This article explains the outline, points, eight core concepts to explain the instructions:
- NRT
- Cluster
- Node
- Document&Field
- Index
- Type
- Shard
- Replica
Near Realtime (NRT) near real-time
Elasticsearch core strengths is (Near Real Time NRT) in near real time, which we call near-real time.
NRT has two meanings, for example the following description:
- Writing data to the data from the index can be searched to have a small delay (about 1 second);
For example: Added a new business platform of new products, after one second user can search for information to this product, which is near real-time.
- You can achieve second-level query and analysis to perform a search based on Elasticsearch
Also give an example, for example, I now want to look me in Taobao, the last year have bought a few items, spent a total of how much money, how much money the most expensive commodity, which month to buy most things, what type of goods to buy most such information, if Taobao said, you have to wait 10 minutes to get the results, you are not very crash, this delay time is not near real-time, if Taobao can return the second level to you, that near real-time up.
The following draw a diagram explaining the basic concept of the three

Cluster: Cluster
Includes a plurality of nodes, each node belongs to which cluster is determined by a configuration (cluster name, the default is elasticsearch), for small and medium sized applications, the beginning of a cluster node on a normal. The purpose of the cluster to provide high availability and massive data storage and faster query capabilities across nodes.
Node: Node
A node in the cluster, the node also has a name (the default is randomly assigned), node name is very important (in the implementation of the operation and maintenance management operations), "elasticsearch" cluster default node to join a name, if the direct start a bunch of nodes, then they will automatically form a cluster elasticsearch, of course, a node can form a cluster elasticsearch
Document & field: documents and fields
document is the minimum data unit in es, a document may be a customer data, a commodity classification data, one line data is usually represented by JSON data structure, the type of each index, may be to store a plurality of document. A document which has a plurality of field, each field is a data field.
Mysql equivalent in a row, can be simply understood, for example. A document data of a commodity as follows:
product document
{
"product_id": "1000",
"product_name": "mac pro 2019 款笔记本",
"product_desc": "高性能,高分辨率,编程必备神器",
"category_id": "2",
"category_name": "电子产品"
}
Index: Index
There are a bunch of documents containing similar data structure, such as a customer can have an index, commodity classification index, orders index, the index has a name.
Index contains a lot of document, an index to represent a class of similar or identical document. For example, to create a product index, commodity index, which might store all product data, all of the merchandise document.
Type: Type
Where each index can have one or more type, type is a classification index the logical data, document under a type, have the same Field, such as blog system, an index, a user can define a data type, blog data type, comment data type.
Commodity index, which store all product data, product document
But commodities are divided into categories, each category of document the field may not be the same, such as electrical goods, may also contain some, such as after-sales time such a special field; fresh goods, also contains some, such as fresh shelf life like special field
type, daily commodity type, electrical goods type, commodity type Fresh
日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
Every type which will contain a bunch of document
{
"product_id": "2",
"product_name": "长虹电视机",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "电器",
"service_period": "1年"
}
{
"The product_id": ". 3",
"PRODUCT_NAME": "shrimp",
"product_desc": "natural, Iceland production",
"category_id": ". 4",
"category_name": "Fresh",
"eat_period": "7 days"
}
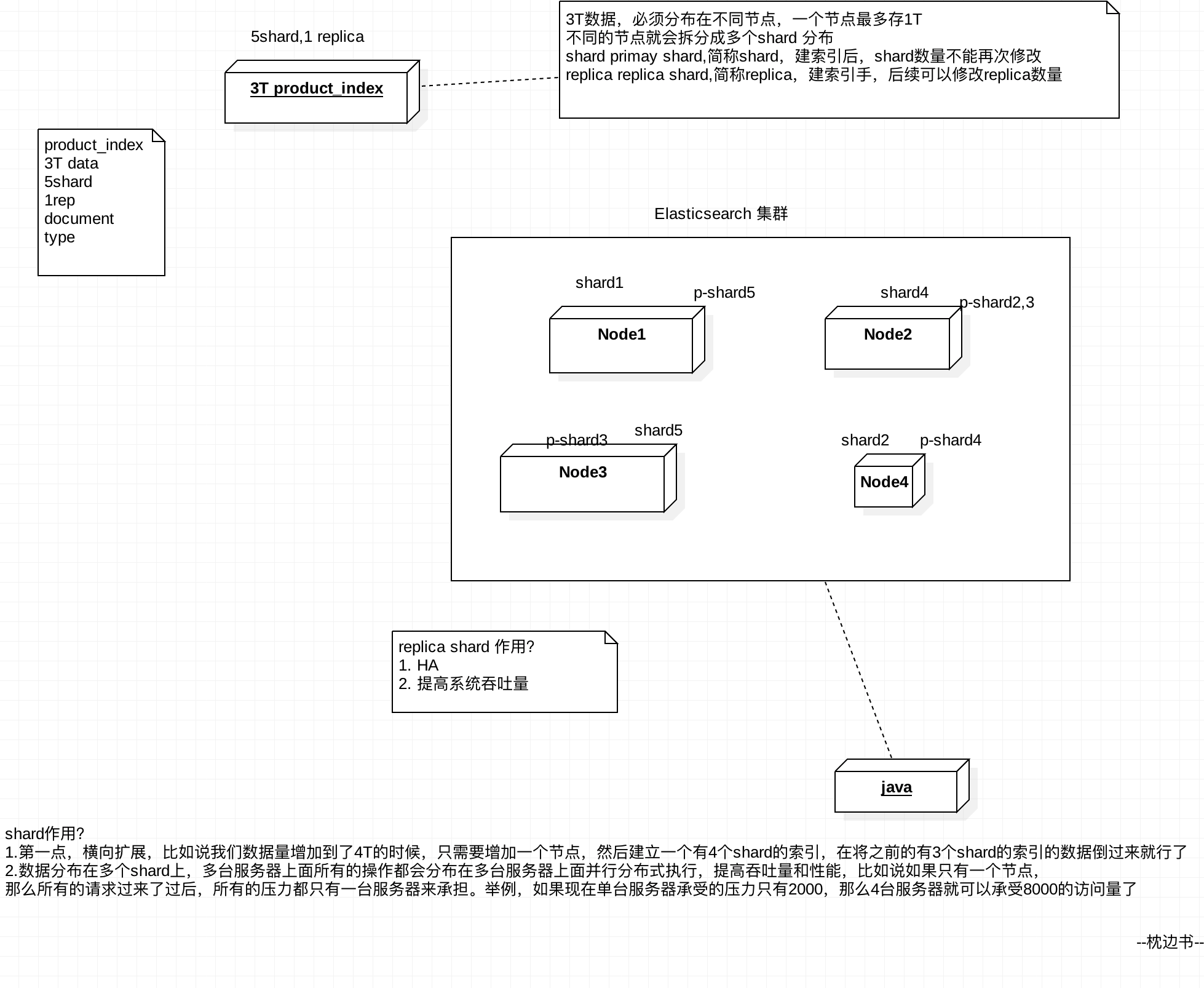
Shard fragmentation, also known as Primary Shard
A single machine can not store large amounts of data, es data can be cut into a plurality of index shard, distributed across multiple storage servers. With shard can scale out to store more data, so that operations such as search and analysis distributed to multiple servers to perform up to enhance the throughput and performance.
Each shard is a lucene index.
Replica copies, also known as Replica Shard
Subject to any server failure or downtime, then shard might be lost, so you can create multiple copies of each replica shard. replica may provide backup service when shard failure, to ensure data is not lost, a plurality of replica may further improve the throughput and performance of the search operation.
primary shard (once set up indexing, you can not modify the default 5),
replica shard (at any time modify the number, the default one),
Each default index 10 shard, 5 th primary shard, 5 th replica shard, the minimum high-availability configuration, the server is two.
Index-related explanation:
- index contains more than shard
- Shard is a minimum capacity of each unit of work, carrying part of the data, Lucene instance, the complete indexing process requests and
- When changes in the node, shard will automatically load balancing nodes in
- primary shard and replica shard, each document must exist only a certain primary shard and its corresponding replica shard in, can not exist in a plurality of primary shard
- replica shard is the primary shard copy, responsible for fault tolerance, load and bear a read request
- The number of primary shard in the creation of the index is fixed, and the number of replica shard can be modified at any time
- The default primary shard number is 5, replica is 1 by default, default 10 has shard, 5 th primary shard, 5 th replica shard
- primary shard and its replica shard can not be placed on the same node (or node goes down, primary shard and replica are lost, would not achieve the role of fault-tolerant), but other primary shard of replica shard on the same node
Index allocation map in the cluster:
This article from the blog article multiple platforms OpenWrite release!