In fact, in order to improve the efficiency of data queries, just like the book directory as the index appears. A 500-page book, if you want to quickly find a particular knowledge of them, without the aid of a directory, then I guess you may have to look for a while. Similarly, for database tables, the index is actually its "directory."
But the index is not always add enough? A book 100 index suitable for you? The index file is nature, and not zero consumption.
Index common model: the hash table, ordered array, search trees.
Hash table is a kind of key - value (key-value) for storing data structure, as long as the input value to be searched i.e. we key, it can be found that is a value corresponding to Value. Hash idea is very simple, the values in the array, using a hash function to convert into a key position determined, then the value placed in this position in the array. Inevitably, multiple key value after conversion hash function, there will be a case of the same value. A method of handling this situation is drawn a list. If too long, it will degenerate into a linked list.
Suppose you now maintains a list of names and identity information, you need to find the corresponding name based on the ID number, then the corresponding schematic hash index is as follows:
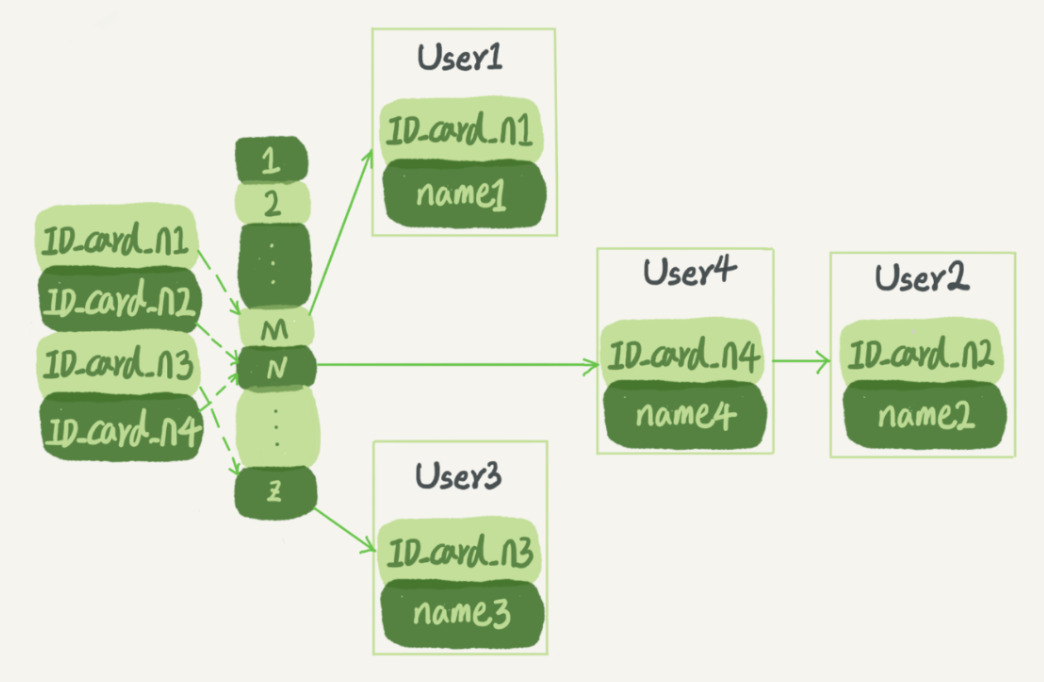
How to search for it? User2 will be able to see and understand user4 first id_card then name.
FIG, User2 User4 and calculated values are based on the ID number N, but it does not matter, even went back a list. Assume that this time you want to check what ID_card_n2 corresponding name is, the processing step is this: First, the ID_card_n2 N calculated by a hash function; then, in order to traverse to find User2.
It should be noted that the value of the figure four ID_card_n is not increasing, the benefits of doing so is to add a new User speed quickly, only later added. But the drawback is, because it is not ordered, so do hash index range query speed is very slow.
For example, you want to search [ID_card_X, ID_card_Y] all users can scan the entire table again.
Therefore, this structure is suitable for hash table scene only equivalent queries, such as Memcached and some other NoSQL engines. What is the equivalent query is this data is not changing.
The ordered array of performance equivalent queries and range queries on the scene are excellent. The above example is based on the ID number to check the name, if we use an ordered array to achieve it, a schematic diagram is shown below:

At the same time it is clear that this index structure to support range queries. You have to check the ID number in [ID_card_X, ID_card_Y] User section, you can find a dichotomy ID_card_X (if ID_card_X does not exist, find the first of a User is greater than ID_card_X), then traverse to the right until the first found a greater than ID_card_Y ID number, exit the loop.
If you just look at the query efficiency and orderly array is the best data structure of. However, when data needs to be updated in trouble, you insert a record into the middle of it all have to move the recording back, the cost is too high.
So, orderly array index is only applicable to static storage engine, for example, you want to save all the demographic information of a city in 2017, these data will not be modified.
Binary search tree is a classic textbook in the data structure. It is the mainstream model, if not familiar tree structure learning MySQL is not necessary to learn. According to the example above ID number or the name of the check, if we use binary search trees come true, a schematic diagram is shown below:
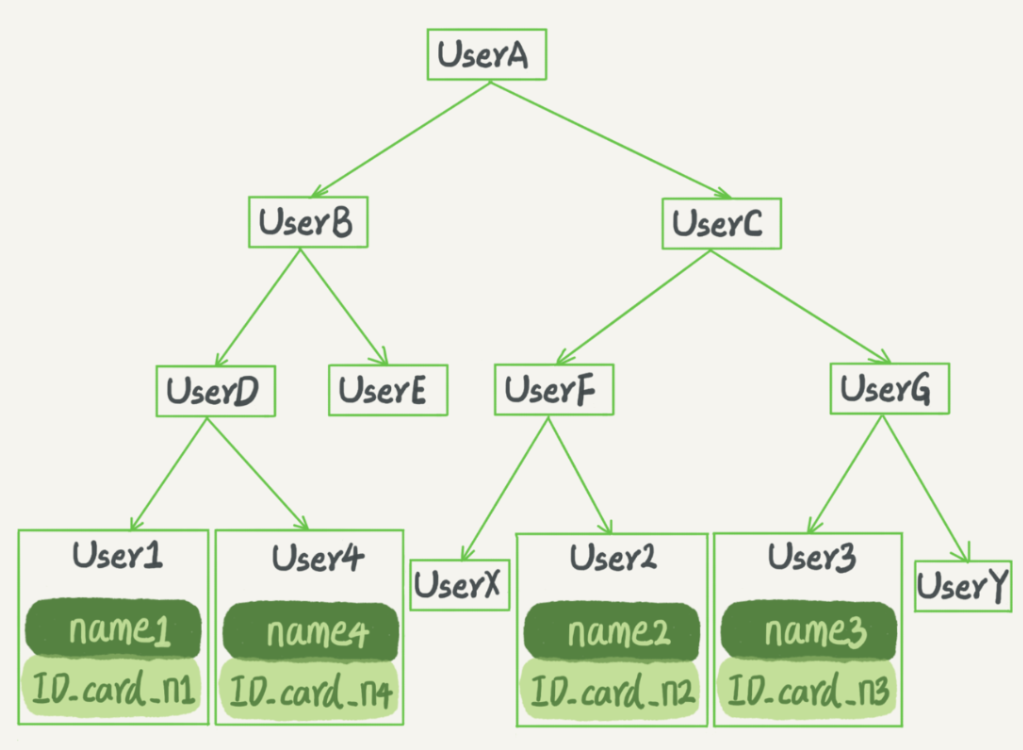
It features binary search tree is: the left son of each node is less than the parent, the parent node and less than the right son. So if you want to check ID_card_n2 words, according to the figures of the search order is in accordance with UserA -> UserC -> UserF -> User2 get this path. The time complexity is O (log (N)).
Of course, in order to maintain the query complexity O (log (N)), you will need to keep this tree is a balanced binary tree. In order to do this assurance, the update time complexity is O (log (N)).
There may be a binary tree, how can fork. Multi-tree is that each node has more sons, the size of the increment between the son of guarantee from left to right. Binary tree search is the most efficient, but in fact most of the database storage but do not use a binary tree. The reason is that there is more than the index in memory, but also written to disk.
你可以想象一下一棵100万节点的平衡二叉树,树高20。一次查询可能需要访问20个数据块。在机械硬盘时代,从磁盘随机读一个数据块需要10 ms左右的寻址时间。也就是说,对于一个100万行的表,如果使用二叉树来存储,单独访问一个行可能需要20个10 ms的时间,这个查询可真够慢的。
为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块。那么,我们就不应该使用二叉树,而是要使用“N叉”树。这里,“N叉”树中的“N”取决于数据块的大小。
以InnoDB的一个整数字段索引为例,这个N差不多是1200。这棵树高是4的时候,就可以存1200的3次方个值,这已经17亿了。考虑到树根的数据块总是在内存中的,一个10亿行的表上一个整数字段的索引,查找一个值最多只需要访问3次磁盘。其实,树的第二层也有很大概率在内存中,那么访问磁盘的平均次数就更少了。
其实也就是B树
作为人类认识自然及生产实践的重要工具,自其诞生以来短短的近 60 年间,现代电子计算机 的发展速度超过了历史上的任何一种其它工具。就计算能力而言,初的ENIAC㈠每秒只能够执行 5000 次加法运算,而今天的“蓝色基因”每秒已经能够执行 7×1013次浮点运算 ㈡。就存贮能力而言, 情况似乎也是如此:ENIAC只有一万八千个电子管,而今天即使是售价不过数百元的普通硬盘,存 贮容量也能达到 100GB,内存的常规容量也已达到GB量级。
然而,从实际应用的需求来看,问题规模的扩张速度要远远高于计算机存贮能力的增长速度。 以数据库为例,在上世纪八十年代初,典型数据库的规模为 10~100MB;廿年后的今天,典型数据 库的规模已经需要以 TB 为单位来计量。相对于如此的发展速度,计算机存贮能力的增长速度远远 滞后,而且随着时间推移,这一矛盾日益尖锐。 另一方面,几乎所有类型的存贮器都具有一个共同的特性: 容量越大,速度越慢;反之,容量 越小,速度越快。因此,一味提高存贮器容量的做法也是不切实际的。
为了解决上述矛盾,一种有效的方法就是分级存贮。以简单的二级分级存贮策略为例,这样 的典型实例之一,就是由内存与外存(磁盘)组成的二级存贮系统。这一策略的构思是: 将整个数 据库存放于外存中,同时在内存中存放常用数据的复本。这样,借助于有效算法,可以将内存高 速度的优点与外存大容量的优点结合起来,而此时的内存则扮演了高速缓存的角色。
实际上,在分级存贮系统中,各级存贮器的速度不仅有所差异,而且通常极其悬殊。还是以内 存与磁盘为例,前者的访问速度一般在 10~100ns 左右,而后者的访问速度约在 10ms 左右,二者 之差高达 5 到 6 个数量级。如果把对内存的访问比作随手拿起书桌上的钢笔,那么对外存的访问就 相当于乘火车从北京到广州某办公室的书桌上拿起钢笔,然后再乘火车返回。因此,为了省去对外 存的一次访问,我们宁愿多访问内存一百次、一千次甚至一万次。也正因为这一原因,在衡量此类 算法时,我们会更多地考虑其涉及的外存访问次数,而忽略内存操作的次数。
当问题规模很大,以至于内存无法容纳时,即使是前面介绍的平衡二分查找树,在效率方面仍 大打折扣。而下面将要介绍的 B-树,却是能够高效解决这类问题的一种数据结构。例如,若将存放 于外存的 1G 个记录组织为 AVL 树,则每次访问需要做约 30 次外存访问;而如果采用 256 阶 B-树, 则每次访问对应的外存访问次数将减少至 4~5 次。(邓俊辉)
所谓m阶B-树 ㈠,即满足以下条件的m路平衡查找树:其中的每一内部节点, 都存有n个关键码{K1 < K2 < ... < Kn}和n+1 个引用{A0, A1, A2, ..., An},n+1 ≤ m。对于每一非根内部 节点,都有n+1 ≥ ⎡m/2⎤;对于根节点,除非它同时也是叶子,否则必有n+1 ≥ 2。 每个引用 Ai分别指向一棵子树 Ti,而且若 i ≥ 1,则 Ti中的每一关键码 key 都满足 key > Ki;若 i ≤ n-1,则 Ti中的每一关键码 key 都满足 key < Ki+1。与一般的查找树不同,为了简化叙述,这里我 们假定 B-树中的所有关键码互异。 另外,所有叶子节点的深度相等,即它们都处于同一层。

并不是讲数据结构,所以简单介绍了一下B树。
InnoDB 的索引模型
在InnoDB中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。又因为前面我们提到的,InnoDB使用了B+树索引模型,所以数据都是存储在B+树中的。、
举例
假设,我们有一个主键列为ID的表,表中有字段k,并且在k上有索引。
这个表的建表语句是:
mysql> create table T( id int primary key, k int not null, name varchar(16), index (k))engine=InnoDB;
表中R1~R5的(ID,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)和(600,6),两棵树的示例示意图如下。
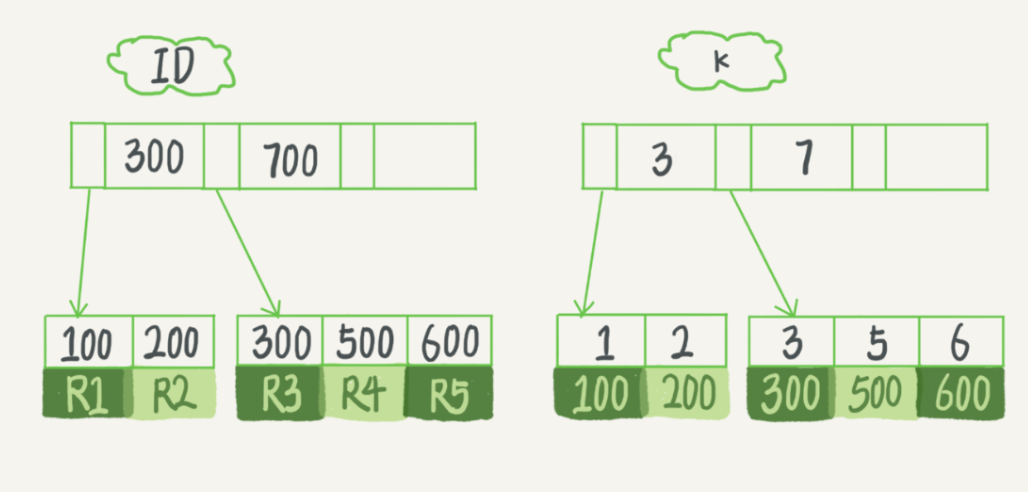
从图中不难看出,根据叶子节点的内容,索引类型分为主键索引和非主键索引。
主键索引的叶子节点存的是整行数据。在InnoDB里,主键索引也被称为聚簇索引(clustered index)。
非主键索引的叶子节点内容是主键的值。在InnoDB里,非主键索引也被称为二级索引(secondary index)。
那么区别在哪?
- 如果语句是select * from T where ID=500,即主键查询方式,则只需要搜索ID这棵B+树;
- 如果语句是select * from T where k=5,即普通索引查询方式,则需要先搜索k索引树,得到ID的值为500,再到ID索引树搜索一次。这个过程称为回表。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
索引维护
B+树为了维护索引有序性,在插入新值的时候需要做必要的维护。以上面这个图为例,如果插入新的行ID值为700,则只需要在R5的记录后面插入一个新记录。如果新插入的ID值为400,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置。
而更糟的情况是,如果R5所在的数据页已经满了,根据B+树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。在这种情况下,性能自然会受影响。
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约50%。
当然有分裂就有合并。当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。合并的过程,可以认为是分裂过程的逆过程。
基于上面的索引维护过程说明,我们来讨论一个案例:
你可能在一些建表规范里面见到过类似的描述,要求建表语句里一定要有自增主键。当然事无绝对,我们来分析一下哪些场景下应该使用自增主键,而哪些场景下不应该。
自增主键是指自增列上定义的主键,在建表语句中一般是这么定义的: NOT NULL PRIMARY KEY AUTO_INCREMENT
插入新记录的时候可以不指定ID的值,系统会获取当前ID最大值加1作为下一条记录的ID值。
也就是说,自增主键的插入数据模式,正符合了我们前面提到的递增插入的场景。每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。
而有业务逻辑的字段做主键,则往往不容易保证有序插入,这样写数据成本相对较高。
除了考虑性能外,我们还可以从存储空间的角度来看。假设你的表中确实有一个唯一字段,比如字符串类型的身份证号,那应该用身份证号做主键,还是用自增字段做主键呢?
由于每个非主键索引的叶子节点上都是主键的值。如果用身份证号做主键,那么每个二级索引的叶子节点占用约20个字节,而如果用整型做主键,则只要4个字节,如果是长整型(bigint)则是8个字节。
显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
所以,从性能和存储空间方面考量,自增主键往往是更合理的选择。
有没有什么场景适合用业务字段直接做主键的呢?还是有的。比如,有些业务的场景需求是这样的:
-
只有一个索引;
-
该索引必须是唯一索引。
你一定看出来了,这就是典型的KV场景。
由于没有其他索引,所以也就不用考虑其他索引的叶子节点大小的问题。
这时候我们就要优先考虑上一段提到的“尽量使用主键查询”原则,直接将这个索引设置为主键,可以避免每次查询需要搜索两棵树。
重建索引
alter table T drop index k;
alter table T add index(k);
alter table T drop primary key;
alter table T add primary key(id);
索引可能因为删除,或者页分裂等原因,导致数据页有空洞,重建索引的过程会创建一个新的索引,把数据按顺序插入,这样页面的利用率最高,也就是索引更紧凑、更省空间。
重建索引k的做法是合理的,可以达到省空间的目的。但是,重建主键的过程不合理。不论是删除主键还是创建主键,都会将整个表重建。所以连着执行这两个语句的话,第一个语句就白做了。
小结
由于InnoDB是索引组织表,一般情况建议你创建一个自增主键,这样非主键索引占用的空间最小。但事无绝对。