Original link: https://blog.csdn.net/xufive/article/details/102726739
Citation is as follows:
Whether or py2 py3, use unicode encoded as memory, referred to in the code. The python interpreter stored in the text memory, output to the screen, editor, or saved to a file, the code must be converted into utf8 or gbk encoding format; Similarly, the python interpreter receives text from the input device, or read text from the file when utf8 be converted or encoded into other gbk unicode encoding format. Therefore, whether or py2 Py3, want to convert between unicode, utf8, gbk encoding format, it is common to the FIG:

The reason why we will produce confused, because py2 and py3 to these encoding format specifies the confusing name. py2 string There are two types: unicode type and type str. py2 of unicode unicode encoding type is, py2 refers to all types of encoding str except unicode encoding, comprising ascii coding, coding UTF8, GBK coding, coding cp936. py3 strings there are two types: bytes type and type str. The py3 str unicode encoding type is, py3 of bytes encoding refers to all types except unicode encoding, comprising ascii coding, coding UTF8, GBK coding, coding cp936. Str also type in py2 and py3 completely upside down! The following figure slightly to add a bit of content, but also help to understand the coding problem.
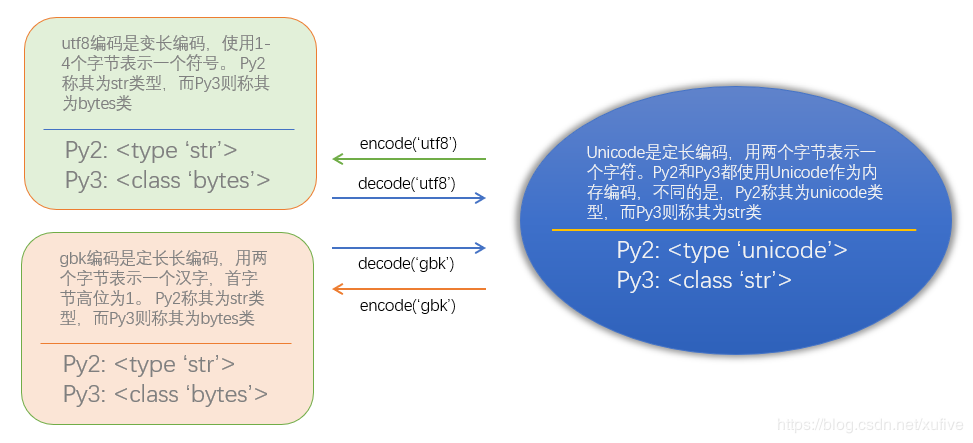
Next, we look at practical exercise.
>>> s = 'abc天圆地方' >>> type(s) <class 'str'> >>> len(s) 7 >>> s 'abc天圆地方' >>> print(s) abc天圆地方 >>> s.encode('unicode-escape') b'abc\\u5929\\u5706\\u5730\\u65b9'
不管是否在字符串前面加了u,只要不在字符串前面使用b,在IDLE中定义的字符串都是unicode编码,也就是py3的<class ‘str’>,其长度就是字符数量,不是字节数。我们把unicode字符串’abc天圆地方’转成utf8编码:
>>> s_utf8 = s.encode('utf8') >>> type(s_utf8) <class 'bytes'> >>> len(s_utf8) 15 >>> s_utf8 b'abc\xe5\xa4\xa9\xe5\x9c\x86\xe5\x9c\xb0\xe6\x96\xb9' >>> print(s_utf8) b'abc\xe5\xa4\xa9\xe5\x9c\x86\xe5\x9c\xb0\xe6\x96\xb9' >>> s_utf8.decode('utf8') 'abc天圆地方'
utf8编码就是bytes类型(字节码),长度就是字节数量。我们把unicode字符串’abc天圆地方’转成gbk编码:
>>> s_gbk= s.encode('gbk') >>> type(s_gbk) <class 'bytes'> >>> len(s_gbk) 11 >>> s_gbk b'abc\xcc\xec\xd4\xb2\xb5\xd8\xb7\xbd' >>> print(s_gbk) b'abc\xcc\xec\xd4\xb2\xb5\xd8\xb7\xbd' >>> s_gbk.decode('s_gbk') 'abc天圆地方'
gbk编码也是bytes类型(字节码),长度也是字节数量。我们再来看看,不同编码的字节码能否连接:
>>> ss = s_utf8 + s_gbk >>> ss b'abc\xe5\xa4\xa9\xe5\x9c\x86\xe5\x9c\xb0\xe6\x96\xb9abc\xcc\xec\xd4\xb2\xb5\xd8\xb7\xbd' >>> ss.decode('utf8') Traceback (most recent call last): File "<pyshell#64>", line 1, in <module> ss.decode('utf8') UnicodeDecodeError: 'utf-8' codec can't decode byte 0xcc in position 18: invalid continuation byte >>> ss.decode('gbk') 'abc澶╁渾鍦版柟abc天圆地方' >>> ss.decode('utf8', 'ignore') 'abc天圆地方abcԲط' >>> ss.decode('gbk', 'ignore') 'abc澶╁渾鍦版柟abc天圆地方'
看以看出,不同编码的字节码可以连接,但一般不能解码成unicode(字符串),除非使用ignore参数。