For those of us of MySQL users, usually use the most is the search function. DBA lost over from time to time to let some of the slow query optimization, optimization is not clear yet if even a wool query is how to perform, it is time to grasp the true technology. MySQL has a feature called after the results of the query optimizer module, a query syntax parsing will be handed over to the query optimizer to optimize, optimize is to generate a so-called execution plan, the execution plan shows what indexes should be used query, the order of connection between tables is sawed, and finally calls the method provided by the storage engine steps in the execution plan to actually execute the query, and the query results are returned to the user. However, the query optimizer to this theme a little large, have to learn to run before you learn to walk first, this chapter first to Chou Chou MySQL how to perform a single-table queries (behind the FROM clause is only one table, the simplest kind of query ~).
In order to develop the story, come to have a table: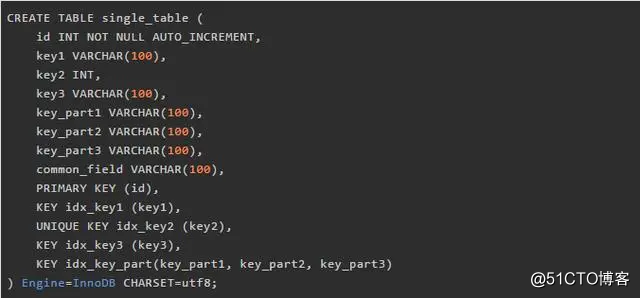
We built a clustered index and four secondary index for the single_table table, namely:
Id columns for the clustered index created.
idx_key1 secondary index established for the key1 column.
Idx_key2 secondary index is established key2 column, and that the index is a unique secondary index.
idx_key3 secondary index established for key3 columns.
idx_key_part secondary index established for key_part1, key_part2, key_part3 column, which is a joint index.
Then we need to insert 10000 rows for the table records, in addition to id columns remaining columns are inserted like a random value, specific insert statement I do not write, write their own program insert it (the column id is auto-increment primary key column we do not need to manually insert).
The concept of access methods (access method) of
Surely you have a high moral map to find a route to somewhere it (here is not as high moral map advertising mean, they did not give me money, you can also use Baidu map ah), if we search Bell Tower to the route between the big Wild Goose Pagoda, then the software will be given a map of n route for us to choose, if we really idle all right dry and rich enough, you can also reach the destination in a circle around the earth with a diametrically opposite way. In other words, no matter which way, our ultimate goal is to reach the Big Wild Goose Pagoda this place. Back to MySQL in the past, we usually those written on the nature of the query is only a declarative syntax, MySQL just told us to get the data in line with what the rules as to how MySQL is secretly engaged in the query results out of it is MySQL own thing. For queries a single table, the uncle of the design MySQL executes queries roughly divided into the following two categories:
Using the full table scan query
This implementation is well understood, is to record each row of the table are again sweeping Well, the records that match the search criteria are added to the result set would be finished. No matter what those queries can be executed in this way, of course, this is the most stupid of implementation.
Use the index query
Because the direct use full table scan to execute a query to traverse a lot of records, so the price may be too high. If the query in the search criteria can be used to a certain index, that directly use the index to execute the query is likely to accelerate query execution time. Use the index to execute the query wide variety of ways, it can be subdivided into many types:
Equivalent query against a primary key or unique secondary index
Equivalent query against ordinary secondary index
For range queries index column
Direct scan the entire index
Design MySQL MySQL uncle way to execute a query is called the access method or access type. The same query may be able to use a variety of different access methods to perform, although the final results are the same, but the execution time may be poor old nose away, like from the bell tower to the Big Wild Goose Pagoda, you can rocket ride You go, you can fly to, of course, can take the turtle to go. Below carefully to the various access methods specific content channels.
const
Sometimes we can locate a record by the primary key column, say this query:
MySQL primary key will be directly positioned corresponding user record clustered index, like this: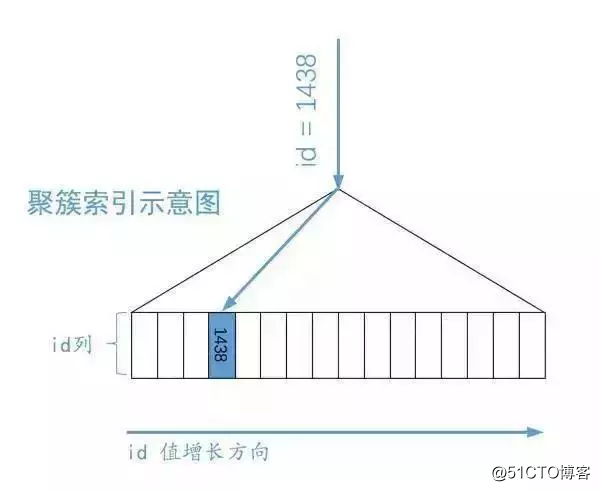
原谅我把聚簇索引对应的复杂的 B+树结构搞了一个极度精简版,为了突出重点,我们忽略掉了 页的结构,直接把所有的叶子节点的记录都放在一起展示,而且记录中只展示我们关心的索引列,对于 single_table表的聚簇索引来说,展示的就是 id列。我们想突出的重点就是: B+树叶子节点中的记录是按照索引列排序的,对于的聚簇索引来说,它对应的 B+树叶子节点中的记录就是按照 id列排序的。 B+树本来就是一个矮矮的大胖子,所以这样根据主键值定位一条记录的速度贼快。类似的,我们根据唯一二级索引列来定位一条记录的速度也是贼快的,比如下边这个查询:
这个查询的执行过程的示意图就是这样: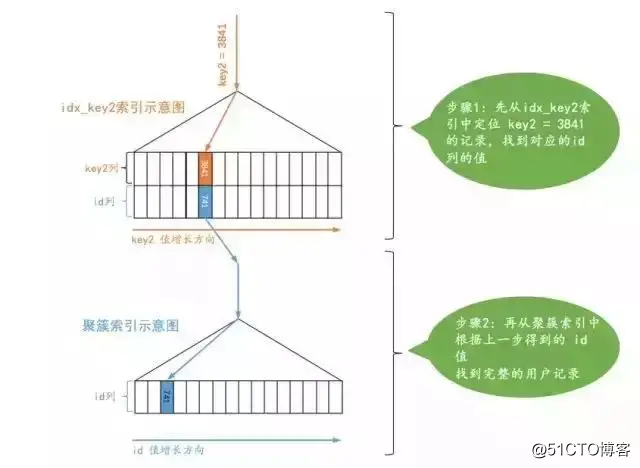
可以看到这个查询的执行分两步,第一步先从 idx_key2对应的 B+树索引中根据 key2列与常数的等值比较条件定位到一条二级索引记录,然后再根据该记录的 id值到聚簇索引中获取到完整的用户记录。
设计 MySQL的大叔认为通过主键或者唯一二级索引列与常数的等值比较来定位一条记录是像坐火箭一样快的,所以他们把这种通过主键或者唯一二级索引列来定位一条记录的访问方法定义为: const,意思是常数级别的,代价是可以忽略不计的。不过这种 const访问方法只能在主键列或者唯一二级索引列和一个常数进行等值比较时才有效,如果主键或者唯一二级索引是由多个列构成的话,索引中的每一个列都需要与常数进行等值比较,这个 const访问方法才有效(这是因为只有该索引中全部列都采用等值比较才可以定位唯一的一条记录)。
对于唯一二级索引来说,查询该列为 NULL值的情况比较特殊,比如这样:
因为唯一二级索引列并不限制 NULL值的数量,所以上述语句可能访问到多条记录,也就是说上边这个语句不可以使用 const访问方法来执行。
ref
有时候我们对某个普通的二级索引列与常数进行等值比较,比如这样:
对于这个查询,我们当然可以选择全表扫描来逐一对比搜索条件是否满足要求,我们也可以先使用二级索引找到对应记录的 id值,然后再回表到聚簇索引中查找完整的用户记录。由于普通二级索引并不限制索引列值的唯一性,所以可能找到多条对应的记录,也就是说使用二级索引来执行查询的代价取决于等值匹配到的二级索引记录条数。如果匹配的记录较少,则回表的代价还是比较低的,所以 MySQL可能选择使用索引而不是全表扫描的方式来执行查询。设计 MySQL的大叔就把这种搜索条件为二级索引列与常数等值比较,采用二级索引来执行查询的访问方法称为: ref。我们看一下采用 ref访问方法执行查询的图示: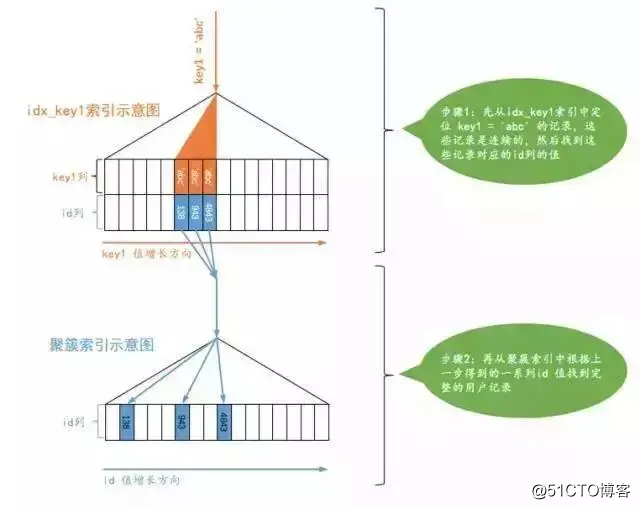
从图示中可以看出,对于普通的二级索引来说,通过索引列进行等值比较后可能匹配到多条连续的记录,而不是像主键或者唯一二级索引那样最多只能匹配1条记录,所以这种 ref访问方法比 const差了那么一丢丢,但是在二级索引等值比较时匹配的记录数较少时的效率还是很高的(如果匹配的二级索引记录太多那么回表的成本就太大了),跟坐高铁差不多。不过需要注意下边两种情况:
1、二级索引列值为 NULL的情况,不论是普通的二级索引,还是唯一二级索引,它们的索引列对包含 NULL值的数量并不限制,所以我们采用 key IS NULL这种形式的搜索条件最多只能使用 ref的访问方法,而不是 const的访问方法。
2、对于某个包含多个索引列的二级索引来说,只要是最左边的连续索引列是与常数的等值比较就可能采用 ref的访问方法,比方说下边这几个查询:
但是如果最左边的连续索引列并不全部是等值比较的话,它的访问方法就不能称为 ref了,比方说这样: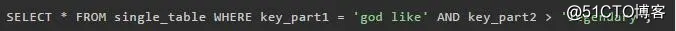
refornull
有时候我们不仅想找出某个二级索引列的值等于某个常数的记录,还想把该列的值为 NULL的记录也找出来,就像下边这个查询:
当使用二级索引而不是全表扫描的方式执行该查询时,这种类型的查询使用的访问方法就称为 ref_or_null,这个 ref_or_null访问方法的执行过程如下: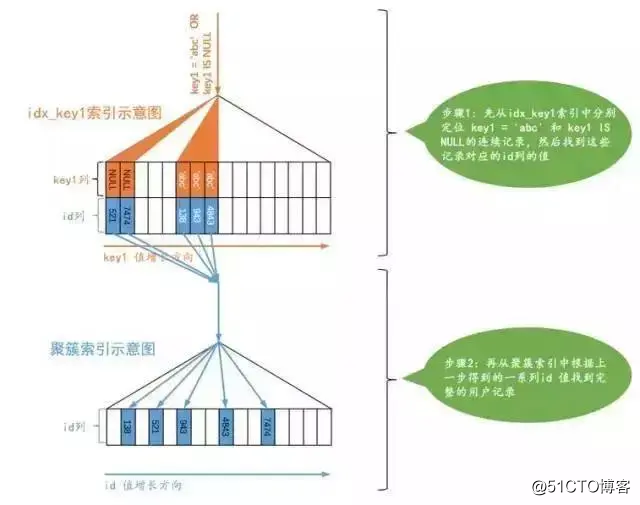
可以看到,上边的查询相当于先分别从 idx_key1索引对应的 B+树中找出 key1 IS NULL和 key1='abc'的两个连续的记录范围,然后根据这些二级索引记录中的 id值再回表查找完整的用户记录。
range
我们之前介绍的几种访问方法都是在对索引列与某一个常数进行等值比较的时候才可能使用到( ref_or_null比较奇特,还计算了值为 NULL的情况),但是有时候我们面对的搜索条件更复杂,比如下边这个查询:
我们当然还可以使用全表扫描的方式来执行这个查询,不过也可以使用 二级索引+回表的方式执行,如果采用 二级索引+回表的方式来执行的话,那么此时的搜索条件就不只是要求索引列与常数的等值匹配了,而是索引列需要匹配某个或某些范围的值,在本查询中 key2列的值只要匹配下列3个范围中的任何一个就算是匹配成功了:
key2的值是 1438
key2的值是 6328
key2的值在 38和 79之间。
设计 MySQL的大叔把这种利用索引进行范围匹配的访问方法称之为: range。
小贴士:
此处所说的使用索引进行范围匹配中的 索引 可以是聚簇索引,也可以是二级索引。
如果把这几个所谓的 key2列的值需要满足的 范围在数轴上体现出来的话,那应该是这个样子:
也就是从数学的角度看,每一个所谓的范围都是数轴上的一个 区间,3个范围也就对应着3个区间:
范围1: key2=1438
范围2: key2=6328
范围3: key2∈[38,39],注意这里是闭区间。
我们可以把那种索引列等值匹配的情况称之为 单点区间,上边所说的 范围1和 范围2都可以被称为单点区间,像 范围3这种的我们可以称为连续范围区间。
index
看下边这个查询:
Since key_part2 not a joint index idx_key_part leftmost column index, so we can not execute this statement using the ref or range access method. But the queries that meet the following two conditions:
It queries the list only three columns: key_part1, key_part2, key_part3, and the index idx_key_part turn contains three columns.
Only search criteria key_part2 column. This column is also included in the index idx_key_part in.
That we can directly compare key_part2 = 'abc' by recording a leaf node traversal idx_key_part index of this condition is satisfied, the secondary index records to match the success of key_part1, key_part2, value added key_part3 columns in the result set directly on the line a. Since the two recorded index smaller than clustered indexes recorded poly (clustered index records to store all user-defined column and so-called hidden column, the index records only two columns, and a primary key index is stored), and this process is also not table-back operation, so a direct traverse secondary index is smaller than the cost of a direct traverse many clustered indexes, MySQL uncle put this design uses two traversing the index records implementation called: indexall
all
The most direct way is to query execution we have already mentioned countless times full table scan, for InnoDB tables, it is scanned directly clustered index, MySQL uncle put this design use a full table scan to execute the query call: all
More about how MySQL is running, you can look at "High Performance MySQL electronic version of the" content is very substantial, from the white point of view, to explain some of the core concepts of MySQL advanced with a relatively simple language, such as server performance benchmark data type optimize query performance optimization copy many knowledge availability, etc., a total of hundreds of thousands of words about words, with hundreds of pieces of original illustrations. I mainly want to reduce the average programmer learning curve MySQL advanced to master these seemingly more obscure knowledge in a shorter period of time, so the learning curve is more smooth point.