Scrapy is a website for crawling data, extract structured data written application framework. Which can be used in data mining process or a series of program information stored in the historical data. It was originally intended to crawl the page (more precisely, the web crawler) designed, it can also be used in obtaining the data returned by the API (such as Amazon Associates Web Services) or general-purpose web crawler. Scrapy wide range of uses, can be used for data mining, monitoring and automated testing.
Scrapy use the library as a framework for asynchronous network Twisted, Twisted some special place that it is event driven, and more suitable for asynchronous code. For operation will block the thread contains access files, databases or Web, create new processes and outputs (such as running shell commands) to deal with the new process, code execution system level operations (such as waiting for the system queue), Twisted provides allow execution the above method of operation but does not block code execution.
The overall structure is as follows:
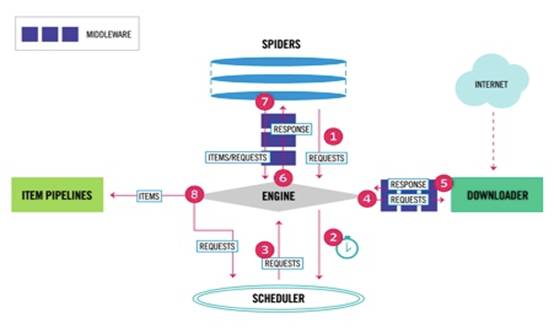
Scrapy includes the following components:
- Engine (Scrapy)
for processing the data flow of the entire system , triggering transaction ( Framework Core ) - The scheduler (Scheduler)
for receiving engine sent me the request , pressed into the queue , and return again when the engine request . Can be thought of as a the URL of (or crawl URL of the page is a link) priority queue , by its What is the next to decide to crawl a website is , at the same time remove the duplicate URLs - Downloader (Downloader)
for downloading web content , and page content back to the spider (Scrapy Downloader is based on twisted this effective asynchronous model ) - Reptile (Spiders)
crawler is the main work , used to extract the information they need from a particular Web page , the so-called entity (Item) . Users can also extract the link , let Scrapy continue to crawl to the next page - Project pipeline (Pipeline)
is responsible for handling reptiles drawn from the Web entity, the main function is persistent entity, to verify the effectiveness of the entity, remove unnecessary information. When a page is parsed crawler, the pipe will be sent to the project, and after a few specific order of processing data. - Download middleware (Downloader Middlewares)
located Scrapy frame between the engine and the downloader deal primarily Scrapy requests and responses between the engine and downloader. - Reptiles middleware (Spider Middlewares)
interposed Scrapy frame between the engine and the crawler, the main task is processed in response to the input and output requests spider. - Scheduling middleware (Scheduler Middewares)
interposed Scrapy intermediate between the engine and the scheduling, the Scrapy transmission and the engine in response to the scheduling request.
Scrapy data flow is controlled by a core engine (Engine) performed, the flow is such that:
1, to obtain an initial request ENGINE engine crawlers crawl begins.
2, reptiles ENGINE engine start request scheduler SCHEDULER, and prepare for the next request crawl.
3, the crawler scheduler returns a request to the next engine crawler.
4, a request is sent to the engine DOWNLOADER downloader, downloading via the download network middleware.
5, once the download is complete the download page to download the results back to the crawler engine ENGINE.
6, the response ENGINE engine crawlers DOWNLOADER downloader by the middleware processing returns to the crawler MIDDLEWARES SPIDERS.
7, reptiles SPIDERS response processing, and returns the processed items through the middleware MIDDLEWARES, and a new request to the engine.
8, items after the engine to the transmission processing pipeline projects, and then returns the processing result to the scheduler SCHEDULER, the scheduler program processes a request to fetch.
9, the process is repeated (step 1 continues), until all of the crawling End fetch request url
scrapy project structure:
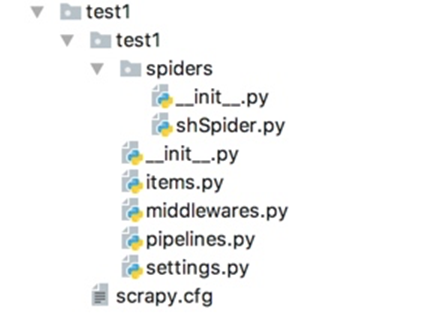
- Configuration information scrapy.cfg projects, mainly to provide a basic configuration information Scrapy command-line tool. (Real reptile-related configuration information in settings.py file)
- items.py setting data storage modules for structured data, such as: Django a Model
- pipelines.py data processing activity, such as: general structure of data persistence
- settings.py configuration files, such as: the number of layers of recursion, the number of concurrent delay downloading
- spiders reptiles directory, such as: create a file, write reptiles rules
- Some middleware middlewares defined during crawling, he can be used to process operation request, response, exception and the like
Steps for usage:
- Create a project in the project directory
- Creating crawler
- Writing reptile spider.py
- Setting data stored template items.py
- Set up a profile settings.py
- Write data processing scripts pipelines.py
- Implementation of reptiles