[Advance notice]
article by author: Zhang Yaofeng in conjunction with their own experience in the production of finishing, forming easy to understand article
writing is not easy, reproduced please specify, thank you!
Code Cases Address: ? HTTPS: //github.com/Mydreamandreality/ sparkResearch
Read the article series: Kafka basic concepts
- We usually learn a new skill, such as a stage will experience:
这是个什么玩意啊,它能做什么啊,怎么做啊,为什么它就能做啊,哦这样啊.好厉害啊~- I put in this order kafka and spark, es tell you understand slightly
What is kafka?
- Kafka accurate to say that
分布式消息系统 - To understand what
分布式消息系统we must first understand what it's scenario
kafka application scenarios
-
It can be said that we live in an era of data explosion, a large number of data growth in all walks of life, to our business has brought a lot of pressure, but at the same time, the huge data also gives us great stealth wealth
-
So this time we face a huge challenge
- How to huge business data access to our big data analytics platform,
- The second is how to analyze the information collected
-
Hey, this time it came into being kafka
-
kafka is designed as a distributed system of high-throughput
-
Its main features are as follows :
- Decoupling applications, asynchronous message, flow clipping, high-performance, high-availability, fault-tolerant high, built-like partition
-
Current mainstream distributed message queue, there are many, such as:
- ActiveMQ
- RabbitMQ
- ZeroMQ
- and many more
- [Currently the best overall performance in terms of all aspects of the theory is RabbitMQ]
-
As different distributed message queues are respective different application scenarios, detailed comparison between them to view other bloggers articles
- I can give a production scenario of kafka
- Log processing [FIG follows logic]
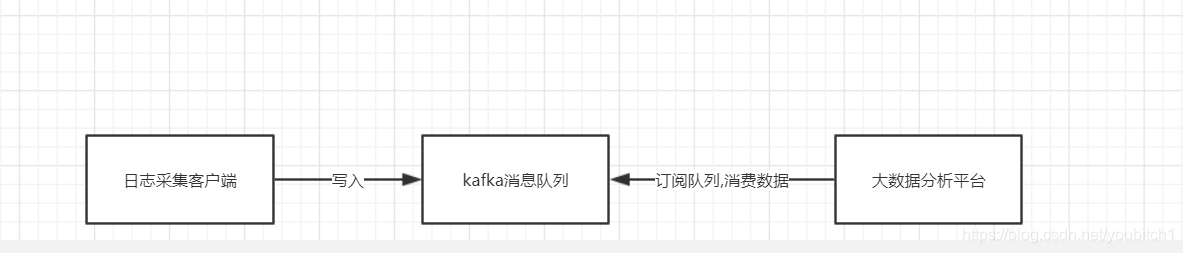
- First, we have a client log collection, is responsible for collecting our server logs, the timing of the write queue every day kafka
- kafka is responsible for log data receiving, storage, forwarding
- Our big data analytics platform responsible for subscription and consumption log data kafka queue
Distributed Messaging System
After we know kafka application scenarios, it is a good understanding of the distributed messaging system
- Distributed messaging system is to transfer data from one application to another application, so that our program can focus on the data, without additional concern is how data sharing
- Our message [
也就是数据] between the application and the messaging system is an asynchronous queue
Message mode
- In kafka, we have two types of consumption patterns
- A: Point to Point mode
- Two: Release: Subscribe [
PUB-SUB] mode
Point to Point mode
-
Save the message producer to a message queue and a queue message from the message consumer,
-
But here should be noted that:
- After the message is consumed, the queue is no longer stored in this message Consumed
-
Peer support multiple consumers, but a
消息concerned, there will only be a consumer can consume -
Here is a simple example: For example, in Taobao orders in the system :
- Business is news producer: it tells how much a stock message queue
- We are news consumers, we went to buy merchandise business
- This time a merchant orders will correspond to each of us consumers
- We can consume this news, but after I consume you can not repeat a consumer
Point as shown below:

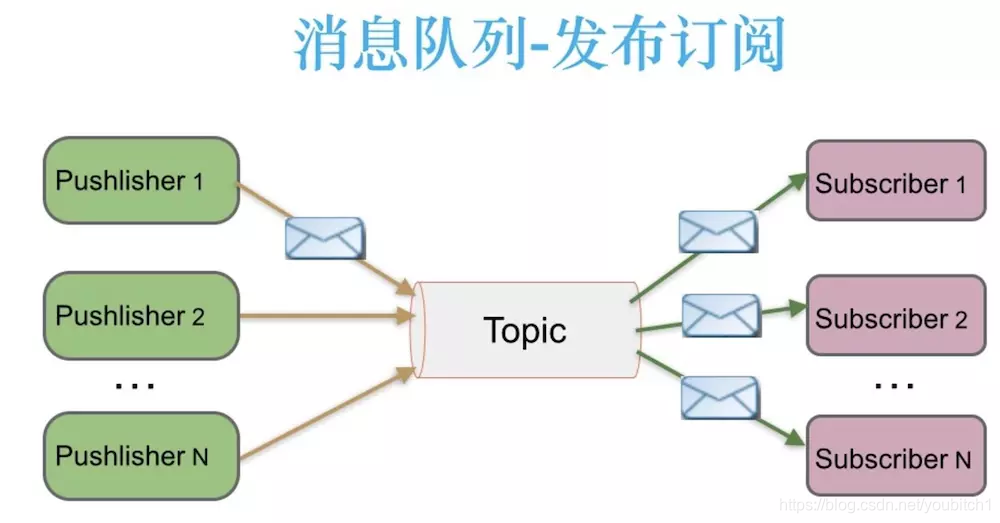
Publish - subscribe [pub-sub]
- News publishers to publish messages to a topic [topic] while there may be multiple, subscribe to the topic of consumer spending, and a different point is that subscribe to a news release can have more consumer spending together
Publish - subscribe shown below
kafka advantage
- Here are a few kafka advantage [of course, more than that]
- Reliability: Kafka is distributed, partitioning, replication and fault tolerance
- High Availability: Kafka uses a distributed commit log, which means that the message will be retained on disk as quickly as possible, so it is durable
- Performance: Kafka for publish and subscribe messaging has high throughput, even if we are TB-level data, it also maintained a stable performance, Kafka is very fast, and ensure zero downtime and zero data loss
And the subsequent update kafka applications and large spark in java data frame integration code cases
