Speaking spark many articles, the starting point is nothing more than three: Framework applications, source code and explain the principle, performance optimization
Personally feel that the above three perspectives entry point too heavy on detail, more suitable for industry engineers (applications development, development, maintenance); for new entrants to the role of learners and non-engineers relatively unfriendly, we try to introduce from a higher perspective spark, try to let everyone know what this thing is, how it has evolved over; now look into why its president, including those modules.
0. cluster resource management and task scheduling system in the background
(1) occurs background
- Improve the utilization of cluster resources.
In the era of big data, to store and process massive amounts of data, need large-scale server cluster or data center, generally speaking, the number of running confused many types of applications and services on these clusters, such as off-line work, work flow, iterative operation, crawler server, web server, etc., conventional practice, each type of job or service corresponding to a single cluster, in order to avoid mutual interference. In this way, the number of clusters is divided into many small clusters, some clusters running Hadoop, some running Storm, some run Spark, some running web server, however, due to different types of jobs / services required amount of resources, so the utilization of these small clusters usually very uneven, with some clustering at full capacity, resource constraints, while others are idle for a long time, resource utilization is very low, in order to improve the overall utilization of resources, one solution is to these small clustered into one large cluster, so that they share the resources of this large cluster resources by a unified system management and resource allocation, which was born Borg, YARN, Mesos, Torca, Corona. From the cluster shared perspective, such systems will actually abstract all the hardware resources of the company into a large-scale computer, available to all users.
- Automated Deployment Services
Once all the computing resources abstracted into a "big computer", the question arises: how the company's various services deployed? Similarly, Borg / YARN / Mesos / Torca / Corona system needs to have a class of service features automated deployment, therefore, from the point of view service deployment, this type of system is actually a unified service management system, such systems provide application service resources, automated deployment services, and other service fault-tolerant kinetic energy .
These are just a brief background and design motive of this type of system, such systems are parsed from the next two angles.
Angle a: programming data center
After all any internal hardware resources can also be considered a data center, Corona a class system for unified management of these resources by Borg / YARN / Mesos / Torca /, all user programs and services will enter the data through a unified entrance Center, by whom such systems to allocate resources and monitor programs and services running, and enable the necessary fault tolerance in case of failure, the progress report on the implementation of the program and so on, but as for the application or service running on a particular machine which, What the machine where ip, port number that the user does not need management, all by a unified management system management (user may be able to query).
Specifically, after the use of such systems, when a user executes an application or service deployment, simply describes the application or resources (such as CPU, memory, disk, operating system type, etc.) through the service needs a configuration file to be executed command, dependent on external files and other information, and then submitted to the Borg / YARN / Mesos / Torca / Corona on by a client, then the rest of the work entirely to the system.
Angle II: Ecosystem
From another perspective, Borg / YARN / Mesos / Torca / Corona a class system can build an internal ecosystem for the company, all applications and services can be "peaceful and friendly" run on the ecosystem. With such systems after, you do not have to worry which version of Hadoop, Hadoop 0.20.2 is still Hadoop 1.0, you do not have to choose what kind of computing model and distress, and therefore various software versions, various computational model can be run together in a "supercomputer" on.
From the open-source perspective, YARN proposed, to some extent, weakened the pros and cons of multi-computing framework contention. YARN is based on the Hadoop MapReduce evolved in the era of MapReduce, a lot of people criticize MapReduce is not suitable for iterative calculation and loss calculation, so there Spark and Storm and other computing framework, and these systems developers are on their own website or thesis after the MapReduce contrast, boasted of how advanced and efficient system, but there have been YARN, then the situation becomes clear: MapReduce YARN only run on a class of application abstraction, nature is on Spark and Storm, they just for different types of application development, no better or worse in others, their own strengths, the merger coexistence, but also the future development of all computing framework, no accident, then, should be above the YARN. Thus, in order to YARN a platform for the underlying resource management, ecological systems on a variety of computing framework to run it was born.
(2) The challenge
- Load more and more types of data centers, there are batch jobs, real-time query tasks, streaming services;
- Resource needs of increasingly diverse, heterogeneous workload, resource constraints and preferences increasingly complex, for example: a task that must be considered CPU, memory, network, disk or even memory bandwidth, network bandwidth, etc., also need to consider local data lines, preferences and other physical machine;
- Different types of tasks inevitably actual scheduling process scheduling to the nodes on the same data, which need to be isolated to different kinds of tasks to reduce interference therebetween;
- Dynamic resource adjustment scheduling process;
- Preemptive task scheduling mechanism the heavy mode;
- Recovery;
- Cluster unknown long-tailed cause of the problem;
- Cluster resource utilization is low, the average global cloud physical server resource utilization less than 20%, and the actual utilization is usually less than half of the total amount of physical resource in the application resource premise almost all logical resource allocation;
(3) the abstract model
is actually a cluster resource management and task scheduling system is a complex multi-dimensional mixed knapsack problem, knapsack problem dynamic programming problem should be the most classic problem. We can each data node in the cluster compared to a backpack, backpack different dimensions of different capacities are different, resources will need to place the task likened items required for the job is its cost, and the task of running generated rental is the cost-effective. We need to do is to meet the mission requirements under the premise of placing it in a suitable backpack, to ensure maximum utilization of the cluster. But the actual process and the scheduling algorithm, there are many different places, such as:
- Knapsack problem is just a process of deduction, we can use some of the data structure to hold some intermediate results to derive optimal method of distribution. But the actual scheduling a task we have to be immediately assigned based on existing resources, rather than a temporary storage allocation scheme, there are many other tasks are then submitted in accordance with the best job placement after completing the program;
- Different tasks have a certain priority in actual operation, it is necessary to ensure that high-priority tasks first to be guaranteed, which increases the difficulty of scheduling;
- Task resource requirements during operation is not static, sometimes over time resource demands increase, which is resilient scheduling problem to be solved.
- Also produce interference between tasks, resources and sensitivity to different tasks interference on different resources dimensions are different;
- Resource management and scheduling system equivalent to the system of the brain, which is to address the full range of tasks and requests the data node, so its core scheduling logic must not be too complicated, scheduling if after considering all the circumstances, is bound to extend the schedule time, this is the task execution can not be tolerated;
so for a resource management and task scheduling system, the functions of which would indicate that not be a perfect system, nor is a versatile system for different needs business scene reconstruction, and therefore in industry and academia sparked extensive research and exploration.
(4) System Evolution
- On the whole it is divided into: single scheduling system, two scheduling system, the shared state scheduling system, distributed scheduling system, a hybrid scheduling system.
- Google proposed MR model
- Appear batch framework of Hadoop
- The emergence of in-memory computing framework Spark
- Resource management framework Mesos, YARN, borg appear
- Based on the state share of the Omega
- Fully distributed scheduler Sparrow
- Central and distributed hybrid architecture combining Mercury
- Support Fuxi fast failure recovery
- In support of Ali offline hybrid scheduling system mixed cloth
- Emergence of container-based cluster management framework kubernetes
(5) Some allocation strategy evolution
- FIFO mode, first-come first assignment after assignment later; in this way will not guarantee optimal scheduling but also widely used because of its simplicity in the current resource scheduling system;
- Fair scheduling to allocate resources to a plurality of different resource pools, each pool of a certain proportion of resources allocated resources, task according to the maximum and minimum resource pool strategy (for example, three tasks are required resource is 2, 4, 4 units, and now a total of nine units of resources, first of all each task averaging three units of resources, because the first task of a multi-unit resource, and then assign it to an average of more than one unit out of resources to tasks two and three, so the final task a get two units of resource, task two get 3.5 units resources, task three get 3.5 units of resources) or weighted maximum and minimum policy (different tasks with different priorities, so when the average distribution also need to consider weight) resource allocation.
- DRF main priority scheduling resources. For a task which is the main resource is the resource request each dimension largest proportion of resources, such a task requires <2CPU, 4G>, now <4CPU, 10G>, a ratio of 1 / 2,4 / 10, then CPU is the main resource for the task. Select the smallest task main priority in the allocation of resources be accounted for in the allocation of time, the current way is widely used in various dispatching system. Interested parties can search for relevant papers to view its detailed argumentation.
- The shortest job first scheduling. Studies have shown that the shortest job first scheduling ways to improve the system resource utilization, in fact, easier to understand, short resources job requires less so when the allocation can be met as soon as possible, in addition to less job execution time is short, so as soon as possible the release of resources, which is good for improving cluster throughput and utilization. But there are also disadvantages in this way is a long job will not be the case for a long time and resource starvation occurs; another pre-execution time of the task is unpredictable;
- Capacity scheduler is the default application in YARN. The principle is to build different levels for different user groups task queue. During dispensing, preference min {use / queue allocated} partitioned, selected according to the FIFO queue within the strategy. Therefore, the selection process can be summarized by the following steps: (1) than to select a task queue based on the minimum satisfied; (2) select a particular task in the task queue; (3) selecting a resource application request from the task, because a task may correspond to a plurality of resource application request; after obtaining the request matches the current surplus resources and scheduling;
- Tetris algorithm. Considering the task of application resources are increasingly diverse needs, resources need to consider the different dimensions of the weight issue, the core idea is to apply the resources represented as a multi-dimensional vector, a naturalization process and the dot product of the remaining cluster resources, priority response weight greatest resource request. This method can be improved from the viewpoint of the algorithm demonstrated a certain degree of accuracy and efficiency of the scheduling, but it requires more complex operation in the resource allocation process, using not many. And the current mainstream resource scheduling system in the application of resources only considered the CPU and memory resources of two dimensions.
- Delayed scheduling policy. If the resource is not currently allocated to meet other needs, such as local data lines, the wheel distribution may be temporarily abandoned, wait for the next assignment, is performed by setting a threshold number of abandoned.
1. resource management and task scheduling cluster system architecture
Cluster resource management and task scheduling design two aspects: (1) cluster management, load in the main cluster resource management and scheduling, a task given the demand, it can give superior scheduling scheme in the present case; (2) task scheduling, task to a lot of tasks which we should choose to be allocated; these two aspects are mutually reinforcing relationship, any aspect of optimization will bring to enhance the overall performance of the cluster. Because task scheduling strategy mainly involves scheduling section, there is an above some discussion, and task scheduling itself with some of the randomness, so relatively little studied, the following brief summary of the main system for resource management.
Overall the current scheduling system can be divided: single scheduling system, two scheduling system, the shared state scheduling system, distributed system, and hybrid scheduling scheduling system. The presence of each aspect of the system has a scheduled background, the following main principles from the background, achieved, disadvantages of typical system set forth. It should be noted that, although there are so many scheduling system, but now most of them are single layer or two of the industry scheduling system used, because they mature architectural design, has gone through years of practice online, you can smooth operation; the other is the scheduling system and have a good ecological community, compatible with existing ecological, cost studies. Therefore, some small companies are mostly related to the system or the use of Hadoop, only specifically for the cloud computing market companies, such as Ali cloud, Tencent cloud, cloud, etc. Huawei will develop its own specialized scheduling system.
1.1 monolayer dispatch system
- Background: The scheduling system is a prototype of large-scale data analysis and the emergence of cloud computing, which produces mainly for large-scale cluster management to improve data processing capabilities.
- Rationale: single-scheduling system combines resource management and task scheduling, a type of JobTracker center responsible for the rational allocation of cluster resources, unified statistical tasks, cluster computing node information maintenance task execution process state management .
- Advantages: (1) JobTracker capable of sensing the state of all resources and performs tasks clusters can be performed globally optimal resource allocation and scheduling, to avoid interference between tasks, task preemption appropriately, to ensure the efficiency and service quality calculation tasks; (2 ) architecture model is simple, only a global manager is responsible for all management.
- Disadvantages: (1) JobTracker as a center cluster, a single point of bottlenecks can not support large clusters; (2) internal implementation is very complex, because the need to implement a dispatcher all the functional modules; (3) an increase in the kind of load cause the system requires constant iteration, which will increase the complexity of the system is not conducive to the maintenance and expansion of late; (4) supports only single types of tasks, MR type of batch jobs;
- A typical scheduling system: Hadoop1 * version; kube-scheduler K8S in, Paragon, Quasar..
1.2 Double scheduler
- Background: In order to solve the scalability problem single-scheduling system, is responsible for system implementation requires constant iteration, can not support different types of tasks and other shortcomings
- The principle: the decoupling of resource management and task scheduling. Resource cluster resource manager is responsible for maintaining the resource information and resource allocation in the cluster to a specific task, the task manager is responsible for application resources and application to subdivide and specific task scheduling based on user logic, Node Manager is responsible for maintaining node All information, including: health, the remaining node resources of the mandate and so on. Resources to carry out resource management and task scheduling through coordination between the three.
- Advantages: (1) resource manager is only responsible for resource allocation, task scheduling is completed by the application, and improve the scalability of the modular design of the system; (2) complete logical task scheduling by the particular task, to provide support for different types of tasks ; (3) internal modular, conducive to the maintenance and expansion;
- Disadvantages: (1) the task can not be perceived global resources, can only be based on the request / offer to acquire resources, can not effectively avoid interference between heterogeneous load performance problems; (2) resource management and task scheduling is not conducive to decouple preemptive priority between multiple tasks; resource request (3) All tasks require resource manager for processing, in addition it also is necessary to maintain communication between the node manager and the resulting presence of a single point resource manager;
- Typical system:
- Mesos: The first resource management and task scheduling decoupling offer-based (based on resource availability) scheme, which has a central resource manager, by using the number of allocation strategy allocates resources to different computing frame, each frame is calculated taking the increment or All-or-Nothing according to its own logic, etc. preference resource decision to accept or reject the allocated resources, computational framework for resource allocation and the next task execution according to the resource allocation. Advantages: easy implementation logic, two scheduling; disadvantages: (1) not globally optimal scheduling result; (2) there is a single point of bottlenecks, because the central resource manager needs to calculate the frame-by asking whether resources; (3) does not support preemption, resource allocation can not seize upon recovery; (4) DRF policy idealistic; (5) the degree of concurrency is not high, because the information for the remaining resources of a slave, the frame needs to individually ask whether the resource is calculated based on the serial ,, polling mode;
- YARN: The basic idea of the Mesos same, but its use requese-based approach to application of resources, but there are three modules, RM responsible for resource management, AM is responsible for tasks resources application and run YARN in; advantages: (1) support different scheduling policies ensures that the task priority, multi-tenant capacity management, resource fair share, resilient and elastic (when a tenant would need to seize the resource sharing out resources) and so on; convenient (2) application extensions, according to AM as long as you can provide relevant API achieve the user's task execution logic; disadvantages: a single point of bottleneck; troubleshooting and fault tolerance is not perfect; not enough support for the isolation of friendship;
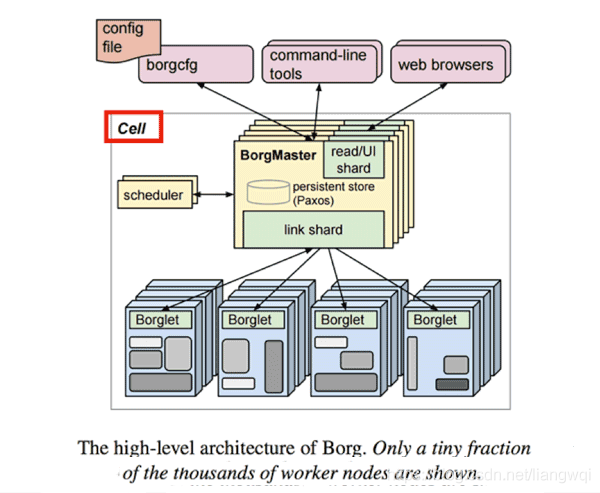
- borg: first integration resource isolation, resource overbooking, scoring machines, multi-task in one of the priority resource management systems. Layer 2 scheduling framework, Node Manager will report regularly Borglet implementation of the mandate and resources of its own node to BorgMaster, scheduler within each cluster applications make scheduling decisions based on information stored in itself, and then decide whether to allow its resources to apply Master . On this basis, it made some optimization, such as: user access control, scoring node, multi-task dispatch, multi-dimensional resource isolation and process isolation, pluggable scheduling policies, and support for thousands of different applications and services, support tens of thousands of cluster size. But now that these ideas can only be acquired through the papers for the closed-source system, specific implementation details are not clear.
- Fuxi. Ali cloud which is scheduling system for offline operation, instead of the opposite end is the amount of online services for scheduling system Sigma. Fuxi with YARN design very similar to the specific resource allocation is also similar. But Fuxi for the Recovery and usability optimized memory expansion, enables rapid fault recovery based on existing information, and provides multi-level blacklisting mechanism.
1.3 Shared state scheduler
- Background: There is a problem when the application is in resource application can not be informed to the global information resource clusters, which leads to not globally optimal scheduling, shared state scheduler is to solve this problem in front of the scheduler.
- Rationale: a semi-distributed architecture, provides a global cluster status by sharing resources for the application view, and using optimistic concurrency application and release resources to increase concurrency of the system.
- Advantages: (1) support for global optimal scheduling; improve concurrency (2) capable of a certain degree;
- Disadvantages: (1) will result in a highly concurrent resource requests frequent resource competition; (2) not conducive to the realization of priority preemptive tasks; (3) a copy of the global resources required to maintain a single point of bottleneck module;
- Typical system:
- Omega: Omega system there are multiple schedulers, each scheduler will save a copy of the information resources of the cluster, each scheduler may schedule tasks according to a copy of the information, the use of optimistic locking during application of resources and scheduling of concurrent manner . Currently its only experiment in a simulated environment, and has not been tested on a real line.
- Apollo: Considering the fair scheduling between Microsoft Scope production platform scalability, user groups, improve resource utilization, shorter working hours (local data lines, task properties, task prediction) solutions. The core comprises two aspects: (1) with real-time updates and system maintenance tasks waiting time for each matrix as a basis and reference scheduling, task scheduling to be considered child nodes on which is more appropriate calculation; (2) provided independent computing nodes the task queue, collecting on its implementation of the mandate, in turn superior scheduling decisions based on cost model. Its main design for massive short job.
- JetScope: Apollo on the basis of interactive data analysis tasks are special optimization, optimized for low latency scheduling interactive jobs by Gang scheduling policy.
- Nomad
Distributed Scheduler 1.4
- Background: providing system throughput and concurrency
- Rationale: there is no fully distributed scheduling system between the communication and cooperation, each of the distributed scheduler be the fastest decisions based on their own with minimal prior knowledge of each individual response task scheduler, subject to the overall implementation plan resource allocation statistical significance. Academic research is still in the stage, not really apply to the production environment.
- Advantages: improved throughput, and concurrency
- Disadvantages: (1) scheduler quality can not be guaranteed; (2) non-equitable distribution of resources; (3) can not support multi-tenant management; (4) can not avoid interference between the performance of different tasks;
- Typical System: Sparrow: is a completely decentralized, distributed scheduling system, typically used to meet short latency high throughput mission scenarios. The system comprises a plurality of schedulers, the distributed scheduler on the cluster nodes, the job can be submitted to any of a distributed scheduler. Its core is random scheduling model, using the random sampling of the second power of the sampling theorem for two service nodes each task, a task waits for selecting as a scheduling result of the shortest queue, asynchronously predetermined mode for resource scheduling may be employed. Experiments show that the approximate optimum solution can effectively meet the needs of mass ms scheduling performance.
1.5 hybrid scheduler
- Appear background: in some particular mixing task scheduling scenario, some tasks require faster response scheduling, and scheduling other tasks do not need to respond quickly, but the need to ensure the quality of scheduling.
- Rationale: Design two resource requests and task scheduling path, retain the advantages of two-tier schedule, taking into account the advantages of a distributed scheduler. No preference for resource requirements and a high response distributed task scheduler, for scheduling resources using high quality central resource manager allocates resources.
- Advantages: (1) can be scheduled in different ways for different types of tasks; (2) providing a flexible interface for the application layer security and performance;
- Disadvantages: complicated business logic calculation of the frame layer; internal scheduling systems also require coordinated processing for two different schedulers;
- Typical scheduling system:
- Mercury: Microsoft's hybrid scheduling mechanism, the central scheduler to schedule jobs requiring high quality equitable distribution of resources, a distributed scheduler for time-sensitive and high-throughput requirements of the job scheduling.
- Tracil Sparrow based on an increase in access control model, combined with QoS-aware load modeling and performance evaluation specify access control policy, you can quickly get to the task of ensuring the implementation of resources and improve system response time and improve concurrency cluster resource utilization.
1.6 Summary
Current mainstream open source scheduling system comparison (structure, resources-dimensional, multi scheduler, support for pluggable, preemptive priority, re-scheduling, resource overbooking, resource assessment, to avoid interference):
- Kubernetes: single-layer, multi-dimensional resource support, pluggable, resource overbooking
- Swarm: single-layer, multi-dimensional support resources
- YARN: single / two, CPU, and memory, multiple schedulers, pluggable
- Mesos: two-tier, multi-dimensional, multi-scheduler, pluggable, resource overbooking
- Nomad: shared state, multi-dimensional, pluggable
- Sparrow: fully distributed, fixed slots
- Borg: preemptive priority, re-scheduling, resource overbooking, resource assessment
- Omega: supports all features in addition to avoiding interference
- Apollo: multiple schedulers, pluggable, preemptive priority, rescheduling
- The selection of the scheduling architecture need different scheduling characteristics of the frame is determined according to the specific application scenario. Existing scheduling system problems include: loss of function, poor resource utilization, task characteristics unpredictable performance interference very inefficient, weak scheduler performance.
spark fact, to achieve DGA + borg system computing model, including resource management and scheduling cluster storage system implementation, DGA computing model to achieve; so when we look at the source code spark when it will be tens of thousands of lines of code and a variety of reliance contracted confused. Because it is already a complete system, when you put this system is how to constitute a dissected, divided into several parts module, go read the code but the code will find the remains complex rule-based organization is hierarchical; too slow slow can understand why spark include those modules.
As FIG spark should include
- Spark RPC
- Spark storage
- Spark Streaming
- Spark task scheduling
- Spark computing tasks
- Spark configuration parameter (Context context)
- Spark Metric&UI
