purpose
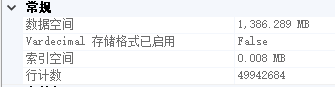
The introduction of nearly 5 million single table in a single field to Redis, stored as a list.
Program: using sqlcmd tool (SQLServer own), directly generates a command executed in Redis-cli.
A scheme using sqlcmd the print result output in the text, then the text line by line redis-cli command.
redis written list of commands.
LPUSH openids xxxx- With this result sqlserver splices
SET NOCOUNT ON;
SELECT 'LPUSH openids ' +'"' + openID +'"'
FROM [dbo].[table1] 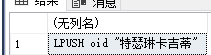
- Use sqlcmd, pushed to perform redis-cli
# -S:服务器地址,-U:账号名 -P:密码 -d:数据库 -h:列标题之间打印的行数
sqlcmd -S . -U sa -P xxxx -d DataImport -h -1 -i d:\openid.sql | redis-cli -h 192.168.xx.xx -a xxxx -p 6379 in conclusion
- You can barely succeed.
- Introducing slow, about 2w / s ~ 3w / s. Redis far below the ideal value of the write.
- Error-prone, if the value contains unexpected characters, will lead the command fails, End Task.
- Do not use this method.
Support official website:
Redis is a TCP server using the client-server model and what is called a Request/Response protocol.
This means that usually a request is accomplished with the following steps:
The client sends a query to the server, and reads from the socket, usually in a blocking way, for the server response.
The server processes the command and sends the response back to the client.
Option II: Use sqlcmd tool (SQLServer own), generated directly redis protocol execution in the Redis-cli. (You can see directly the program)
Direct command protocol generated using sqlserver
--*3:由三个参数组成:LPUSH,key,value。
--$5: 'LPUSH'的字符串长度。
--$7: 'openids'的字符串长度。
--$n: {value}的长度
--char(13): /r
--char(10): /n
SET NOCOUNT ON;
SELECT '*3'+char(13)+CHAR(10) + '$5'+char(13)+CHAR(10) + 'LPUSH'+char(13)+CHAR(10) + '$7'+char(13)+CHAR(10)
+ 'openids'+char(13)+CHAR(10) +'$'+ CAST(DATALENGTH(openID) as varchar(255)) +char(13)+CHAR(10)+openID+char(13)+CHAR(10)
FROM [dbo].[table1] # --pipe 使用管道模式
sqlcmd -S . -U sa -P xxxx -d DataImport -h -1 -i d:\openid.sql | redis-cli -h 192.168.xx.xx -a xxxx -p 6379 --pipeImplementation of the results:

(Why only 26.6 million? Because I ran twice)

in conclusion:
- Not affected by value, the interrupt operation.
- Run fast, almost 13w / s. Close to the ideal value.
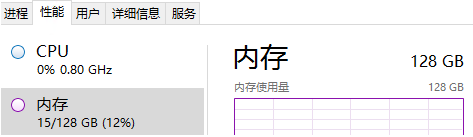
- Pro-test, for the first time in 28 million write, my 128G memory barely, Redis direct collapse. So, I chose rownumber () over () from where it left off and continue to write.
Support official website:
Using a normal Redis client to perform mass insertion is not a good idea for a few reasons: the naive approach of sending one command after the other is slow because you have to pay for the round trip time for every command. It is possible to use pipelining, but for mass insertion of many records you need to write new commands while you read replies at the same time to make sure you are inserting as fast as possible.
Only a small percentage of clients support non-blocking I/O, and not all the clients are able to parse the replies in an efficient way in order to maximize throughput. For all this reasons the preferred way to mass import data into Redis is to generate a text file containing the Redis protocol, in raw format, in order to call the commands needed to insert the required data.Attachment:
# sqlcmd导出到文本
sqlcmd -S . -U sa -P xxx -d DataImport -h -1 -i d:\openid.sql > d:\tt.txt# 从文本推到redis-cli执行。
type protocol-commands.txt | redis-cli -h 192.168.xx.xx -a xxxx -p 6379 --pipeRedis command to turn into a normal batch script protocol format
Pro-test, text data of nearly 50 million, is moving can not move.
while read CMD; do
# each command begins with *{number arguments in command}\r\nW
XS=($CMD); printf "*${#XS[@]}\r\n"WWW
# for each argument, we append ${length}\r\n{argument}\r\n
for X in $CMD; do printf "\$${#X}\r\n$X\r\n"; done
done < origin-commands.txtAgreements are:
*3
$5
LPUSH
$3
arr
$4
AAAA
*3
$5
LPUSH
$3
arr
$4
BBBB