This paper summarizes the respective blog
And the ratio of the cross (Intersection over Union) and non-maxima suppression is (Non-Maximum Suppression) two target detection task is very important concept. For example, when tested with the trained model, the network will predict a series of candidate box. This time we will use NMS to remove some of the extra frame candidates. That is, remove some IOU value is greater than a certain threshold box. Then the rest of the candidate box IOU values were calculated with the ground truth is usually a predetermined value when the candidate block and the IOU ground truth is greater than 0.5, it is considered correctly detected. Here we were with a python achieve IOU and NMS.
And the ratio of the cross IOU

shown above, the value IOU positioned ratio of the area of the intersection of two rectangular frame and the union. Namely:
IOU = A∩BA∪B
Non-maxima suppression (the NMS)
the NMS steps of the algorithm are as follows:
#INPUT: All predicted bounding box (bbx) information (coordinates and confidence confidence), IOU threshold value (greater than BBX the threshold will be removed)
for Object in All Objects:
(. 1) acquires all current BBX next target category information
(2) in accordance with the confidence BBX descending sort, and record the current maximum confidence BBX
(. 3) corresponding to the calculated maximum confidence BBX BBX with all the remaining IOU, IOU remove all BBX greater than the threshold value
(4 ) for the rest of the bbx, loop execution (2) and (3) bbx until all requirements are met (ie can not be removed bbx)
Note that, NMS is performed separately for all categories. For chestnuts, assuming the final predicted rectangle There are 2 types (respectively cup, pen), before the NMS, each class will likely have more than one bbx be predicted at this time we are required to perform these two categories once NMS process.
We NMS codes written in python, assume for a picture, all bbx information has been saved in
[Original Address] text: https://blog.csdn.net/sinat_34474705/article/details/80045294
------- -----------------------------Dividing line------------------- ---------------------------
Then the detection results are divided into the following situations:
For real face, that positive samples, which is the red line area:
True positive (TP): the right of positive samples, namely detector found a human face, Perfect!
False negative (FN): false negative samples, i.e., the detector area of the face as non-face rejected, corresponding to missing
background region other than for the red line, i.e., negative samples:
True negative (the TN): Detection is the background judgment became background, no problem
False positive (FP): the detector is not the face of goal as the face, also called false alarm
Figure:

test results with the actual situation is consistent with true:
the detection result is true the actual situation is also true that this is true Positive
test results for the fake, the actual situation is false, which is true negative
inconsistent test results with the actual situation is with false:
the test result is true, the reality is false, is to fake really called false positive, this is false Psositive
test result is false, the reality is true, that is, when the true false, missed call, this is false Negative
attempt to classify an example of the test results:
1 .TP: the reality is the human face, human face detection results, correct detection results
2.TN : the reality is that background, the test results as the background, correct detection results
3.FP: the reality is that background, human face detection results That is false detection
4.FN: The reality is that human face detection result as the background, that is missed
Calculate two indicators: accuracy Precision: correct representation of the total detection result of the detection result of the ratio (the total number of detected objects inside, test results is actually the total output of the final frame) of

the recall Rcall: indicates the proper face detection the results of the total should be detected by the human face (total face should be detected is actually correct the detected face plus undetected face) the proportion of
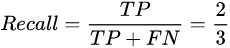
evaluating the quality of detector: ROC: (receiver operating characteristic curve , ROC curve for short), also known as sensitivity curve (sensitivity curve). ROC curve is the false positive probability (False positive rate) as the horizontal axis, true positive (True positive rate) consisting of a longitudinal axis of the coordinate FIG

defined AUC_ {ROC} as the area under the ROC curve, then 0 <= AUC_ {ROC } <=. 1
the AUC = Area Under the Curve
When AUC_ {ROC} = 1, perfect detector
when AUC_ {ROC} = 0.5, equivalent to guessing ...
Author: Sang Bai
links: https://www.zhihu.com/question/288198143/answer/482600906
Source: know almost
copyrighted by the author. Commercial reprint please contact the author authorized, non-commercial reprint please indicate the source.
-----------Dividing line--------------
Common 95% confidence level, how to understand it?
要理解置信度,就要理解好置信区间。要理解置信区间,就要从统计学最基本最核心的思想去思考,那就是用样本估计总体。在统计学中,非常容易把概念模糊化,很容易把95%置信区间理解成为在这个区间内有95%的概率包含真值。但是这里有两个容易混淆的地方1.真值只得是样本参数还是总体参数?这个问题的答案是总体参数,我们取的数据是样本数据,点估计是样本参数的真实值,我们要估计总体参数。2.95%的概率,变动的是谁?在以后不常温习的情况下,这个问题容易造成困扰。这里95%的概率,变动的是置信区间。非常难以理解,用图来阐述一下:

错误理解:上图浅色的虚的竖直线代表样本参数真值,横的两端有端点的代表95%置信度的置信区间,100条竖直线里有95条左右落入这个区间内。这是非常错误的理解,样本与总体的关系没有思考清楚。置信区间是估测总体参数的真值,这个值只有一个,且不会变动。下图为正确理解:

样本数目不变的情况下,做一百次试验,有95个置信区间包含了总体真值。置信度为95%其中大虚线表示总体参数真值,是我们所不知道的想要估计的值。正因为在100个置信区间里有95个置信区间包括了真实值,所以当我们只做了一次置信区间时,我们也认为这个区间是可信的,是包含了总体参数真实值的。这样应该就能很好地理解了,遇到统计上的困惑时,多思考用样本估计总体这个核心思想,很多就能迎刃而解。
作者:邹日佳
链接:https://www.zhihu.com/question/20183513/answer/15023786
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
——————分割线——————
计算机视觉里常用的几个特征
Harr特征
LBP特征
HOG特征
SIFT特征
SURF特征
harr特征
Haar特征是一种反映图像的灰度变化的,像素分模块求差值的一种特征。它分为三类:边缘特征、线性特征、中心特征和对角线特征。用黑白两种矩形框组合成特征模板,在特征模板内用黑色矩形像素和减去白色矩形像素和来表示这个模版的特征值。例如:脸部的一些特征能由矩形模块差值特征简单的描述,如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等。但矩形特征只对一些简单的图形结构,如边缘、线段较敏感,所以只能描述在特定方向(水平、垂直、对角)上有明显像素模块梯度变化的图像结构。

对于一幅图像来说,通过改变特征模板的大小和位置,可穷举出大量的特征来表示一幅图像。上图的特征模板称为“特征原型”;特征原型在图像子窗口中扩展(平移伸缩)得到的特征称为“矩形特征”;矩形特征的值称为“特征值”。
LBP特征
LBP(Local Binary Pattern)指局部二值模式,是一种用来描述图像局部特征的算子,LBP特征具有灰度不变性和旋转不变性等显著优点。它是由T. Ojala, M.Pietikäinen, 和 D. Harwood在1994年提出,由于LBP特征计算简单、效果较好,因此LBP特征在计算机视觉的许多领域都得到了广泛的应用,LBP特征比较出名的应用是用在人脸识别和目标检测中,在计算机视觉开源库Opencv中有使用LBP特征进行人脸识别的接口,也有用LBP特征训练目标检测分类器的方法,Opencv实现了LBP特征的计算,但没有提供一个单独的计算LBP特征的接口。
原始的LBP算子定义在像素33的邻域内,以邻域中心像素为阈值,相邻的8个像素的灰度值与邻域中心的像素值进行比较,若周围像素大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,33邻域内的8个点经过比较可产生8位二进制数,将这8位二进制数依次排列形成一个二进制数字,这个二进制数字就是中心像素的LBP值,LBP值共有28种可能,因此LBP值有256种。中心像素的LBP值反映了该像素周围区域的纹理信息。
备注:计算LBP特征的图像必须是灰度图,如果是彩色图,需要先转换成灰度图。
HOG特征
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。Hog特征结合SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。
在一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向密度分布很好地描述。(本质:梯度的统计信息,而梯度主要存在于边缘的地方)。
与其他的特征描述方法相比,HOG有很多优点。首先,由于HOG是在图像的局部方格单元上操作,所以它对图像几何的和光学的形变都能保持很好的不变性,这两种形变只会出现在更大的空间领域上。其次,在粗的空域抽样、精细的方向抽样以及较强的局部光学归一化等条件下,只要行人大体上能够保持直立的姿势,可以容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效果。因此HOG特征是特别适合于做图像中的人体检测的。
SIFT特征
尺度不变特征转换(Scale-invariant feature transform或SIFT)是一种电脑视觉的算法用来侦测与描述影像中的局部性特征,它在空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量,此算法由 David Lowe在1999年所发表,2004年完善总结。应用范围包含物体辨识、机器人地图感知与导航、影像缝合、3D模型建立、手势辨识、影像追踪和动作比对。此算法有其专利,专利拥有者为英属哥伦比亚大学。
局部影像特征的描述与侦测可以帮助辨识物体,SIFT 特征是基于物体上的一些局部外观的兴趣点而与影像的大小和旋转无关。对于光线、噪声、些微视角改变的容忍度也相当高。基于这些特性,它们是高度显著而且相对容易撷取,在母数庞大的特征数据库中,很容易辨识物体而且鲜有误认。使用 SIFT特征描述对于部分物体遮蔽的侦测率也相当高,甚至只需要3个以上的SIFT物体特征就足以计算出位置与方位。在现今的电脑硬件速度下和小型的特征数据库条件下,辨识速度可接近即时运算。SIFT特征的信息量大,适合在海量数据库中快速准确匹配。
SIFT算法的特点有:
- SIFT特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性;
- 独特性(Distinctiveness)好,信息量丰富,适用于在海量特征数据库中进行快速、准确的匹配;
- 多量性,即使少数的几个物体也可以产生大量的SIFT特征向量;
- 高速性,经优化的SIFT匹配算法甚至可以达到实时的要求;
- 可扩展性,可以很方便的与其他形式的特征向量进行联合。
SIFT算法可以解决的问题:
目标的自身状态、场景所处的环境和成像器材的成像特性等因素影响图像配准/目标识别跟踪的性能。而SIFT算法在一定程度上可解决: - 目标的旋转、缩放、平移(RST)
- 图像仿射/投影变换(视点viewpoint)
- 光照影响(illumination)
- 目标遮挡(occlusion)
- 杂物场景(clutter)
- 噪声
SIFT算法的实质是在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT所查找到的关键点是一些十分突出,不会因光照,仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。
Lowe将SIFT算法分解为如下四步:
- 尺度空间极值检测:搜索所有尺度上的图像位置。通过高斯微分函数来识别潜在的对于尺度和旋转不变的兴趣点。
- 关键点定位:在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。
- 方向确定:基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
- 关键点描述:在每个关键点周围的邻域内,在选定的尺度上测量图像局部的梯度。这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变化。
SURF特征
Speeded Up Robust Features(SURF,加速稳健特征),是一种稳健的局部特征点检测和描述算法。最初由Herbert Bay发表在2006年的欧洲计算机视觉国际会议(Europen Conference on Computer Vision,ECCV)上,并在2008年正式发表在Computer Vision and Image Understanding期刊上。
Surf是对David Lowe在1999年提出的Sift算法的改进,提升了算法的执行效率,为算法在实时计算机视觉系统中应用提供了可能。与Sift算法一样,Surf算法的基本路程可以分为三大部分:局部特征点的提取、特征点的描述、特征点的匹配。
但Surf在执行效率上有两大制胜法宝——一个是积分图在Hessian(黑塞矩阵)上的使用,一个是降维的特征描述子的使用。
八、人脸检测的评估方法
在不断对人脸检测器进行改进的过程中,有一个问题是不容忽视的:如何科学地比较两个人脸检测器的优劣?简单地说,出一套考题让所有的检测器进行一场考试,谁得分高谁就更好。对于人脸检测器而言,所谓考题(测试集)就是一个图像集合,通常其中每张图像上都包含至少一张人脸,并且这些人脸的位置和大小都已经标注好。关于得分,需要考虑检测器两方面的表现,一是检测率,也即对人脸的召回率,检测出来的人脸占总人脸的比例——测试集中一共标注了100张人脸,检测器检测出其中70张人脸,则检测率为70%;二是误检(也称为虚警)数目,即检测器检测出来的人脸中出现错误(实际上不是人脸)的数目——检测器一共检测出80张人脸,然而其中有10个错误,只有70个是真正的人脸,那么误检数目就是10。在这两个指标上,我们所希望的总是检测率尽可能高,而误检数目尽可能少,但这两个目标之间一般是存在冲突的;在极端的情况下,如果一张脸也没有检测出来,那么误检数目为0,但是检测率也为0,而如果把所有的窗口都判别为人脸窗口,那么检测率为100%,而误检数目也达到了最大。在比较两个检测器的时候,我们通常固定一个指标,然后对比另一个指标,要么看相同误检数目时谁的检测率高,要么看相同检测率时谁的误检少。
对于每一个检测出的人脸,检测器都会给出这个检测结果的得分(或者说信度),那么如果人为地引入一个阈值来对检测结果进行筛选(只保留得分大于阈值得检测结果),那么随着这个阈值的变化,最终得检测结果也会不同,因而其对应得检测率和误检数目通常也会不同。通过变换阈值,我们就能够得到多组检测率和误检数目的值,由此我们可以在平面直角坐标系中画出一条曲线来:以x坐标表示误检数目,以y坐标表示检测率,这样画出来的曲线称之为ROC曲线(不同地方中文译法不一,如接收机曲线、接收者操作特征曲线等,这里直接采用英文简写)。ROC曲线提供了一种非常直观的比较不同人脸检测器的方式,得到了广泛的使用。
评测人脸检测器时还有一个重要的问题:怎么根据对人脸的标注和检测结果来判断某张人脸是否被检测到了?一般来说,检测器给出的检测框(即人脸窗口)不会和标注的人脸边框完全一致,而且对人脸的标注也不一定是矩形,例如还可能是椭圆形;因此当给定了一个检测框和一个标注框时,我们还需要一个指标来界定检测框是否和标注框相匹配,这个指标就是交并比:两者交集(重叠部分)所覆盖的面积占两者并集所覆盖面积的比例,一般情况下,当检测框和标注框的交并比大于0.5时,我们认为这个检测框是一个正确检测的人脸。
在早期的人脸检测工作中,一般采用MIT-CMU人脸检测数据集作为人脸检测器的测试集,来比较不同的检测器。这个测试集只包含几百张带有人脸的图像,并且人脸主要是清晰且不带遮挡的正面人脸,因而是一个相对简单的测试集,现在几乎已经不再使用。在2010年,美国麻省大学的一个实验室推出了一个新的人脸检测评测数据集:FDDB,这个集合共包含2845张带有人脸的互联网新闻图像,一共标注了5171张人脸,其中的人脸在姿态、表情、光照、清晰度、分辨率、遮挡程度等各个方面都存在非常大的多样性,贴近真实的应用场景,因而是一个非常具有挑战性的测试集。FDDB的推出激发人们在人脸检测任务上的研究热情,极大地促进了人脸检测技术的发展,在此后的几年间,新的人脸检测方法不断涌现,检测器在FDDB上的表现稳步提高。从100个误检时的检测率来看,从最初VJ人脸检测器的30%,发展到现在已经超过了90%——这意味着检测器每检测出50张人脸才会产生一个误检,这其中的进步是非常惊人的,而检测器之间的比拼还在继续。
九、人脸检测技术的发展现状
自动人脸检测技术是所有人脸影像分析衍生应用的基础,这些扩展应用细分有人脸识别、人脸验证、人脸跟踪、人脸属性识别,人脸行为分析、个人相册管理、机器人人机交互、社交平台的应用等。
从应用领域上可以分为:①以企事业单位管理及商业保密为主的商用人脸检测;②大规模联网布控的多角度多背景的安防人脸检测;③反恐安全、调查取证、刑事侦查为主的低分辨率尺度多样的军用/警用人脸检测;④当然还有基于互联网社交娱乐应用等的一般人脸检测。
在学术研究中分为约束环境人脸检测和非约束环境人脸检测,如下图。

所谓人脸检测,就是给定任意一张图片,找到其中是否存在一个或多个人脸,并返回图片中每个人脸的位置和范围。人脸检测的研究在过去二十年里取得了巨大进步,特别是Viola and Jones提出了开创性算法,他们通过Haar-Like特征和AdaBoost去训练级联分类器获得实时效果很好的人脸检测器,然而研究指出当人脸在非约束环境下,该算法检测效果极差。这里说的非约束环境是对比于约束情况下人脸数单一、背景简单、直立正脸等相对理想的条件而言的,随着人脸识别、人脸跟踪等的大规模应用,人脸检测面临的要求越来越高(如上图):人脸尺度多变、数量冗大、姿势多样包括俯拍人脸、戴帽子口罩等的遮挡、表情夸张、化妆伪装、光照条件恶劣、分辨率低甚至连肉眼都较难区分等。用经典VJ人脸检测器(2010年更新)在非约束评测集FDDB中验证显示:当限定误检数为10个时,准确率不超过10%;为500个时,检测率仅仅为52.8%。所以丞待更好的算法以应用于大规模安防布控等非约束人脸检测场景。
14年底微软美国研究院首席研究员张正友等在CVIU上发表了非约束人脸检测专题综述,文中指出过去十年里,当限定误检数为0或不超过10个时,人脸检测算法的查准率也就是准确率(true positive rate)提高了65%之多(最新基于CNN的算法和传统Vj-boosting算法的对比结果)。
文中总结了现今出现的优异算法主要得益于以下四点:
①越来越多的鲁棒特征提取方法:LBP、SIFT、HOG、SURF、DAISY等;
②开放的数据库和评测平台:LFW、FDDB(报告中性能对比主要用的一个,更新于2016.4.15)、WIDER(汤晓欧团队发布的,更新于2016.4.17,不完整);
③机器学习方法的发展和应用:boosting、SVM、深度学习等;
④高质量的开源视觉代码库的良好发展与维护:OpenCV、DPM、深度学习框架-caffe等。
人脸检测算法以往被分为基于知识的、基于特征的、基于模板匹配的、基于外观的四类方法。随着近些年DPM算法(可变部件模型)和深度学习CNN(卷积神经网络)的广泛运用,人脸检测所有算法可以总分为两类:①Based on rigid templates:代表有boosting+features和CNN ②Based on parts model:主要是DPM。
基于深度学习的人脸检测方法可以作为第一类方法的代表,同时也是检测某一种深度学习架构或新方法是否有效的评测标准。往往一个简单的卷积神经网络在人脸检测就能获得很好效果,同时有文献验证了深度卷积神经网络的第一层特征和SIFT类型特征极其相似。
DPM算法由Felzenszwalb于2008年提出的一种基于部件的检测方法,对目标的形变具有很强的鲁棒性,目前已成为分类、分割、动态估计等算法的核心组成部分。应用DPM的算法采用了改进后的Hog特征、SVM分类器和滑动窗口检测思想,在非约束人脸检测中取得极好效果。而其缺点主要是计算复杂度过高。
随着DNN的发展,基于深度学习的方法获得了state of art的效果,可见未来人脸检测算法主要的发展将围绕DPM和DCNN展开。同时将DPM和DCNN结合的方法也将是研究趋势。
在实际中,作为安防企业,人脸检测(识别)技术的研发应用在两方面:
1.基本的人脸考勤和门禁等,这一类属于有约束情况,用传统改进算法足以满足性能;
2.安防实时监控,智能视频人脸分析,海量人脸搜索验证、人群数量统计,防踩踏预警等,这类属于非约束情况,不仅对检测算法的精度(包括误检率)要求很高,而且要确保实时性。
调研发现,人脸检测(识别)实战的场景逐渐从室内演变到室外,从单一路况发展到广场、车站、地铁口等。目前基于后者场景,精度若能稳定达到80%以上就属于顶尖技术了(很难达到)。可以想象,雾霾天戴着口罩,冬天戴着帽子,夏天戴着墨镜等,传统算法的检测是比较难的。
十、深度学习与目标检测
人脸检测作为一种特定类型目标的检测任务,一方面具有其自己鲜明的特点,需要考虑人脸这一目标的特殊性,另一方面其也和其它类型目标的检测任务具有一定的共性,能够直接借鉴在通用目标检测方法上的研究经验。
目标检测任务作为一个分类问题,其不仅受益于计算机视觉领域相关技术的不断发展,在机器学习领域的研究进展同样也对目标检测任务具有推波助澜的作用。事实上,从2006年开始逐步蔓延开的深度学习大爆发给目标检测的研究带来了强劲的助推力,使得通用的目标检测以及各种特定类型目标的检测任务得到了跨越式地发展。
R-CNN
在2013年底,深度学习给目标检测任务点起了一把火,这个火种就是R-CNN,其中R对应于“Region(区域)”,意指CNN以图像区域作为输入,这个工作最终发展成了一个系列,也启发和衍生出了大量的后续工作,这一场大火简直烧红了计算机视觉领域的半边天。
R-CNN的提出变革了目标检测方法中很多旧有的做法,同时在标准的目标检测评测数据集上使检测精度得到了前所未有的提升。在检测方法上的变革,首当其冲的是抛弃了滑动窗口范式,取而代之的是一个新的生成候选窗口的环节。对于给定的图像,不再用一个滑动窗口去对图像进行扫描,枚举所有可能的情况,而是采用某种方式“提名”出一些候选窗口,在获得对待检测目标可接受的召回率的前提下,候选窗口的数量可以控制在几千个或者几百个。从某种意义上讲,VJ 人脸检测器中多个分类器相级联,每一级分类器都在为接下来的一级分类器提名候选窗口,但是这和 R-CNN 所采用的生成候选窗口的方式有一个重要的区别:实际上所有的窗口仍然都被检查了一遍,只是不断在排除,这是一种减法式的方案。相比之下,R-CNN 采用的候选窗口生成方式,是根据图像的某些特征来猜测可能有哪些地方存在待检测的目标,以及这些目标有多大,这是一种从无到有的加法式的方案。Selective Search是一种典型的候选窗口生成方法,其采用了图像分割的思路,简单地说,Selective Search方法先基于各种颜色特征将图像划分为多个小块,然后自底向上地对不同的块进行合并,在这个过程中,合并前后的每一个块都对应于一个候选窗口,最后挑出最有可能包含待检测目标的窗口作为候选窗口。
除了引入候选窗口生成方法,第二点非常大的改变在特征提取上:不再采用人工设计的特征,而是用CNN来自动学习特征。特征提取过程就是从原始的输入图像(像素颜色值构成的矩阵)变换到特征向量的过程,之前的如Haar 特征等是科研工作者根据自己的经验和对研究对象的认识设计出来的,换言之人工定义了一个变换,而新的做法是只限定这个变换能够用CNN来表示——事实上CNN 已经可以表示足够多足够复杂的变换,而不具体设计特征提取的细节,用训练数据来取代人的角色。这种自动学习特征的做法是深度学习一个非常鲜明的特色。自动去学习合适的特征,这种做法的好处和让分类器自动去学习自己的参数的好处是类似的,不仅避免了人工干预,解放了人力,而且有利于学习到更契合实际数据和目标的特征来,特征提取和分类两个环节可以相互促进,相辅相成;不过缺点也是有的,自动学习出的特征往往可解释性比较差,不能让人直观地去理解为什么这样提取出特征会更好,另外就是对训练集会产生一定程度的依赖。
还有一点值得一提的是,R-CNN在检测过程中引入了一个新的环节:边框回归,检测不再仅仅是一个分类问题,它还是一个回归问题——回归和分类的区别就在于回归模型输出的不是离散的类别标签,而是连续的实数值。边框回归指的是在给定窗口的基础上去预测真实检测框的位置和大小,也就是说,有了候选窗口之后,如果其被判别成了一个人脸窗口,那就会进一步被调整以得到更加精确的位置和大小——和待检测目标贴合得更好。边框回归一方面提供了一个新的角度来定义检测任务,另一方面对于提高检测结果的精确度有比较显著的作用。
用R-CNN进行目标检测的流程是:先采用如 Selective Search等方法生成候选窗口,然后用学习好的CNN提取候选窗口对应的特征,接着训练分类器基于提取的特征对候选窗口进行分类,最后对判别为人脸的窗口采用边框回归进行修正。
虽然R-CNN带来了目标检测精度的一次巨大提升,然而由于所采用的候选窗口生成方法和深度网络都具有比较高的计算复杂度,因而检测速度非常慢。为了解决R-CNN的速度问题,紧接着出现了Fast R-CNN和Faster R-CNN,从名字上可以看到,它们的速度一个比一个快。
Fast R-CNN
第一步加速是采用了类似于 VJ 人脸检测器中积分图的策略,积分图是对应整张输入图像计算的,它就像一张表,在提取单个窗口的特征时,直接通过查表来获取所需要的数据,然后进行简单的计算即可,在R-CNN中每个候选窗口都需要单独通过CNN来提取特征,当两个窗口之间有重叠部分时,重叠部分实际上被重复计算了两次,而在 Fast R-CNN 中,直接以整张图像作为输入,先得到整张图对应的卷积特征图,然后对于每一个候选窗口,在提取特征时直接去整张图对应的卷积特征图上取出窗口对应的区域,从而避免重复计算,之后只需要通过所谓的RoIPooling层来将所有的区域放缩到相同大小即可,这一策略的使用可以提供几十甚至上百倍的加速。第二步加速,Fast R-CNN利用了一种名为 SVD 的矩阵分解技术,其作用是将一个大的矩阵(近似)拆解为三个小的矩阵的乘积,使得拆解之后三个矩阵的元素数目远小于原来大矩阵的元素数目,从而达到在计算矩阵乘法时降低计算量的目的,通过将 SVD应用于全连接层的权值矩阵,处理一张图片所需要的时间能够降低30%。
Faster R-CNN
第三步加速,Faster R-CNN开始着眼于生成候选窗口的环节,其采用 CNN 来生成候选窗口,同时让其和分类、边框回归所使用的 CNN 共享卷积层,这样使得两个步骤中可以使用同样的卷积特征图,从而极大地减少计算量。
除了采用各种策略进行加速,从R-CNN到Faster R-CNN,检测的框架和网络结构也在不断发生改变。R-CNN从整体框架上来说,和传统的检测方法没有本质区别,不同的环节由单独的模块来完成:一个模块生成候选窗口(Selective Search),一个模块进行特征提取(CNN),一个模块对窗口进行分类(SVM),除此之外还增加了一个模块做边框回归。到Fast R-CNN的时候,后面三个模块合并成了一个模块,全部都用CNN来完成,因此整个系统实际上只剩下两个模块:一个模块生成候选窗口,另一个模块直接对窗口进行分类和修正。再到Faster R-CNN,所有的模块都整合到了一个CNN中来完成,形成了一种端到端的框架:直接从输入图像通过一个模型得到最终的检测结果,这种多任务在同一个模型中共同学习的做法,能够有效利用任务之间的相关性,达到相辅相成、相得益彰的效果。
从 R-CNN 到 Faster R-CNN,这是一个化零为整的过程,其之所以能够成功,一方面得益于CNN强大的非线性建模能力,能够学习出契合各种不同子任务的特征,另一方面也是因为人们认识和思考检测问题的角度在不断发生改变,打破旧有滑动窗口的框架,将检测看成一个回归问题,不同任务之间的耦合。尽管目前 Faster R-CNN在速度上仍然无法和采用非深度学习方法的检测器相比,但是随着硬件计算能力的不断提升和新的CNN加速策略的接连出现,速度问题在不久的将来一定能够得到解决。
全卷积网络和 DenseBox
卷积层是CNN区别于其它类型神经网络的本质特点,不过CNN通常也不仅仅只包含卷积层,其也会包含全连接层,全连接层的坏处就在于其会破坏图像的空间结构,因此人们便开始用卷积层来“替代”全连接层,通常采用1 × 1的卷积核,这种不包含全连接层的CNN称为全卷积网络(FCN)。FCN最初是用于图像分割任务,之后开始在计算机视觉领域的各种问题上得到应用,事实上,Faster R-CNN中用来生成候选窗口的CNN就是一个FCN。
FCN 的特点就在于输入和输出都是二维的图像,并且输出和输入具有相对应的空间结构,在这种情况下,我们可以将 FCN 的输出看成是一张热度图,用热度来指示待检测目标的位置和覆盖的区域:在目标所处的区域内显示较高的热度,而在背景区域显示较低的热度,这也可以看成是对图像上的每一个像素点都进行了分类:这个点是否位于待检测的目标上。DenseBox是一个典型的基于全卷积网络的目标检测器,其通过 FCN得到待检测目标的热度图,然后根据热度图来获得目标的位置和大小,这给目标检测又提供了一种新的问题解决思路。
十一、基于CNN的人脸检测器
上面提到的都是通用的目标检测器,这些检测器可以直接通过人脸图像来学习从而得到人脸检测器,虽然它们没有考虑人脸本身的特殊性,但是也能够获得非常好的精度,这反映出不同类型目标的检测其实是相通的,存在一套通用的机制来处理目标检测问题。也有一部分工作是专门针对人脸检测任务的,有的考虑了人脸自身的特点,有的其实也是比较通用的目标检测方法,可以自然地迁移到各种类型目标的检测任务中去。
FacenessNet是专门针对人脸设计的一个检测器,其考虑了头发、眼睛、鼻子、嘴巴和胡子这五个脸部特征,简单地说,对于一个候选窗口,FacenessNet 先分析这五个部分是否存在,然后再进一步判断是不是一张人脸。
这种方法一方面同时利用了整体和局部的信息,能够从不同的角度对图像内容进行刻画,使得人脸和非人脸能够更好地被区分;另一方面增强了对遮挡的鲁棒性,人脸的局部遮挡会影响整体表现出的特征,但是并不会对所有的局部区域造成影响,因而增强了检测器对遮挡的容忍度。
随着越来越多的检测器开始采用深度网络,人脸检测的精度也开始大幅地提升。在2014年,学术界在FDDB上取得的最好检测精度是在100个误检时达到84%的检测率,达到这一精度的是JointCascade 人脸检测器。到2015年,这一纪录被FacenessNet 打破,在100个误检时,检测率接近88%,提升了几乎4个百分点。不仅如此,工业界的最好记录已经达到了100个误检时92.5%的检测率,检测率达到 90%以上的公司还不止一家,并且这些结果都是通过基于深度网络的人脸检测器所获得的。
在大幅提升人脸检测精度的同时,深度学习实际上还降低了包括人脸检测技术在内的各种目标检测技术的门槛,几乎到了只要采用深度网络就能获得不错的检测精度的地步;在精度方面,相比于基于非深度学习方法的检测器,基于深度学习方法的检测器在起点上就要高出一截。不过在检测速度方面,基于深度学习方法的检测器还难以达到实际应用的需求,即使是在GPU上,也还不能以实时的速度(25fps)运行;而反过来看,一旦速度问题能够得到解决,那么深度学习也一定会在目标检测任务上有更广泛和更大规模的应用。
传统的人脸检测技术优势在于速度,而在精度上则相比基于深度网络的方法要略输一筹,在这种情况下,一个自然的想法就是:能否将传统的人脸检测技术和深度网络(如CNN)相结合,在保证检测速度的情况下进一步提升精度?
Cascade CNN可以认为是传统技术和深度网络相结合的一个代表,和VJ人脸检测器一样,其包含了多个分类器,这些分类器采用级联结构进行组织,然而不同的地方在于,Cascade CNN采用CNN作为每一级的分类器,而不是用AdaBoost方法通过多个弱分类器组合成的强分类器,并且也不再有单独的特征提取过程,特征提取和分类都由CNN来统一完成。在检测过程中,Cascade CNN采用的还是传统的滑动窗口范式,为了避免过高的计算开销,第一级的CNN仅包含一个卷积层和一个全连接层,并且输入图像的尺寸控制在1212,同时滑动窗口的步长设置为4个像素,在这种情况下,一方面每张图像上候选窗口的数量变少了,窗口数量随着滑动步长的增大是按照平方规律下降的,另一方面每个窗口提取特征和分类的计算开销也受到了严格控制。经过第一级CNN之后,由于通过的窗口中人脸和非人脸窗口之间更加难以区分,因此第二级CNN将输入图像的尺寸增大到了2424,以利用更多的信息,并且提高了网络复杂度——虽然仍然只包含一个卷积层和一个全连接层,但是卷积层有更多的卷积核,全连接层有更多的节点。第三级CNN也采用了类似的思路,增大输入图像大小的同时提高网络的复杂度——采用了两个卷积层和一个全连接层。通过引入CNN,传统的级联结构也焕发出了新的光彩,在FDDB上,Cascade CNN在产生100个误检的时候达到了85%的检测率,而在速度上,对于大小为640480的图像,在限定可检测的最小人脸大小为8080的条件下,Cascade CNN在CPU上能够保持接近10fps的处理速度。Cascade CNN中还采用了一些其它的技术来保证检测的精度和速度,如多尺度融合、边框校准、非极大值抑制等,限于篇幅,这里不再继续展开。
十二、当前人脸检测的困境
经过几十年的研究和发展,人脸检测方法正日趋成熟,在现实场景中也已经得到了比较广泛的应用,但是人脸检测问题还并没有被完全解决,复杂多样的姿态变化,千奇百怪的遮挡情况,捉摸不定的光照条件,不同的分辨率,迥异的清晰度,微妙的肤色差,各种内外因素的共同作用让人脸的变化模式变得极其丰富,而目前还没有检测器可以同时对所有的变化模式都足够鲁棒。
目前的人脸检测器在FDDB上已经能够取得不错的性能,不少检测器在100个误检时的检测率达到了80%以上,这意味着它们检测出40个以上的人脸才会出现一个误检。然而,要更为客观地看待FDDB上的评测结果,我们还需要考虑另外一点:FDDB测试图像上的人脸和实际应用场景的差异性,换言之,我们需要思考这样一个问题:人脸检测器在FDDB上所达到的精度能否真实反映其在实际应用场景中的表现?
In FDDB human face is contained in the test image from the face to the posture change from light to various aspects of the occlusion, and thus is a relatively common data sets, but in practical applications, different scenarios Human Face often showing relatively clear features, such as scenes in a video monitor, camera setting position due to the higher resolution is limited and, at the same time and stored in the transmission process introduces noise, so the image on the face tend to have larger pitch angle and sharpness than low, in this case, the original excellent performance of the detector on FDDB it may not be able to achieve a satisfactory accuracy. In FDDB, there are about 10% the size of a human face in the 40 * 40 or less, and for some tasks such as face recognition, it is not suitable for small face, so if one detector performance because small face which led to its poor performance was flat on FDDB, but there is not much difference in better performance and a large number of people face detector, then its application in face recognition tasks are no problem, even because the model is simple and may bring the advantage of speed. In summary, when faced with a specific application scenario, on the one hand, we need to analyze specific issues, not blindly detector according to conclusions on the accuracy of face detection FDDB or other data set; on the other hand, we need to be based current face detector is adapted to process the data actually needed, so that the detector can achieve better accuracy in a particular scene.
Although detectors based on the current depth of the network to achieve high detection accuracy, and its versatility is very strong, but they pay a very high computational cost, thus the key break detector such that simplify and accelerate the depth of the network. In addition, if only consider the human face detection, this classification problem to be relatively simple, there is also a possibility: direct a small network will be able to learn well enough to complete this task. For the use of non-detector deep learning method, based on the detection accuracy will be low compared to many, but there will be a distinct advantage on speed, so the key is reasonable for the improvement and adaptation problems in specific application scenarios, to obtain a better detection accuracy.
