answer
Version 1: Block + hash
· Learning to learn the code source to learn Gangster
Blocking section:
the former into a 5 (referred to as a head AH), and 4 bits (referred to as the tail at), b the same division,
, (A first minus 1)
hash part:
in case
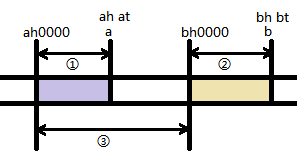
- The first violence tail is 0 ~ at inserted into a hash table, then ah as the head to match the hash table, query ah0000 ~ a (ahat) answers
- Violence and then the tail is at + 1 ~ bt inserted into a hash table (hash table now is in the range of 0 ~ bt), followed by bh as a header to match the hash table, the query bh0000 ~ b (bhbt) of answer
- Finally, the remaining part bt + 1 ~ 9999 inserted (now the table is in the range of 0 to 9999), enumeration ah ~ (bh-1) for all possible answers as the head, to give ah0000 ~ (bh-1) 9999
Tidy is the second step of the statistical results ans = + The third step - the first step
in case equals where did all the same
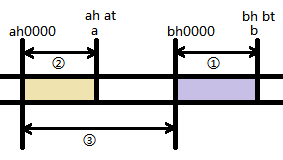
- The first violence tail is 0 ~ bt inserted into a hash table, then bh as a head to match the hash table, query bh0000 ~ b (bhbt) answers
- The tail is then violence bt + 1 ~ at is inserted in the hash table (hash table now is in the range of 0 ~ at), then ah as a header to match the hash table, the answer to the query ah0000 ~ a
- Finally, the remaining part at + 1 ~ 9999 inserted (now the table is in the range of 0 to 9999), enumeration ah ~ (bh-1) for all possible answers as the head, to give ah0000 ~ (bh-1)
Version 2: Digital dp Sorry, the first, and so, I did not understand thoroughly

#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N=1e6+10;
const int M=(1<<20)-1;
/*
这里帖一下上面链接的博客主的原话: 这真的是以现在的我的能力注意不到的地方呢
还有一些比较巧妙的地方就是:
1.用二进制来优化hash链表,用每一个数二进制下的后面20位来当第一维的下标,用每一个数的值来当第二位的下标,优化空间,也使得数组开的下
2.对于hash的操作,预先开设一块固定内存,避免在堆上申请内存和释放,加快速度
3.对于visit的数组的重用,每T组数据,某个值存在就将他标为visit[x]=T
4.就是莫队分块,分成头尾两部分--因为f(x)的可加性
*/
struct node{
ll key,cnt;
node* nxt;
}* g[M+1];//g[i]是二进制最后20位为i的链表的头指针
node* cur;
node memory[N];//预先定义一块内存空间 hash的操作都在此执行
ll visit[M+1];//第T组数据下 二进制最后20位为i的链表内有没有元素
ll T=0,k,s;
ll dt[10][20];//各种数字的各种次幂
void ins(ll x){
node* p;
if(x>s)return ;//超过计算界限 退出
ll u=x%M;//x二进制最后20位
if(visit[u]<T){//在第T组数据下 二进制最后20位为u的链表内没有元素就加入
//类似初始化了
visit[u]=T;
g[u]=NULL;
}
for (p = g[u]; p ; p=p->nxt) {
//在二进制最后20位为u的链表中找值为x的节点
if(p->key==x){
p->cnt++;
return ;
}
}
//如果链表为空或者找不到对应的 新建
p=cur++;
p->key=x;//在二进制最后20位为u的链表头部新建一个key为x的节点
p->cnt=1;
p->nxt=g[u];//链表头插法
g[u]=p;
}
ll ask(ll x){
node* p;
if(x>s)return 0;
x=s-x;//去掉头的部分 对剩下的部分进行匹配
ll u=x%M;
if(visit[u]<T)return 0;
for (p = g[u]; p ; p=p->nxt) {
if(p->key==x)return p->cnt;
}
return 0;
}
void init(){
//预处理各种数的各种次
for (int i = 0; i <= 9; ++i) {
dt[i][0]=1;
for (int j = 1; j <= 15; ++j) {
dt[i][j]=dt[i][j-1]*i;
}
}
}
void init_hash(){
T++;
cur=memory;//cur重新指向该内存的起始
}
ll cal(int x){//计算f(x,k)的值
ll res=0;
while(x){
res+=dt[x%10][k];
x/=10;
}
return res;
}
int main(){
ios::sync_with_stdio(0);
ll a,b;
int sqrt=10000;
ll ah,bh,at,bt;
ll reta,retb;
init();
while(cin>>a>>b>>k>>s){
init_hash();
reta=retb=0;
ah=(a-1)/sqrt;bh=b/sqrt;
at=(a-1)%sqrt;bt=b%sqrt;//预先处理处a和b的头部与尾部
if(at<bt){
for (int i = 0; i <= at; ++i)
ins(cal(i));//将尾部是0~at的值插入表中
reta=ask(cal(ah));//得到头部是ah 尾部是0~at的答案 即 ah*10000<= 数 <=a-1 中的答案
for (int i = at + 1; i <= bt; ++i)
ins(cal(i));//再将尾部是at+1~bt的值插入表中
retb=ask(cal(bh));//得到 头部是bh 尾部是0~bt的答案 即 bh*10000<= 数 <=b
for (int i = bt+1 ; i <sqrt ; ++i) //将剩余的sqrt插入表中
ins(cal(i));
}else{
for (int i = 0; i <= bt; ++i)
ins(cal(i));//将尾部是0~bt的值插入表中
retb=ask(cal(bh));//得到头部是bh 尾部是0~bt的答案 即 bh*10000<= 数 <= b (bh*bt) 中的答案
for (int i = bt + 1; i <=at; ++i)
ins(cal(i));//再将尾部是bt+1~at的值插入表中
reta=ask(cal(ah));//得到 头部是ah 尾部是0~at的答案 即 ah*10000<= 数 <=a (ah*at)
for (int i = at + 1; i <sqrt; ++i)
ins(cal(i));
}
for (int i = ah; i < bh; ++i)
retb+=ask(cal(i));
//根据头部去匹配现在表中的值 求得 头部是ah<= <bh 尾部是0~sqrt-1 即 a-1<= 数 <b*10000 的答案
cout <<retb-reta << endl;
}
return 0;
}
Accomplished enough, not read, preemptive pit, let me come back to learn child-bit solution stops dp
Code learning sources
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
int n,m,k;
ll a,b,s;
ll pos[20];
ll f[20];//全排列
ll p[20][20];//各种数字的各种次方
//len 表示目前还有几位没有确定下来
//sum 表示要组合成的数
//top 目前在讨论的数字 先讨论9 再讨论8...直到0
ll dfs(int len,ll sum,int top){
if(len*p[top][k]<sum) return 0;//如果全部都是最高位加起来都没有总和大 直接返回0
if(sum<0)return 0;
if(top==0){
if(sum) return 0;
pos[0]=len;
ll res=f[n];
for (int i = 0; i <=9; ++i) {
res/=f[pos[i]];
//一个全排列就是符合要求的数的个数 因为首位是什么已经在solve()中的for里面决定好了
//所以后面首位是0页没关系 只要找到符合条件的数的个数 计算出他们可以组合出集中不同的个数就好了
}
return res;
}
ll res=0;
for (int i = 0; i <= len; ++i) {
pos[top]=i;//目前讨论的数字所在的位置
res+=dfs(len-i,sum-i*p[top][k],top-1);
}
return res;
}
//在dfs前先做一些处理 比如剪枝 以及记录dfs开始前有几位数还没有被确定下来
ll sub_solve(int len,ll sum){
if(len==0)return sum==0;
n=len;
return dfs(len,sum,9);
}
int len,bit[20];
ll solve(ll x){//求[1,x]内符合条件的数字的个数
len=0;
while(x){
bit[++len]=x%10;
x/=10;
}
ll res=0,sum=s;
for (int i = len; i ; --i) {
for (int j = 0; j <bit[i]; ++j) {
res+=sub_solve(i-1,sum-p[j][k]);
//目前讨论的数没有取到最大值(j没有等于bit[i]) 则后面的数可以随便取
}
sum-=p[bit[i]][k];//取到了最大值
}
res+=(sum==0);
return res;
}
int main(){
ios::sync_with_stdio(0);
//init
f[0]=1;//全排列
for (int i = 1; i <= 20; ++i) {
f[i]=i*f[i-1];
}
for (int i = 1; i < 10; ++i) {
p[i][0]=1;//i的各种次方
for (int j = 1; j < 16; ++j) {
p[i][j]=p[i][j-1]*i;
}
}
while(cin>>a>>b>>k>>s){
cout<<solve(b)-solve(a-1)<<endl;
}
return 0;
}
