14.1 Hidden Markov Model
Hidden Markov Model (HMM) and the Viterbi algorithm
Hidden Markov Model observed by a given sequence, the sequence predicted hidden, the hidden information commonly used in the need to tap the surface of an information sequence from a task, such as voice recognition, handwriting recognition. In principle, HMM also for tasks such as speech tagging, Chinese word, etc., but because of the aspect confusion matrix, while the number of species is determined by observing sequence, when applied to a large corpus of words set the size of the hundreds of million , matrix storage required parameters billion in the confusion, in terms of both number of runs or computer memory footprint is disastrous; the same time, a large hidden Markov models assume that the current time step and implicit state only implicit current status display state at the previous time instant and relevant, but the reality is, the meaning of the words and the dimensioning as well as by a plurality of words in context, and therefore, hidden Markov model is rapidly eliminated in the NLP such tasks , with the opportunity to transfer to the airport to get rid of the condition of the time-dependent relationship model assumptions.
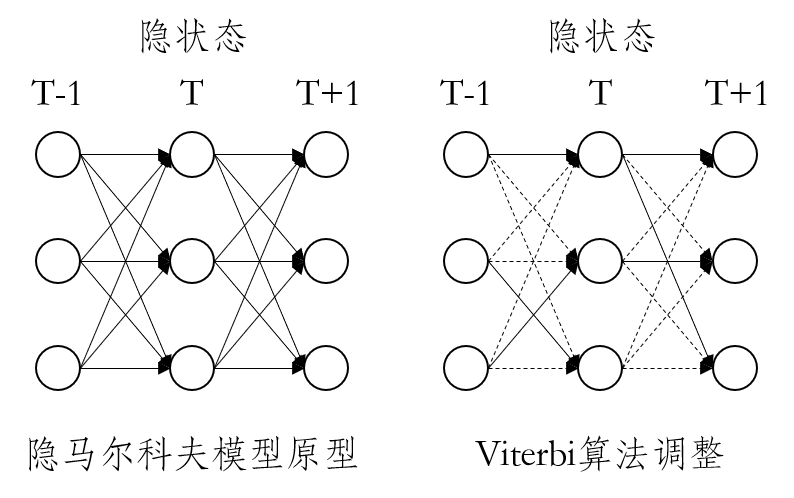
Viterbi algorithm is used to seek the maximum probability path in the field of dynamic programming. Prediction of a certain type of hidden state Hidden Markov Model for the current time step is actually based on a hidden state after a transition time, and summing results of all possibilities; the idea of the Viterbi algorithm for adjustment, after a time the hidden state transition, which takes only a maximum probability path. As shown below:
import numpy as np
class HMM(object):
'''
算法原理:
- 训练
依据统计学条件分布原理生成隐状态边缘分布、转移矩阵以及混淆矩阵
- 预测
i.将全局隐状态概率分布与混淆矩阵中显状态对应的列相乘预测初始时刻隐状态分布
ii.进入下一个时间步长,将上一时刻的隐状态分布与转移矩阵相乘
iii.将相乘的结果与混淆矩阵中该时刻显状态对应的列相乘预测该时刻隐状态分布
iii.循环第ii、iii步.
- 预测(Viterbi)
i.将全局隐状态概率分布与混淆矩阵中显状态对应的列相乘预测初始时刻隐状态分布
ii.进入下一个时间步长,将上一时刻的隐状态分布与转移矩阵中的元素相乘,取最大值
iii.将最大概率序列与混淆矩阵中该时刻显状态对应的列相乘预测该时刻隐状态分布
iii.循环第ii、iii步.
'''
def __init__(self):
self.train = None #训练集显状态序列
self.label = None #训练集隐状态序列
self.prob = None #全局隐状态边缘分布
self.trans = None #转移矩阵(row:T时刻隐状态 col:T+1时刻隐状态)
self.emit = None #发射(混淆)矩阵(row:隐状态 col:显状态)
def fit(self,train,label):
'''导入训练集,生成全局隐状态边缘分布、转移矩阵以及混淆矩阵'''
assert isinstance(train,list)
assert isinstance(label,list)
assert len(train) == len(label)
self.train = train
self.label = label
self.cal_prob()
self.cal_trans()
self.cal_emit()
def cal_prob(self):
'''生成全局隐状态边缘分布'''
prob = np.zeros(max(self.label)+1)
for y in set(self.label):
prob[y] += float(self.label.count(y)/len(self.label))
self.prob = np.mat(prob)
def cal_trans(self):
'''生成转移矩阵'''
trans = np.zeros((len(set(self.label)),len(set(self.label))))
last = self.label[0]
for y in self.label[1:]:
trans[last,y] += 1
last = y
self.trans = np.mat([row/row.sum() for row in trans])
def cal_emit(self):
'''生成发射(混淆)矩阵'''
emit = np.zeros((len(set(self.label)),len(set(self.train))))
for x,y in zip(self.train,self.label):
emit[y,x] += 1
self.emit = np.mat([row/row.sum() for row in emit])
def predict(self,test):
'''依据显状态预测隐状态序列'''
assert isinstance(test,list)
assert len(set(test)-set(np.arange(self.emit.shape[1]))) == 0
seq = []
for t in range(len(test)):
if t == 0:
pred = np.multiply(self.prob,self.emit[:,test[t]].T) #预测初始时刻隐状态
else:
pred = np.multiply(pred*self.trans,self.emit[:,test[t]].T) #预测T时刻隐状态
pred = pred/(pred.sum()+1e-12) #防止计算下限溢出
seq.append(pred.argmax())
return seq
def viterbi_predict(self,test):
'''Viterbi算法调整'''
assert isinstance(test,list)
assert len(set(test)-set(np.arange(self.emit.shape[1]))) == 0
seq = []
for t in range(len(test)):
if t == 0:
pred = np.multiply(self.prob,self.emit[:,test[t]].T) #预测初始时刻隐状态
else:
pred = np.mat([(pred[0,y]*self.trans[:,y]).max() for y in range(pred.shape[1])]) #在原模型上添加此行
pred = np.multiply(pred,self.emit[:,test[t]].T) #预测T时刻隐状态
pred = pred/(pred.sum()+1e-12) #防止计算下限溢出
t+=1
seq.append(pred.argmax())
return seq
if __name__ == '__main__':
train = [0,5,2,6,4,3,2,0,5,1,5,1,2,5,2,0,2,0,2,3,6,4,6,4,2,5,1,0,2,5]
label = [1,0,2,1,2,1,2,2,0,2,0,1,0,0,2,1,1,2,2,0,1,2,0,2,1,2,0,0,0,1]
test = [0,2,3,6,3,1,1,2,2,5,1,5,4,2,3,6,2,5,0,5,2]
model = HMM()
model.fit(train,label) #模型训练
print('Prediction result (original): %s'%model.predict(test)) #模型预测
print('Prediction result (Viterbi): %s'%model.viterbi_predict(test)) #模型预测(Viterbi)

14.2 MRF
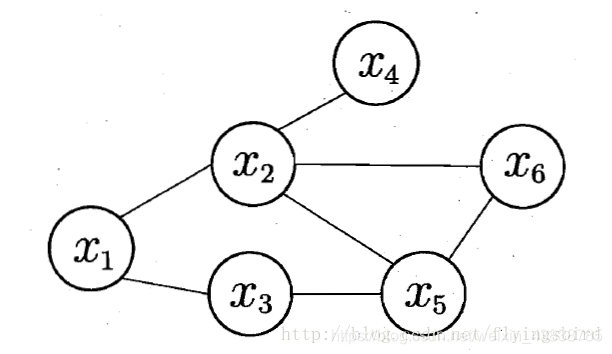
MRF (Markov Random Field, referred to as MRF) is a typical Markov network, which is a famous model no phase diagram. FIG edges between each node represents one or a set of variable nodes represent dependencies between the two variables. Markov random field with a set of potential function (potential functions), also known as "factors" (factor), which is defined on a subset of variables nonnegative real function, is mainly used to define a probability distribution function.
A simple MRF
14.3 CRFs
conditional probability conditional random i.e. CRF (Conditional Random Fields), is given another set of output variables for a random set of input conditions distribution model of random variables, which is a discriminant probability undirected graph model, since it is the discriminant, and that is to model the conditional probability distribution.
More CRF used in natural language processing and image processing, in the NLP, which is denoted by a probabilistic model and division of the sequence data, in accordance with the definition of CRF, the relative sequence is given observation sequence X and sequence output Y, then definition of conditional probability P (Y | X) described model.
CRF output of the random variable assumed to be an undirected graph model or a Markov random, random input variables as the condition is not assumed to be a Markov random field theory model structure diagram of CRF can be arbitrarily given, but our common special conditions are defined on the random linear chain, known as conditional random linear chain.

Learning and inference 14.4

14.5 infer approximately

14.6 topic model
1, LDA mathematical definition
1) topic model: the traditional text classifier, such as Bayes, kNN and SVM, can only be assigned to a certain category. Suppose I give three classification "algorithm", "word", "Literature" allowed to determine, if a classifier algorithm included in the text of the class, I feel okay, if divided into word, then I think this classification is not enough accurate.
Suppose a small young literary point of view my blog, he fully understand the algorithm and segmentation, naturally not give specific alternative category, is there a model that can tell this idiot, this article is likely (80%) are in talk algorithm, it may (19%) was telling word, almost impossible (1%) is talking about other topics it?
Yes, such a model is the topic model.
