1. hdfs stored file when the file will cut block, block distributed on different nodes, there is provided replicate = 3, each block will appear in three nodes.
2. Spark to run for the RDD center concept, RDD representative of abstract data sets. With code as an example:
sc.textFile(“abc.log”)
textFile () function creates a RDD object, you can think that this object represents the RDD "abc.log" file data, the object to complete the operation by the operation RDD to file data.
3. RDD partition comprising one or more partitions, each partition corresponding to a portion of the file data. In the spark reading hdfs scene, spark hdfs of the memory block will read the abstract for the partition spark. Therefore, RDD the corresponding file, the file corresponding to the block partition, partition number equal to the number of the block, the purpose of doing so is to parallel operation data file.
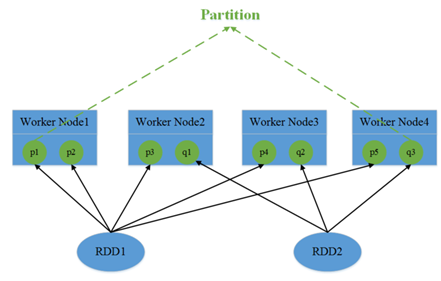
Since the block is distributed in different nodes, the operation of the partition is also scattered in different nodes.
4. RDD is read-only immutable data set, so each will have a new operation RDD RDD objects. Similarly, partition is read-only.
sc.textFile("abc.log").map()
Code textFile () builds a NewHadoopRDD, map () function after the operation will construct a MapPartitionsRDD.
Here the map () function is already operating a distributed, since partition in NewHadoopRDD distributed over different nodes, map () function will do a partition map for each operation, a new partition, will generate a new RDD (MapPartitionsRDD). Each partition map for performing the operation is a task, there will be three task, task and partition the correspondence in FIG.

The final task of each partition will then correspond. But before allocation of task execution order to be considered. Appeared concept job, stage, and narrow width dependency dependent.
Wide and narrow dependence is dependence to arrange the order of execution of the task. Simple to understand, refers to an operation can be dependent on a narrow pipeline forms, such as map, filter ,, does not depend on all the data partition can be computed in parallel at different nodes. map and filter need only one partition of data.
Width dependence, such GroupByKey, the data need to be calculated for all the partitions, while the cause of data transmission between nodes.
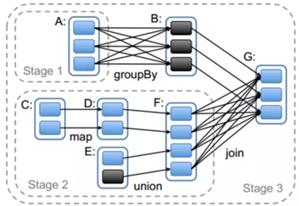
Spark stage will be divided based on a narrow width dependence and dependence, stage sequentially executes sequence 1,2,3.
FIG stage2 union in the map and are dependent narrow.
The width is dependent stage3 join. Join operations will all partition data aggregated together to produce a new partition, which might be the middle of a large amount of data transfer takes place. At the same time new production of RDD will write back hdfs, re-read the next time you use, the new division of partition.
Stage composed of a plurality of job, job data by the calculation section performs the real trigger generator, such as reduce, collect and other operations, the program may have a plurality of job. RDD all operations are Lazy mode, operation not calculate the final result in the compilation immediately, but remember all the procedures and methods, only the displayed encountered startup command was executed.
Overall: a plurality of program job, a job with a plurality of stage, a stage with a plurality of task, each task is assigned to execute the executor.
6. When assigned task, priority has been to find a node where the data in memory; if not, the node where the data on disk to find; no, the nearest node allocation.
7. executor
The configuration of each node may serve one or more executor; each executor by a number of core, each core of each executor can only perform one task.
Executed task parallelism = max (number per number of nuclei executor * the executor, partition number).
Accomplish communication using RPC (formerly akka, using the latest Netty) 8. between nodes.
Finally, it seems, may have an impact on performance is wide-dependent operations, data like reduceByKey, sort, sum operation requires all partition, you need to transfer data to a node, time-consuming.