1. Data Flow
MapReduce jobs (Job) is a client need to perform the work hopefully: including data, configuration information and program MapReduce. Hadoop the job into a plurality of tasks (task) is performed, which includes two types of tasks: map tasks and reduce tasks. These tasks running on the nodes in the cluster, and scheduling through YARN. If a task fails, it will automatically re-scheduled for execution on a different node.
The MapReduce Hapoop input data into small data blocks on stage, called an input tile (input split) or simply "slice." Hadoop construct a map tasks for each slice, the task to run by map function own custom division process so that each record sheet. A reasonable fragment size tends to HDFS a block size, default is 128MB, but can adjust this default value.
Run map task on a node Hadoop and comfortable data (data in HDFS) in the store, you can get the best performance, because it does not require the use of cluster valuable bandwidth resources. This is called "local data optimization." However, sometimes a map for the input slice task, the storage nodes HDFS all copies of data blocks of the slice map may be running other tasks, scheduling of job requires a node from a rack in the data block is located on a map to find an idle slot (slot) to run the map tasks fragment, only in very rare occasions, the chassis only other nodes in the map task to run, this will result between the frame and the frame network transmission.
Why optimum fragment size to be the same as the block size: the size as it is to ensure the maximum input block may be stored on a single node. If the fragment spans two blocks, then for any node HDFS, maybe substantially impossible while storing data blocks, and therefore the slice data to be transmitted to a node portion of map tasks running over the network.
map task writes its output local disk, instead of HDFS. This is because the output of the map is the intermediate result : the intermediate result to produce the final output after processing by the reduce task, but once the job is complete map of the output can be deleted
reduce task does not have the advantage of data locality, usually reduce task input single output from all of the mapper. In this example, we only reduce a task whose input is the output of all the map tasks. Thus, through the discharge sequence to be transmitted to the output node map reduce tasks running across the network. Reduce the combined data terminal, and then processed by a user-defined reduce function. reduce output typically stored in HDFS for reliable storage. A full data stream reduce task as shown below
Reduce the number of tasks is not determined by the size of the input data, the opposite is specified independently.
If there are a good number of reduce tasks, each map task will be for the output to partition (partition), that is, each reduce task to build a partition. Each partition has a plurality of keys (corresponding to extreme values), but each key corresponding to the key - the value recorded in the same partition. Partition controlled by user-defined partition function, but usually by the partitioner to partition by default hash function very efficiently.
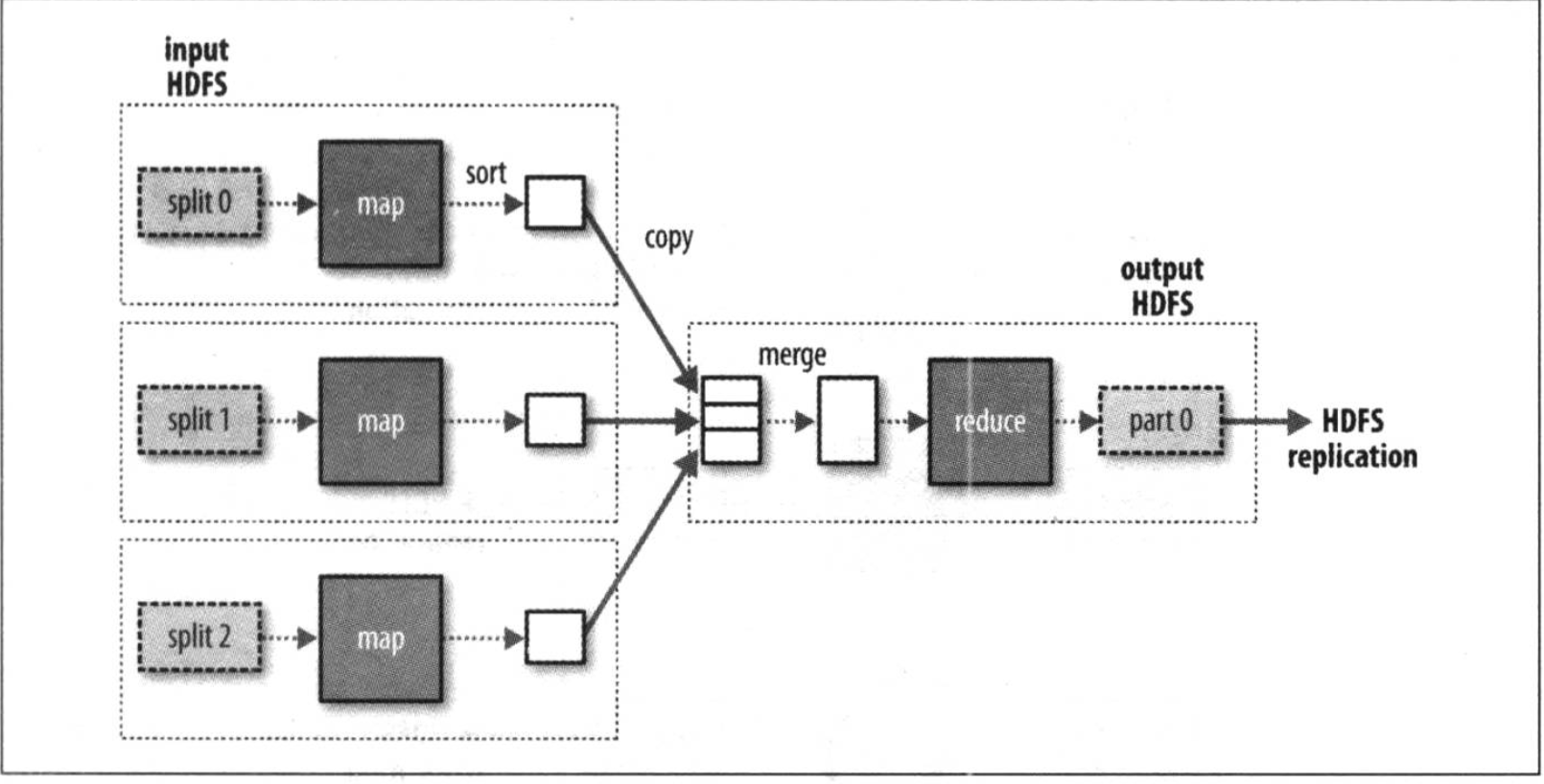
MapReduce reduce a data flow task
In general, a plurality of data streams reduce task as shown below, shows the FIG clear why data between the map tasks and reduce tasks stream called shuffle (shuffled), because the input of each of the reduce task are from many map tasks, shuffle generally more complex than shown in the way, and adjust the parameters affecting the shuffling of job execution time is very large
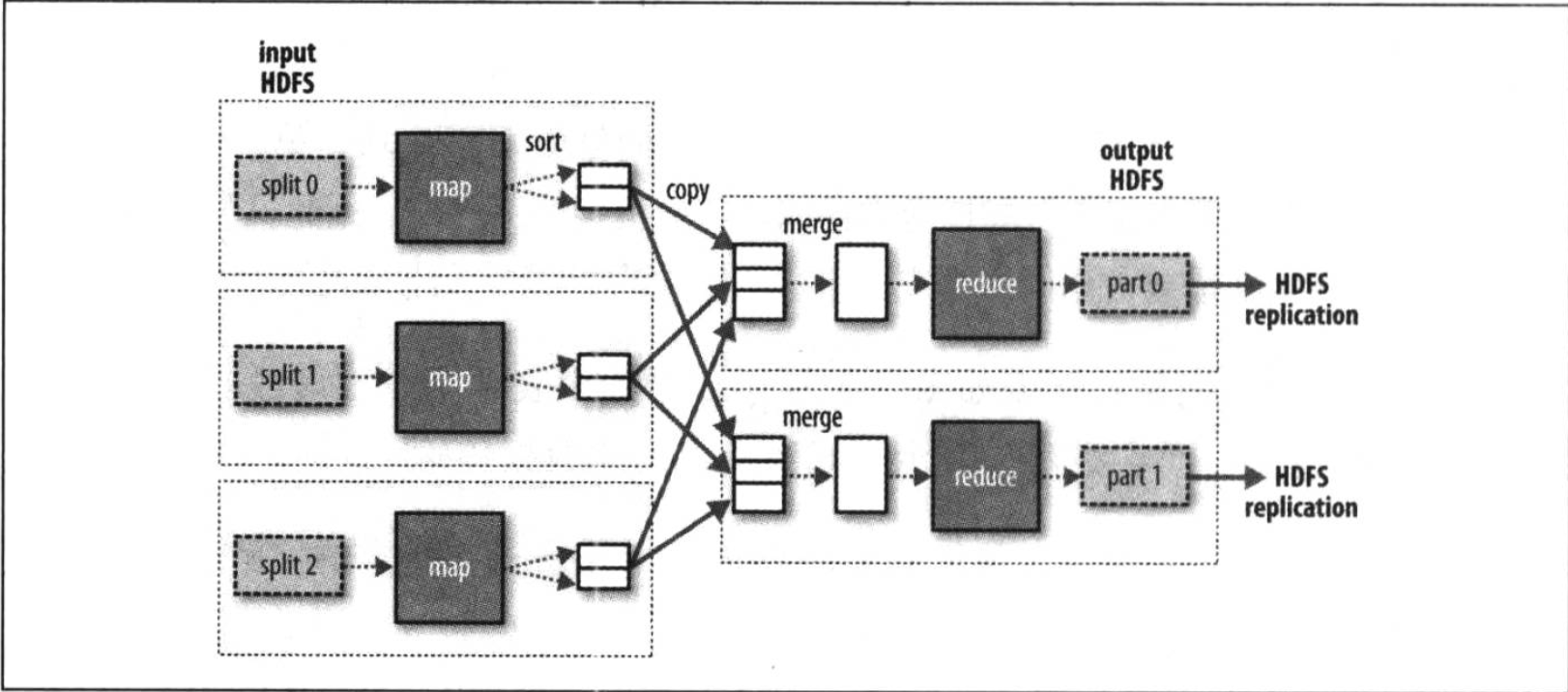
Reduce multiple data flow tasks
When the data processing can be completely parallel (both shuffling without time), there may be no case reduce task, in this case, the only non-local node map is a data transmission task writes the result HDFS.

combiner function
Available bandwidth limits the number of clusters on the MapReduce job, so to avoid data transmission between the map and reduce tasks are advantageous. Hadoop allows users to specify a combiner for the output map tasks (like the mapper and reducer the same), the output of the combiner function as input reduce function hesitation combiner belong optimization program, so Hadoop can not be determined to be recorded to a specified map task output call how many times combiner.
combiner function can not be substituted reduce function. We still need to reduce the recording function to handle different output map with the same key. But the combiner function to help reduce the amount of data transmission between the mapper and reducer.
Hadoop Streaming
Hadoop MapReduce provides the API, you are allowed to use a language other than java to write their own map and reduce functions. Hadoop Streaming is a stream interface between Hadoop and applications using standard Unix, so we can use any programming language via the standard input / output to write MapReduce programs