HashTable source code analysis
More please pay attention to public resources and tutorials number: non-Coban Coban .
If you think I write can also Give me praise, thank you, your encouragement is my creative power
### 1. Introduction
Hashtable a veteran of the collections, as early as in JDK 1.0 was born
### 1.1 Summary
In the first chapter of a collection series, we learned, Map implementation class has HashMap, LinkedHashMap, TreeMap, IdentityHashMap, WeakHashMap, HashTable, Properties and so on. 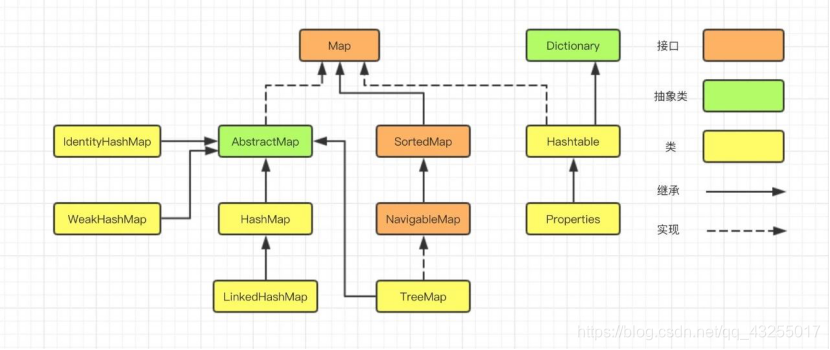
### 1.2 Introduction
Hashtable a veteran of the collections, as early as in JDK 1.0 was born, and born in the HashMap JDK 1.2, in the realization, HashMap Hashtable absorbed a lot of thought, although the underlying data structures are both + array linked list structure, with a query, insert, delete and quickness, but both have many differences.
Hashtable open source code can be seen, Hashtable inherited from the Dictionary, and HashMap inherited from AbstractMap.
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
.....
}HashMap inherited from AbstractMap, HashMap class defined as follows:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
.....
}Hashtable and underlying HashMap based array to store the same time, the data is stored in an array by key subject at the time, so the possibility is hash algorithm-based hash collisions may produce calculations.
popular say, is a different key, when calculated, may produce the same array index, at this time, how the two objects into an array it?
The way to resolve hash collision, there are two, an open address mode (when the hash conflict, in order to continue to keep looking until you find the hash values do not conflict), the other is the way the zipper (the conflict the element into a linked list).
Java Hashtable use is the second way zipper law!
Thus, when generating a different key acquired at the same time the subject of the array, the array will be the object into a container, and then the objects stored in the same way a standard linked list array through a series of hashing algorithm container, just as chains, hanging on a node, as shown below: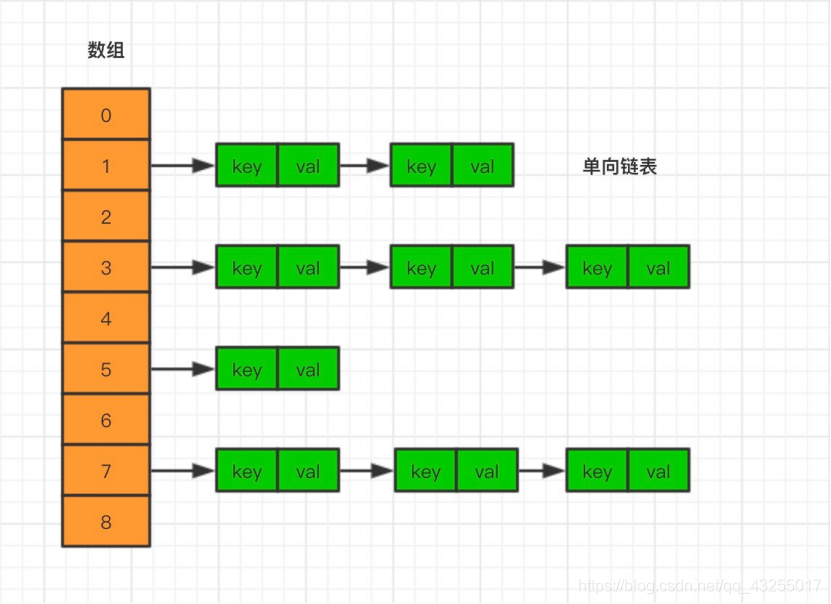
与 HashMap 类似,Hashtable 也包括五个成员变量:
/**由Entry对象组成的数组*/
private transient Entry[] table;
/**Hashtable中Entry对象的个数*/
private transient int count;
/**Hashtable进行扩容的阈值*/
private int threshold;
/**负载因子,默认0.75*/
private float loadFactor;
/**记录修改的次数*/
private transient int modCount = 0;DETAILED the variables have the following meanings:
table: Entry represents an array of list of objects, Entry is a singly linked list, the hash table key-value pair is stored in the Entry key array;
count: Hashtable represents size for recording Holds the number of key-value pairs;
threshold: threshold represents a Hashtable, for determining whether to adjust the capacity of Hashtable, * equal to the capacity load factor threshold;
loadFactor: represents the load factor, the default is 0.75;
modCount: record Hashtable represents the number of changes, failure to achieve rapid throw exception handling;
Next look at the Entry inner class, for storing a linked list data Entry realized Map.Entry interface is essentially a mapping (key-value pairs), the following source code:
private static class Entry<K,V> implements Map.Entry<K,V> {
/**hash值*/
final int hash;
/**key表示键*/
final K key;
/**value表示值*/
V value;
/**节点下一个元素*/
Entry<K,V> next;
......
}Let us then take a look at Hashtable initialization process, the core source code is as follows:
public Hashtable() {
this(11, 0.75f);
}this calls his own construction method, the core source code is as follows:
public Hashtable(int initialCapacity, float loadFactor) {
.....
//默认的初始大小为 11
//并且计算扩容的阈值
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}HashTable can see the default initial size is 11, if the initialization of a given capacity size, so you HashTable will directly use a given size;
Expansion threshold threshold equal to initialCapacity * loadFactor, we take a look at HashTable expansion, as follows:
protected void rehash() {
int oldCapacity = table.length;
//将旧数组长度进行位运算,然后 +1
//等同于每次扩容为原来的 2n+1
int newCapacity = (oldCapacity << 1) + 1;
//省略部分代码......
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
}We can see, HashTable each expansion to the original 2n + 1.
We look at HashMap, if the implementation of the default constructor, that will be in the expansion step, the size is initialized, the core source code is as follows:
final Node<K,V>[] resize() {
int newCap = 0;
//部分代码省略......
newCap = DEFAULT_INITIAL_CAPACITY;//默认容量为 16
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
}It can be seen HashMap default initialization size is 16, we look at, HashMap expansion method, the core source code is as follows:
final Node<K,V>[] resize() {
//获取旧数组的长度
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int newCap = 0;
//部分代码省略......
//当进行扩容的时候,容量为 2 的倍数
newCap = oldCap << 1;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
}可以看出 HashMap 的扩容后的数组数量为原来的 2 倍;
也就是说 HashTable 会尽量使用素数、奇数来做数组的容量,而 HashMap 则总是使用 2 的幂作为数组的容量。
我们知道当哈希表的大小为素数时,简单的取模哈希的结果会更加均匀,所以单从这一点上看,HashTable 的哈希表大小选择,似乎更高明些。
Hashtable 的 hash 算法,核心代码如下:
//直接计算key.hashCode()
int hash = key.hashCode();
//通过除法取余计算数组存放下标
// 0x7FFFFFFF 是最大的 int 型数的二进制表示
int index = (hash & 0x7FFFFFFF) % tab.length;从源码部分可以看出,HashTable 的 key 不能为空,否则报空指针错误!
但另一方面我们又知道,在取模计算时,如果模数是 2 的幂,那么我们可以直接使用位运算来得到结果,效率要大大高于做除法。所以在 hash 计算数组下标的效率上,HashMap 却更胜一筹,但是这也会引入了哈希分布不均匀的问题, HashMap 为解决这问题,又对 hash 算法做了一些改动,具体我们来看看。
HashMap 的 hash 算法,核心代码如下:
/**获取hash值方法*/
static final int hash(Object key) {
int h;
// h = key.hashCode() 为第一步 取hashCode值(jdk1.7)
// h ^ (h >>> 16) 为第二步 高位参与运算(jdk1.7)
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);//jdk1.8
}
/**获取数组下标方法*/
static int indexFor(int h, int length) {
//jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的
return h & (length-1); //第三步 取模运算
}
HashMap 由于使用了2的幂次方,所以在取模运算时不需要做除法,只需要位的与运算就可以了。但是由于引入的 hash 冲突加剧问题,HashMap 在调用了对象的 hashCode 方法之后,又做了一些高位运算,也就是第二步方法,来打散数据,让哈希的结果更加均匀。
###1.3.常用方法介绍
####1.3.1.put方法
put 方法是将指定的 key, value 对添加到 map 里。
put 流程图如下: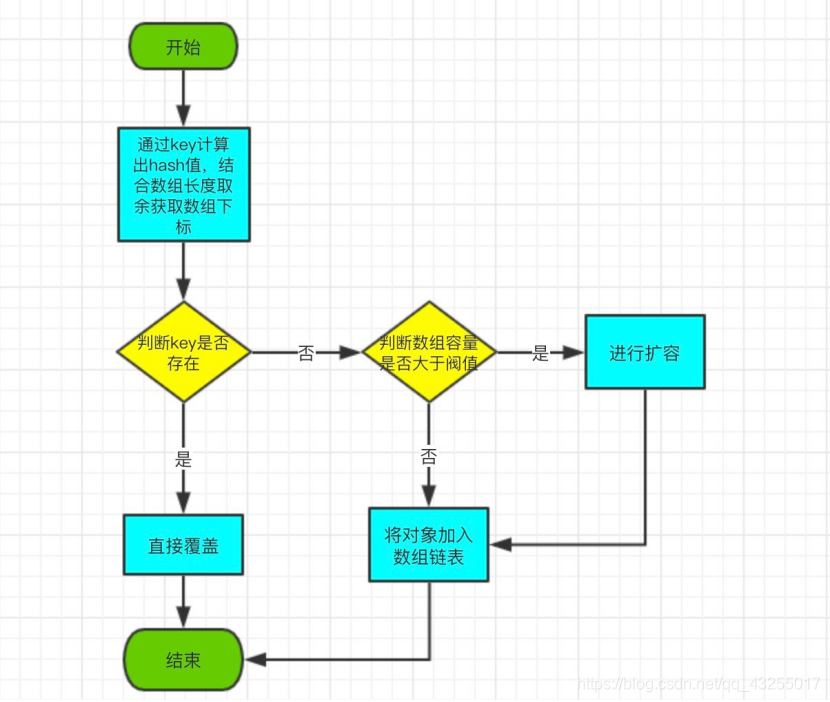
打开 HashTable 的 put 方法,源码如下:
public synchronized V put(K key, V value) {
//当 value 值为空的时候,抛异常!
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
//通过key 计算存储下标
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
//循环遍历数组链表
//如果有相同的key并且hash相同,进行覆盖处理
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
//加入数组链表中
addEntry(hash, key, value, index);
return null;
}put 方法中的 addEntry 方法,源码如下:
private void addEntry(int hash, K key, V value, int index) {
//新增修改次数
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
//数组容量大于扩容阀值,进行扩容
rehash();
tab = table;
//重新计算对象存储下标
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
//将对象存储在数组中
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
addEntry 方法中的 rehash 方法,源码如下:
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
//每次扩容为原来的 2n+1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
//大于最大阀值,不再扩容
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
//重新计算扩容阀值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
//将旧数组中的数据复制到新数组中
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}总结流程如下:
1、通过 key 计算对象存储在数组中的下标;
2、如果链表中有 key,直接进行新旧值覆盖处理;
3、如果链表中没有 key,判断是否需要扩容,如果需要扩容,先扩容,再插入数据;
有一个值得注意的地方是 put 方法加了synchronized关键字,所以,在同步操作的时候,是线程安全的。
####1.3.2.get方法
get 方法根据指定的 key 值返回对应的 value。
get 流程图如下: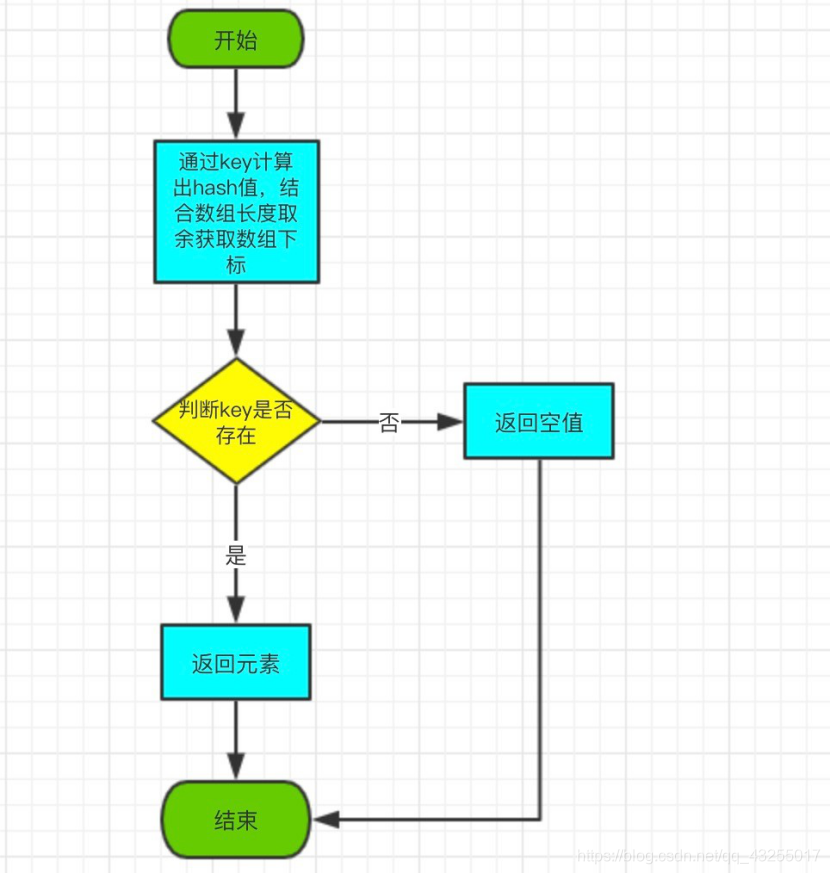
打开 HashTable 的 get 方法,源码如下:
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
//通过key计算节点存储下标
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
同样,有一个值得注意的地方是 get 方法加了synchronized关键字,所以,在同步操作的时候,是线程安全的。
####1.3.3.remove方法
remove 的作用是通过 key 删除对应的元素。
remove 流程图如下: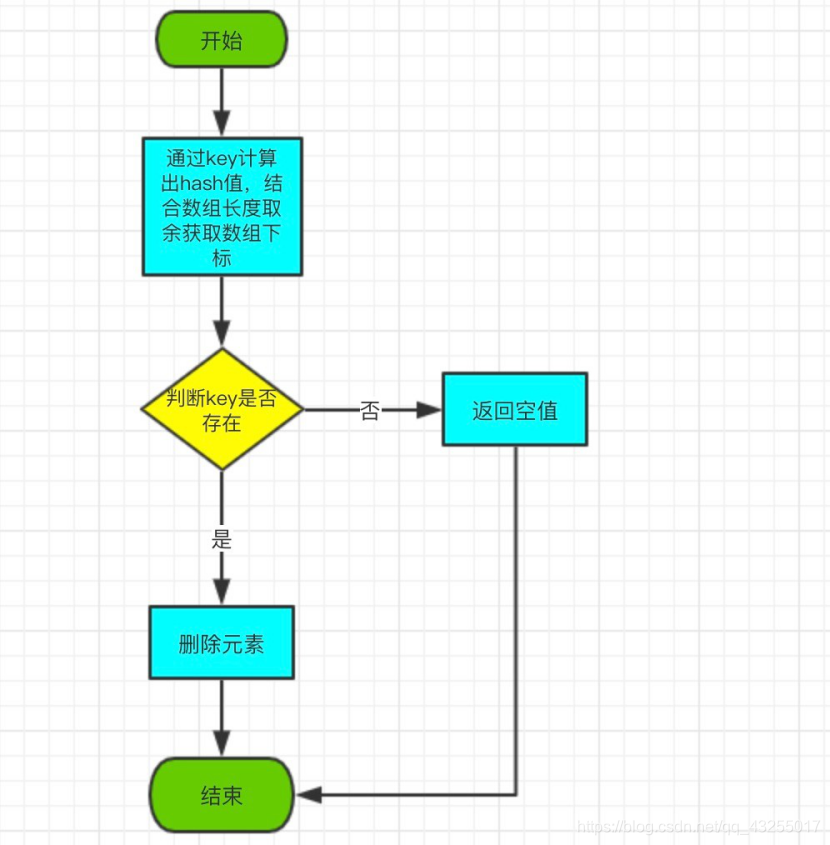
打开 HashTable 的 remove 方法,源码如下:
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
//通过key计算节点存储下标
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
Entry<K,V> e = (Entry<K,V>)tab[index];
//循环遍历链表,通过hash和key判断键是否存在
//如果存在,直接将改节点设置为空,并从链表上移除
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
同样,有一个值得注意的地方是 remove 方法加了synchronized关键字,所以,在同步操作的时候,是线程安全的。
####1..3.4.总结
总结一下 Hashtable 与 HashMap 的联系与区别,内容如下:
1、虽然 HashMap 和 Hashtable 都实现了 Map 接口,但 Hashtable 继承于 Dictionary 类,而 HashMap 是继承于 AbstractMap;
2、HashMap 可以允许存在一个为 null 的 key 和任意个为 null 的 value,但是 HashTable 中的 key 和 value 都不允许为 null;
3、Hashtable 的方法是同步的,因为在方法上加了 synchronized 同步锁,而 HashMap 是非线程安全的;
尽管,Hashtable 虽然是线程安全的,但是我们一般不推荐使用它,因为有比它更高效、更好的选择 ConcurrentHashMap,在后面我们也会讲到它。
最后,引入来自 HashTable 的注释描述:
If a thread-safe implementation is not needed, it is recommended to use HashMap in place of Hashtable. If a thread-safe highly-concurrent implementation is desired, then it is recommended to use java.util.concurrent.ConcurrentHashMap in place of Hashtable.
简单来说就是,如果你不需要线程安全,那么使用 HashMap,如果需要线程安全,那么使用 ConcurrentHashMap。
更多资源和教程请关注公众号:非科班的科班。
努力不一定成功,但是放弃一定失败,把过程留给自己,把结果留给他人,当你的才华撑不起你的雄心的时候,你就应该好好努力了
The last wave of java to share resources, including resources from java to develop a full set of video entry, as well as java 26 projects, resources relatively large size is probably about 290g, easily link failure, access to public concern is the number of ways: non Coban after Coban, let reply: java project you can get, I wish you all happy to learn