Today try to crawl a small video website video (of course, not everyone wants that little video): www.vmovier.com
After a start that directly link into the page using xpath match on the line test found that the site uses lazy loading techniques so direct method does not work to climb not completely match all the video link
So I grabbed it loads the interface: https://www.vmovier.com/post/getbytab?tab=new&page=3&pagepart=1
Where the page parameter is the number of pages, pagepart parameter is how many times each page load, each page has been tested and found three loaded, where you can use a loop to achieve
= int Page (the INPUT ( " Please enter the number of pages you want crawled: " )) # The capture interface to take over because it is dynamic pages capture interface to send data to the interface # Page = pages per first few pagepart = there are three refresh refresh each page are 123 could write a loop for T in the Range (1, 4 ): url = " https://www.vmovier.com/post/getbytab?tab=new&page=% S & pagepart = D% " % (Page, T) # Print (URL) # Exit ()
Then the main problem of this paper is that the interface is said to be returning json data format, but I find that is not open standard json format:
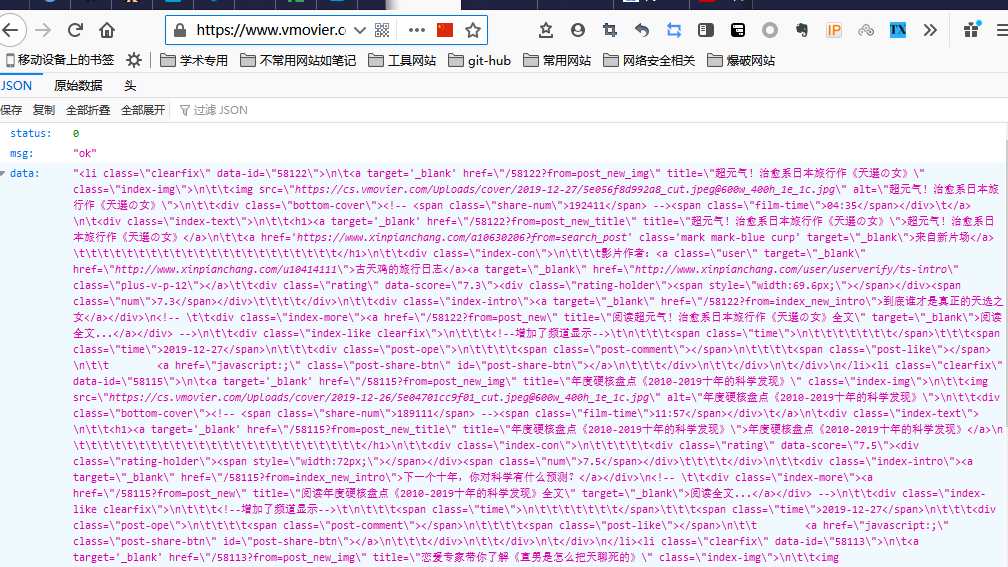
Here I strongly condemn this programmer interface development, I spent a long time to look for other solutions
Below this one is something I want to filter out:

Began to think of a dictionary is to obtain data part, converted to HTML format, use xpath to filter titles and video links I need, but was found not work, and finally I chose to use a regular method of matching, have to say regular Zhendi strong:
import requests from bs4 import BeautifulSoup import time from lxml import etree import re import json #添加头部 作为全局 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' } url = "https://www.vmovier.com/post/getbytab?tab=new&page=3&pagepart=1" r = requests.get(url=url,headers=headers) #print(r.text) obj = json.loads(r.text) # print(obj) # exit() #取出所有和视频相关的数据 标题和url data是一个列表 里面存放的都是字典 data = obj['data'] #print(data) # # exit() # tree = etree.HTML(data) # title = tree.xpath('//div[@class ="index-more"]') # print(title) match_obj_url = re.compile(r'<a href="(.*)" title=".*全文" target="_blank">阅读全文...</a>') url = re.findall(match_obj_url,data) print(url) match_obj_title = re.compile(r'<a href=".*" title="(.*)全文" target="_blank">阅读全文...</a>') title = re.findall(match_obj_title,data) print(title) exit()

费了2个多小时的时间,可算搞出来了后面获得这个url还不是最终视频的url 竟然还有个跳转 真是块难啃的骨头,但是应该问题不大,先记录一下这个问题,以后遇到再看看 不管开发人员多么狡猾 我都要攻克你们