Article Directory
Foreword
Regular expressions very well in matching strings of text, and both support regular expressions in many languages.
I collate and analyze knowledge at the point when learning regular expressions, so I wrote this blog.
First, the regular expression
1. Concept
Regular expressions, also known as regular expressions. (English: Regular Expression, the code is often abbreviated as regex, regexp or RE), a concept in computer science. Regular expressions are typically used to retrieve, replace the text in line with those of a model (rule) is.
A regular expression is a logical formula of string operations, is to use some combination of a particular pre-defined characters, and these particular character, form a "string rule", this "rule string" is used to express characters for string filter logic.
Regular expressions (Regular expression), we often use abbreviations regex regular expression.
In short, a bunch of regular expressions is a regular string. The rules used to match a string of another string.
2. Role
Given a regular expression and another string, we can achieve the following purposes:
- Whether the given string meets the regular expression filtering logic (referred to as "matching");
- Yes, we want to get a specific part from a string by a regular expression.
With a regular string (regular expression) to match another string, can determine a match, you can get what we want from a specific part of another string (for example: you want to determine the user name entered by the user whether specification, you can use regular expressions to match).
3. Features
Regular expressions are characterized by:
- Flexibility, logic and functionality is very strong;
- You can quickly reach a very complex control character string using simple manner.
- For people who are new, relatively obscure.
Regular expressions are extremely flexible, and can be used very easily with a bunch of regular expressions to match a string (for example: write a lot of code with the code control will, however regular expression might line).
Although new to feel more difficult, things are difficult thing, but then will learn some very simple feeling!
4. Acquaintance regular expressions
4.1 Preparation
-
Software
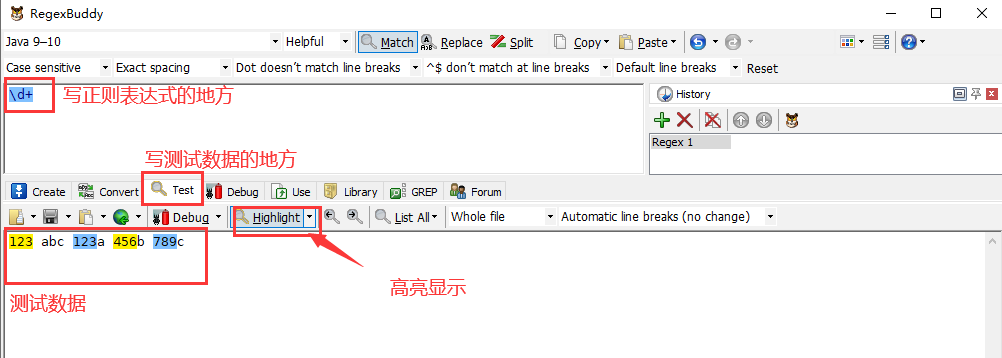
I used to learn regular expressions is software RegexBuddy ( recommended Baidu will simply use it to download).
Simple to use:
-
Website
if you want to use the site, I recommend that the rookie tutorial regular expressions online test website
link: https: //c.runoob.com/front-end/854
4.2 Basic Training
Regular expressions can be learned separately, you can use software or websites exercises.
Once familiar with the commonly used regular expressions, to the commonly used language in use regular expressions.
-
Question: Given a string "hello regex 123,456", to find all the number (as large as possible) string.
-
Solution: Use regular metacharacters (special meaning characters) and qualifier (number of repetitions) can be. (Metacharacters qualifiers and I will be mentioned below)
-
Regular Expressions:\d+ or [0-9]+
Second, the basic regular expressions
1. metacharacters (special characters)
Regular expression language consists of two basic character types: literal (normal) text characters and metacharacters. The regular expression metacharacters have processing capabilities. The so-called metacharacters refers to those special characters that have special meaning in the regular expression can be used to specify its leading characters (which is located in front of the metacharacters characters) appear in the target object.
Regular expressions depends on the yuan characters. Metacharacter does not mean the literal meaning of their own, they have a special meaning. Some meta characters written in brackets when there are some special meaning.
Metacharacters are some special meaning special characters. Meta characters are interpreted: a group of alternative characters in one or more characters.
1.1 shorthand character set (printable characters)
It is the output of printable characters can be visible on the display.
Such as: in the ASCII table, in addition to the printing characters are ASCII code 127, and 0 to 31 (total 33) is a communication control characters or special characters, the remaining characters are all printable.
| character | description |
|---|---|
| . | Matches any single character except newline \ n outside of. |
| \d | Match numbers: [0-9] |
| \D | Non-numeric Match: [^ \ d] |
| \w | Match all alphanumeric equivalent to [a-zA-Z0-9_] |
| \W | Matches all non-alphanumeric, i.e. symbols, is equivalent to: [^ \ w] |
| [ ] | Set of characters. Matches any character included (commonly 0-9 represents 0 to 9, az represents lowercase letters a through z, empathy capital letters). E.g. [ABCDE] may be matched to "hello" in the 'e'. |
1.2 shorthand character set (non-printing characters)
What non-printing characters? It refers to non-printing characters in a computer some characters are indeed exist, but they can not be displayed or printed out.
Such as: in the ASCII table, nonprintable characters are ASCII code 127, and 0 to 31 (total 33) is a communication control characters or special characters, are non-printable characters.
| character | description |
|---|---|
| \n | Matches a newline. Equivalent to \ x0a and \ cJ. |
| \r | Matching a carriage return. Equivalent to \ x0d and \ cM. |
| \t | A matching tab. Equivalent to \ x09 and \ cI. |
| \ v | Matching a vertical tab. Equivalent to \ x0b and \ cK. |
| \cx | Match control characters specified by the x. For example, \ cM matches a Control-M or carriage return. The value of x must be AZ or az. Otherwise, c as a literal 'c' character. |
| \s | Matches any whitespace characters, including spaces, tabs, page breaks, and so on. It is equivalent to [\ f \ n \ r \ t \ v]. Note Unicode Regular Expressions will match full-width space character. |
| \S | Matches any non-whitespace characters. Is equivalent to [^ \ f \ n \ r \ t \ v]. |
1.3 Qualifier
Qualifier is used to specify the regular expression of a given component must appear many times to meet the match. There? * Or + or or {n} or {n,} or {n, m} total of six kinds.
Qualifier is used to specify a certain regular expression need to be repeated many times before the match.
| character | description |
|---|---|
| ? | Matches the preceding subexpression zero or one. Such as:? Cs s indicates a match can appear in front of zero or one (0 or 1 s may be repeated twice), can be matched to C, but does not match the CS css |
| * | Matches the preceding subexpression zero or more times. Such as: cs * s which matches the front may occur zero or more times (0 s may be repeated twice or more) can be matched to c, cs, css |
| + | Matches the preceding subexpression one or more times. Such as: cs + s represents the matching front may occur one or more times (may be repeated one or more times s), it can be matched to cs, css, but does not match to c |
| {n} | n is a nonnegative integer. Matching the determined n times. Such as: cs {2} indicates a match occurs twice in front of s (s may be repeated twice or more) can be matched to css, but does not match to c, cs, csss |
| {n,} | n is a nonnegative integer. Matching at least n times. Such as: cs {2,} represents a match in front of at least 2 or more times s (s can be repeated 2 or more), can be matched to css, csss, but it does not match to cs |
| {n,m} | n and m are non-negative integers, where n <= m. Match at least n times and match up to m times. Such as: cs {2,4} indicates a match in front of at least 2 s up to four times (s may be repeated 2-4 times), it can be matched to the CSS, but does not match to the CSSS cs |
1.4 locator
Locator enables you to fix the regular expression to the beginning or end of the line. They also allow you to create such a regular expression, these regular expressions appear in a word, a word at the beginning or end of a word.
Locator used to describe a string or word boundaries, and $ ^ denote the beginning and end of the string, \ b described boundaries before or after the word, \ B represents a non-word boundary.
| character | description |
|---|---|
| ^ | Matches the beginning of the string. Another use of the ^: using (e.g., [^]) expression in the square brackets, when the symbols in square brackets expression, does not accept the brackets indicates expression set of characters. |
| $ | Match the end position of the input string. |
| \b | Matches a word boundary, that is, the position between a word and a space. |
| \B | Non-word boundary matching. |
1.5 Special characters
Special characters refers to characters that have special meaning. If you need to use special characters of the original character, need to use the escape character \ to escape (eg: you want to match the ^ character, you need to write \ ^).
| character | description |
|---|---|
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。’\n’ 匹配换行符。序列 ‘\\’ 匹配 “\”,而 ‘\(’ 则匹配 “(”。 |
| . | 匹配除换行符 \n 之外的任何单字符。 |
| ? , * , +, { } | 请查看上面1.3 限定符。 |
| ^ 和 $ | 请查看上面1.4 定位符。 |
| ( ) | 捕获组,用来把正则表达式中子表达式匹配的内容,保存到内存中,用数字标号或显示命名的组里,方便后面引用。 |
| [ | 表示字符集合的开始。经常与 ] 搭配使用,[] 表示字符集合,匹配所包含的任意一个字符。例如 [abcde] 可以匹配到 “hello” 中的 ‘e’。 |
| | | 或运算符。例如,正则 c|s 将匹配 c 或者 s |
三、正则表达式进阶
1.零宽断言
用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。
这名词可能有点难理解,我用我的理解来解释一下:
-
零宽:就是0宽度,没有宽度(就是正则匹配时不包含这些内容)。
-
断言:断定某个位置满足一定条件的言论(就是断定某个位置,这个位置应该是满足一定条件的)。
-
零宽断言简单理解:就是像定位符 \b,^,$ 一样用来指定某个位置,断定某个位置一定有满足某个条件的表达式。
| 字符 | 描述 |
|---|---|
| (?=pattern) | 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)“能匹配"Windows2000"中的"Windows”,但不能匹配"Windows3.1"中的"Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?<=pattern) | 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,"(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。 |
| (?!pattern) | 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如"Windows(?!95|98|NT|2000)“能匹配"Windows3.1"中的"Windows”,但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?<!pattern) | 反向否定预查,与正向否定预查类似,只是方向相反。例如"(?<!95|98|NT|2000)Windows"能匹配"3.1Windows"中的"Windows",但不能匹配"2000Windows"中的"Windows"。 |
1.1 正向肯定预查
正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)“能匹配"Windows2000"中的"Windows”,但不能匹配"Windows3.1"中的"Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
- 语法:(?=pattern)
- 正则: Windows(?=95|98|NT|2000)
- 正则解释:匹配Windows,后面为95或98或NT或2000的字符串(匹配结果仅包含Windows)。
1.2 反向肯定预查
反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,"(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。
- 语法:(?<=pattern)
- 正则: (?<=95|98|NT|2000)Windows
- 正则解释:匹配Windows,前面为95或98或NT或2000的字符串(匹配结果仅包含Windows)。
1.3 正向否定预查
正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如"Windows(?!95|98|NT|2000)“能匹配"Windows3.1"中的"Windows”,但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
- 语法:(?!pattern)
- 正则: Windows(?!95|98|NT|2000)
- 正则解释:匹配Windows,后面不为95或98或NT或2000的字符串(匹配结果仅包含Windows)。
1.4 反向否定预查
反向否定预查,与正向否定预查类似,只是方向相反。例如"(?<!95|98|NT|2000)Windows"能匹配"3.1Windows"中的"Windows",但不能匹配"2000Windows"中的"Windows"。
- 语法:(?<!pattern)
- 正则: (?<!95|98|NT|2000)Windows
- 正则解释:匹配Windows,前面 不 为95或98或NT或2000的字符串(匹配结果仅包含Windows)。
四、正则表达式补充
1.捕获
| 字符 | 描述 |
|---|---|
| ( ) | 捕获组,用来把正则表达式中子表达式匹配的内容,保存到内存中,用数字标号或显示命名的组里,方便后面引用。 |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,’(.)\1’ 匹配两个连续的相同字符。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 “或” 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 ‘industry|industries’ 更简略的表达式。 |
1.1 捕获组
捕获组,用来把正则表达式中子表达式匹配的内容,保存到内存中,用数字标号或显示命名的组里,方便后面引用。
捕获组 () 我们在 二、正则表达式基础的 中的 1.5 特殊字符 看到过。
正则表达式会左侧开始,每出现一个左括号"("记做一个分组,分组编号从 1 开始。0 代表整个表达式。
- 语法:(pattern)
- 正则: ([1-9])(\d)
- 正则解释:匹配一个两位数。([1-9])为捕获组1,表示1-9开头的数。(\d)为捕获组2,表示任意一个数(匹配结果包含12)。
1.2 反向引用
匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,’(.)\1’ 匹配两个连续的相同字符。
上面讲的捕获组,会给每一对括号记作一个分组,分组编号从 1 开始。0 代表整个表达式。现在我们学捕获组的引用(反向引用)。
- 语法:\num
- 正则: ([1-9])(\d)\2
- 正则解释:匹配一个三位数。([1-9])为捕获组1,表示1-9开头的数。(\d)为捕获组2,表示任意一个数。\2表示反向引用捕获组2( 即(\d) )(匹配结果包含122)。
1.3 非捕获组
匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 “或” 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 ‘industry|industries’ 更简略的表达式。
- 语法:(?:pattern)
- 正则: industr(?:y|ies)
- 正则解释:匹配industr,结尾为y或ies的字符串(匹配结果包含y和ies)。
2.贪婪匹配与非贪婪匹配 + 否定字符集
‘?’ 和 ‘^’ 这两个元字符我们在 二、正则表达式基础的 中的 1.3 限定符 和 1.4 定位符 看到过。
| 字符 | 描述 |
|---|---|
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m} ) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 “cs12345”,正则表达式’\d{3,}?’ 将匹配 “123”,而 ‘\d{3,}’ 将匹配 ‘12345’。 |
| ^ | 匹配输入字符串的开始位置。^的另一种用法:在方括号表达式中使用(如[^ ]),当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。 |
2.1 贪婪匹配与非贪婪
当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m} ) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 “cs12345”,正则表达式’\d{3,}?’ 将匹配 “123”,而 ‘\d{3,}’ 将匹配 ‘12345’。
- 贪婪:匹配字符串时,尽可能匹配多的字符串。例如,对于字符串"cs12345"用正则 \d{3,} 匹配时,可以匹配到12345。
- 语法:默认使用 (*, +, ?, {n}, {n,}, {n,m} ) 时,匹配模式就是贪婪的(尽可能多的匹配字符串)。
- 正则:\d{3,}
- 正则解释:匹配0-9的数字(\d)最少重复3次以上({3,})(匹配结果为12345)。
- 非贪婪:匹配字符串时,尽可能匹配少的字符串。例如,对于字符串"cs12345"用正则 \d{3,}? 匹配时,可以匹配到123,但匹配不到12345。
- 语法 使用 (*, +, ?, {n}, {n,}, {n,m} ) 时,在这六个限定符后加上?
- 正则:\d{3,}
- 正则解释:匹配0-9的数字(\d)最少重复3次以上({3,})且是非贪婪的(?)(匹配结果为123)。
2.2 否定字符集
匹配输入字符串的开始位置。^的另一种用法:在方括号表达式中使用(如[^ ]),当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。
和字符集 [ ] 搭配使用,表示不包含在某个字符集的字符。例如,"[^a-z]" 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。
- 语法:[^]
- 正则: [^a-z]
- 正则解释:匹配任何非a-z字母的单个字符。
五、总结
以上就是我学习时的笔记了,每个知识点推荐自己写一些案例来进行测试,这样会更容易理解。
参考
正则表达式百度百科:https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F/1700215?fr=aladdin
菜鸟正则表达式教程:https://www.runoob.com/regexp/regexp-tutorial.html(推荐)
learn-regex:https://github.com/ziishaned/learn-regex/blob/master/translations/README-cn.md
相关
菜鸟正则表达式在线测试:https://c.runoob.com/front-end/854
