analytic databases, timeseries database, and ideas / search systems in order to create a unified system suitable for a wide range of use cases. Druid main features of these three kinds of systems integration into the Druid's ingestion layer (data ingestion layer), storage format (formatted storage layer), querying layer (query layer), and core architecture (Core architecture) in.
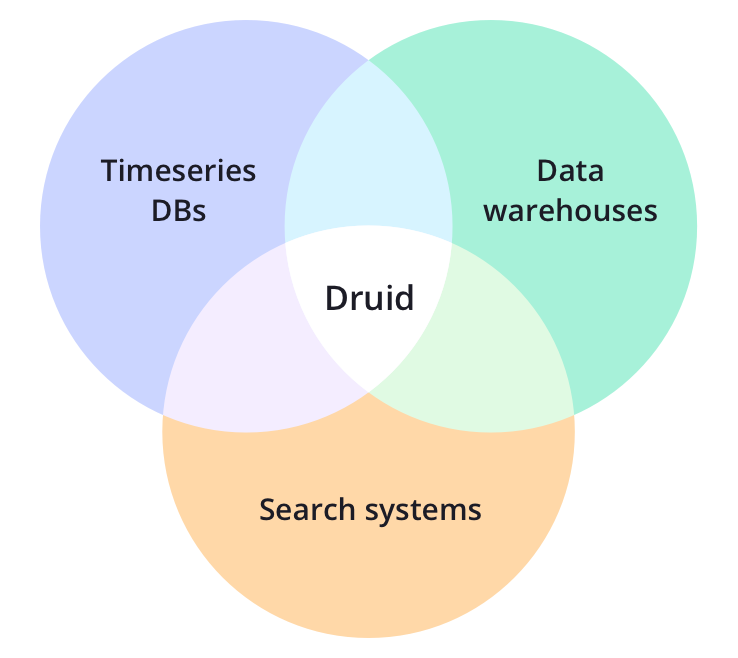
Druid's main features include:
-
Columnar storage
Druid compressed and stored separately for each column of data. And the query query only need to query specific data, enabling fast scan, ranking and groupBy.
-
Native retrieval index
Druid to create an inverted index for the string value in order to achieve fast searching and filtering data.
-
Streaming and bulk data ingestion
Out of the box Apache kafka, HDFS, AWS S3 connector connectors, flow processor.
-
Flexible data model
Druid gracefully adapt to changing data types and nested data pattern.
-
Partition-based optimization of time
Druid time-based intelligent data partition. Therefore, Druid-based query time will be significantly faster than traditional databases.
-
Support of SQL statements
In addition to the native JSON based outside inquiry, Druid also supports HTTP and JDBC SQL.
-
Level scalability
Data ingestion rate one million / sec, mass data storage, sub-second query.
-
Ease of operation and maintenance
Accommodating expansion and contraction may be added or removed by the Server. Druid supports automatic re-balancing, failover.
Data intake
Druid supports both streaming and bulk data intake. Typically Druid (loading streaming data), or through a distributed file system such as the HDFS (loading bulk data) such as by Kafka message bus connecting the original data source.
Indexing Druid by processing the raw data stored in the segment data node manner, the query optimizer segment is a data structure.
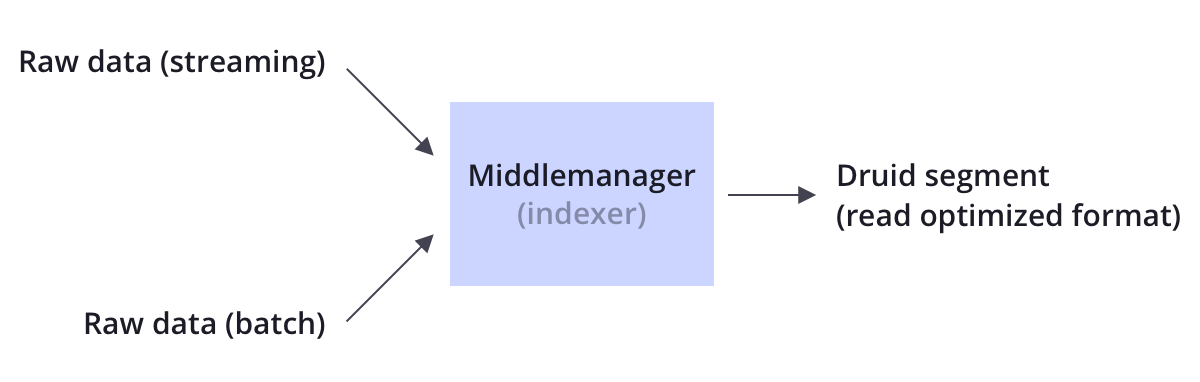
data storage
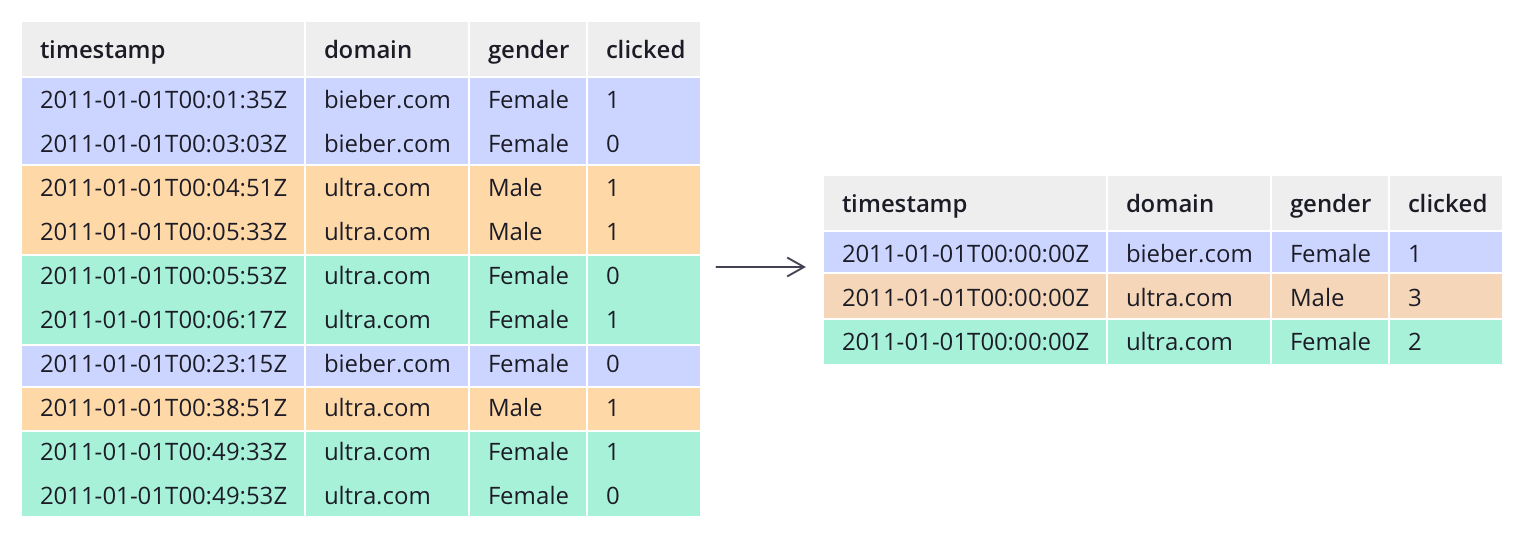
像大多数分析型数据库一样,Druid采用列式存储。根据不同列的数据类型(string,number等),Druid对其使用不同的压缩和编码方式。Druid也会针对不同的列类型构建不同类型的索引。
类似于检索系统,Druid为string列创建反向索引,以达到更快速的搜索和过滤。类似于时间序列数据库,Druid基于时间对数据进行智能分区,以达到更快的基于时间的查询。
不像大多数传统系统,Druid可以在数据摄入前对数据进行预聚合。这种预聚合操作被称之为rollup,这样就可以显著的节省存储成本。
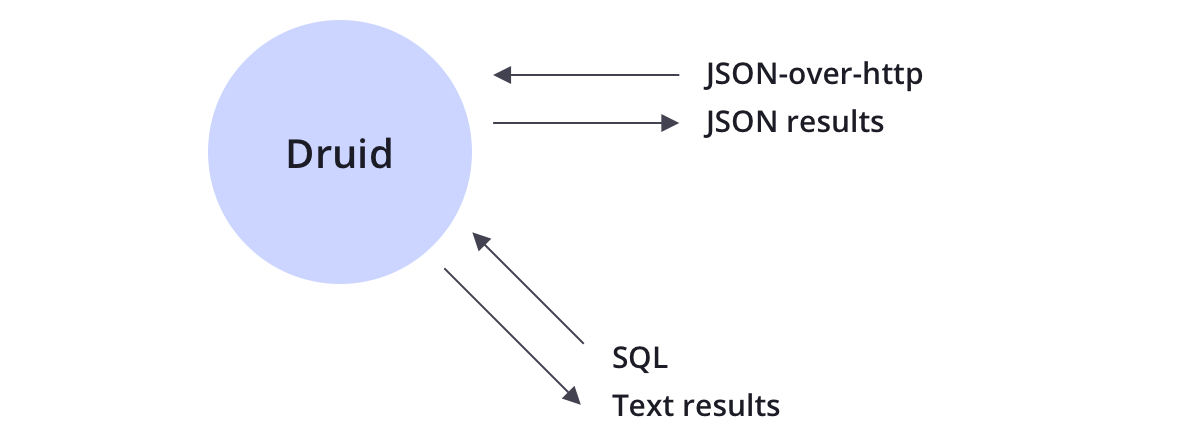
查询
Druid支持JSON-over-HTTP和SQL两种查询方式。除了标准的SQL操作外,Druid还支持大量的唯一性操作,利用Druid提供的算法套件可以快速的进行计数,排名和分位数计算。
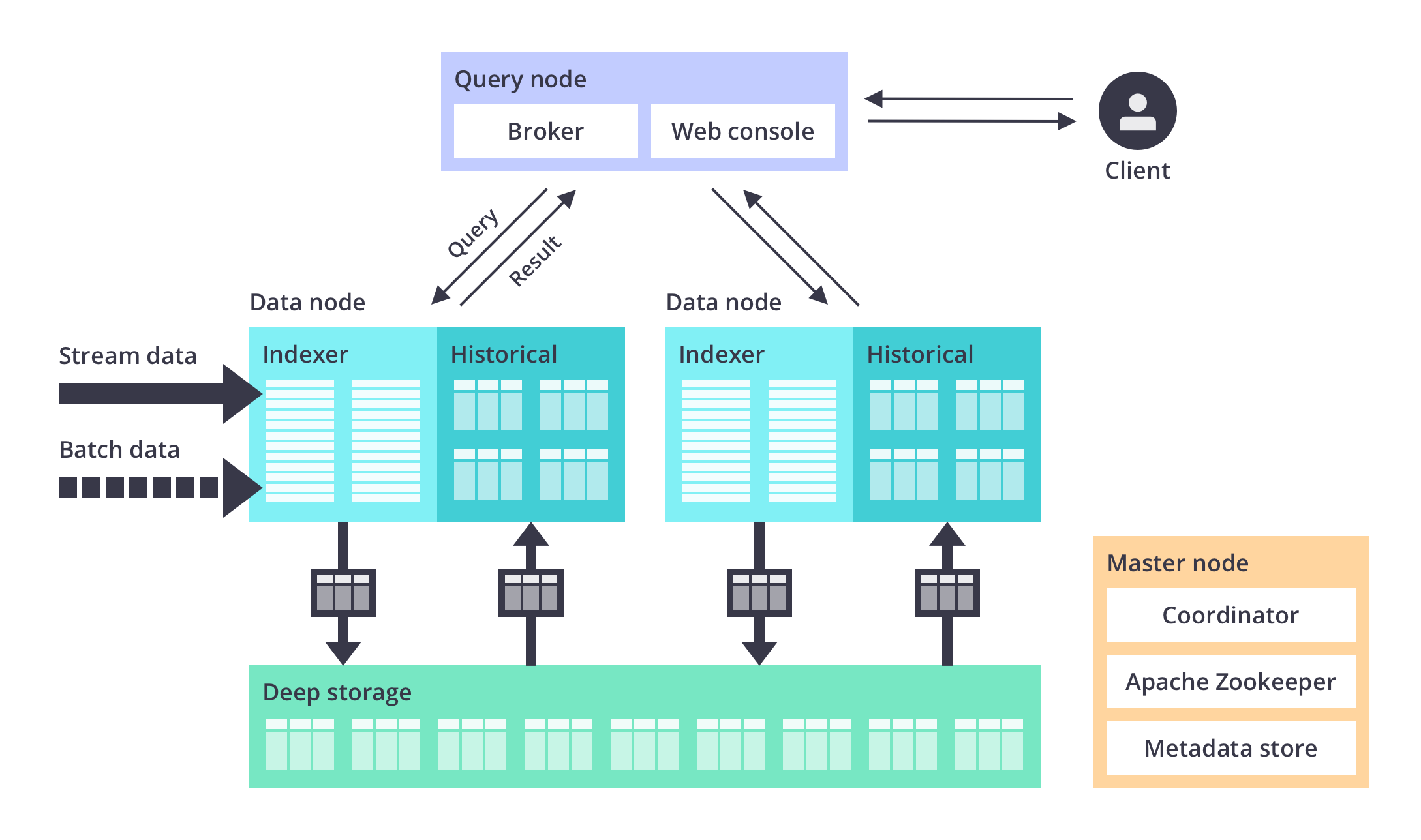
架构
Druid是微服务架构,可以理解为一个拆解成多个服务的数据库。Druid的每一个核心服务(ingestion(摄入服务),querying(查询服务),和coordination(协调服务))都可以单独部署或联合部署在商业硬件上。
Druid清晰的命名每一个服务,以确保运维人员可以根据使用情况和负载情况很好地调整相应服务的参数。例如,当负载需要时,运维人员可以给数据摄入服务更多的资源而减少数据查询服务的资源。
Druid可以独立失败而不影响其他服务的运行。
运维
Drui被设计成一个健壮的系统,它需要7*24小时运行。Druid拥有以下特性,以确保长期运行,并保证数据不丢失。
-
数据副本
Druid根据配置的副本数创建多个数据副本,所以单机失效不会影响Druid的查询。
-
独立服务
Druid清晰的命名每一个主服务,每一个服务都可以根据使用情况做相应的调整。服务可以独立失败而不影响其他服务的正常运行。例如,如果数据摄入服务失效了,将没有新的数据被加载进系统,但是已经存在的数据依然可以被查询。
-
自动数据备份
Druid automatic backup of all the data has been indexed to a file system, it may be a distributed file system, such as HDFS. You can lose all the data Druid cluster, and quickly reloaded from the backup data.
-
Rolling updates
By rolling updates, you can update Druid cluster without downtime, so the user is not aware of. All Druid versions are backward compatible.
For time-series database and contrast, can be the venue for another article:
Time sequence database (TSDb of) the selected acquaintance
Follow us public number, you can get more series
