In addition to the programming make the program work in all possible cases correctly, but also need to consider the efficiency of the program, it focuses on an optimized with regard to reading and writing, optimizing the operation of this section will be analyzed. Read and write optimization
Writing efficient program needs to do two things:
- Selecting a set of appropriate algorithms and data structures
- Write optimizing compiler to be converted into an effective and efficient source of executable code
The first point suitable algorithms and data structures often when you write the program will first take into account, and the second point is often overlooked. Here we are in terms of code optimization, we focus on how to write can be effectively optimizing compiler source code, where the optimizing compiler to understand the capabilities and limitations is very important.
In addition to the difference between reading and writing operations, with the one of the biggest difference in this section are: optimization of this example will affect readability.
But it is also the case method of programming often encountered in the absence of better optimization means, but there is an urgent program of performance requirements, taking space for time, or in exchange for lowering the operating efficiency of the code readability is not desirable .
When you write a small tool to deal with a temporary affairs (and perhaps the future is not reused), or want to verify when one of your idea is feasible (such as testing an algorithm is correct), if written a good readability but run very slow process, often waste a lot of unnecessary time. At this time you may not need to care so much about the readability of the code, but to pay more attention to the results of operational performance of the current program to obtain the desired earlier.
Below we will illustrate the matrix operation of common code optimization.
Objective function: Image Smoothing
Smoothing operation requires:
- Value of each pixel of the modified image matrix,
new = value as the center point on the pixel adjacent to the average value of nine pixels - Four corner points of the image matrix, only requires the average of the four corner pixels
- The four sides of the image matrix, requires only six pixels adjacent to the current point average
Schematic:
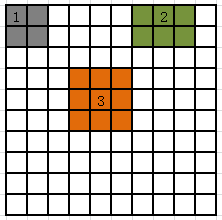
At represent 1,2,3 corner, adjacent pixels of the edge points and inner points
We represent a pixel image with the following structure:
typedef struct {
unsigned short red; /* R value */
unsigned short green; /* G value */
unsigned short blue; /* B value */
} pixel;red, green, blue respectively represent a red, green and blue channels of a color image.
Original smoothing function as follows:
static void accumulate_sum(pixel_sum *sum, pixel p)
{
sum->red += (int) p.red;
sum->green += (int) p.green;
sum->blue += (int) p.blue;
sum->num++;
return;
}
static void assign_sum_to_pixel(pixel *current_pixel, pixel_sum sum)
{
current_pixel->red = (unsigned short) (sum.red/sum.num);
current_pixel->green = (unsigned short) (sum.green/sum.num);
current_pixel->blue = (unsigned short) (sum.blue/sum.num);
return;
}
static pixel avg(int dim, int i, int j, pixel *src)
{
int ii, jj;
pixel_sum sum;
pixel current_pixel;
initialize_pixel_sum(&sum);
for(ii = max(i-1, 0); ii <= min(i+1, dim-1); ii++)
for(jj = max(j-1, 0); jj <= min(j+1, dim-1); jj++)
accumulate_sum(&sum, src[RIDX(ii, jj, dim)]);
assign_sum_to_pixel(¤t_pixel, sum);
return current_pixel;
}
void naive_smooth(int dim, pixel *src, pixel *dst)
{
int i, j;
for (i = 0; i < dim; i++)
for (j = 0; j < dim; j++)
dst[RIDX(i, j, dim)] = avg(dim, i, j, src);
}Is a standard square image, represented by one-dimensional array, the (i, j) th pixel is represented as I [RIDX (i, j, n)], n is the length of the image side.
parameter:
- dim: side length of the image
- src: the first point to the original image array address
- dst: first address to the target image array
Optimization Objective: To enable smooth operation processing faster
We currently have a driver.c file, the original function can be tested and optimized functions we obtain it indicates that the program is running performance of CPE (number of elements per cycle) parameters.
Our task is to achieve optimized code with the original code is run to compare the parameters, look at the code to optimize the situation.
The main method of optimization
- Loop unrolling
- Parallel Computing
- Calculated in advance
- Calculation block
- Avoid complex operation
- Reduce function calls
- Cache hit rate increase
Loop body there is only one statement, the statement is mainly mean a lot of computation, and multiple layers of function calls, the call stack multiple functions there such operation.
By analysis, optimization methods in this section than in the previous section to read and write more direct matrix. The current program of major performance bottleneck lies in two aspects:
- Multilayer function call: function stack adds unnecessary processing overhead
- A large number of repetitive operations: performing different pixel mean calculation, many operations are repeated and unnecessary
Optimization of this section is to be improved for these two points,
The multilayer easier to solve function call, the called function need only function to achieve smooth transfer of the line (the source code to reduce the degree of coupling, but led to a decline in performance).
The following analyzes the problems of repetitive operations, as shown in:
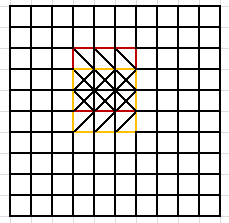
calculating the average of red and yellow region when the region average, there are two rows of repetitive operations. Corresponding optimization strategy is 1 * 3 submatrix is set and calculated so that each time only 3 to calculate the mean and divided by the sum of the known 9, a certain amount of computation is reduced.
Corresponding optimized code is as follows:
int rsum[4096][4096];
int gsum[4096][4096];
int bsum[4096][4096];
void smooth(int dim, pixel *src, pixel *dst)
{
int dim2 = dim * dim;
for(int i = 0; i < dim; i++){
for(int j = 0; j < dim-2; j++){
int z = i*dim;
rsum[i][j] = 0, gsum[i][j] = 0, bsum[i][j] = 0;
for(int k = j; k < j + 3; k++){
rsum[i][j] += src[z+k].red;
gsum[i][j] += src[z+k].green;
bsum[i][j] += src[z+k].blue;
}
}
}
// 四个角
dst[0].red = (src[0].red + src[1].red + src[dim].red + src[dim+1].red) / 4;
dst[0].green = (src[0].green + src[1].green + src[dim].green + src[dim+1].green) / 4;
dst[0].blue = (src[0].blue + src[1].blue + src[dim].blue + src[dim+1].blue) / 4;
dst[dim-1].red = (src[dim-2].red + src[dim-1].red + src[dim+dim-2].red + src[dim+dim-1].red) / 4;
dst[dim-1].green = (src[dim-2].green + src[dim-1].green + src[dim+dim-2].green + src[dim+dim-1].green) / 4;
dst[dim-1].blue = (src[dim-2].blue + src[dim-1].blue + src[dim+dim-2].blue + src[dim+dim-1].blue) / 4;
dst[dim2-dim].red = (src[dim2-dim-dim].red + src[dim2-dim-dim+1].red + src[dim2-dim].red + src[dim2-dim+1].red) / 4;
dst[dim2-dim].green = (src[dim2-dim-dim].green + src[dim2-dim-dim+1].green + src[dim2-dim].green + src[dim2-dim+1].green) / 4;
dst[dim2-dim].blue = (src[dim2-dim-dim].blue + src[dim2-dim-dim+1].blue + src[dim2-dim].blue + src[dim2-dim+1].blue) / 4;
dst[dim2-1].red = (src[dim2-dim-2].red + src[dim2-dim-1].red + src[dim2-2].red + src[dim2-1].red) / 4;
dst[dim2-1].green = (src[dim2-dim-2].green + src[dim2-dim-1].green + src[dim2-2].green + src[dim2-1].green) / 4;
dst[dim2-1].blue = (src[dim2-dim-2].blue + src[dim2-dim-1].blue + src[dim2-2].blue + src[dim2-1].blue) / 4;
// 四条边
for(int j = 1; j < dim-1; j++){
dst[j].red = (rsum[0][j-1]+rsum[1][j-1]) / 6;
dst[j].green = (gsum[0][j-1]+gsum[1][j-1]) / 6;
dst[j].blue = (bsum[0][j-1]+bsum[1][j-1]) / 6;
}
for(int i = 1; i < dim-1; i++){
int a = (i-1)*dim, b = (i-1)*dim+1, c = i*dim, d = i*dim+1, e = (i+1)*dim, f = (i+1)*dim+1;
dst[c].red = (src[a].red + src[b].red + src[c].red + src[d].red + src[e].red + src[f].red) / 6;
dst[c].green = (src[a].green + src[b].green + src[c].green + src[d].green + src[e].green + src[f].green) / 6;
dst[c].blue = (src[a].blue + src[b].blue + src[c].blue + src[d].blue + src[e].blue + src[f].blue) / 6;
}
for(int i = 1; i < dim-1; i++){
int a = i*dim-2, b = i*dim-1, c = (i+1)*dim-2, d = (i+1)*dim-1, e = (i+2)*dim-2, f = (i+2)*dim-1;
dst[d].red = (src[a].red + src[b].red + src[c].red + src[d].red + src[e].red + src[f].red) / 6;
dst[d].green = (src[a].green + src[b].green + src[c].green + src[d].green + src[e].green + src[f].green) / 6;
dst[d].blue = (src[a].blue + src[b].blue + src[c].blue + src[d].blue + src[e].blue + src[f].blue) / 6;
}
for(int j = 1; j < dim-1; j++){
dst[dim2-dim+j].red = (rsum[dim-1][j-1]+rsum[dim-2][j-1]) / 6;
dst[dim2-dim+j].green = (gsum[dim-1][j-1]+gsum[dim-2][j-1]) / 6;
dst[dim2-dim+j].blue = (bsum[dim-1][j-1]+bsum[dim-2][j-1]) / 6;
}
// 中间部分
for(int i = 1; i < dim-1; i++){
int k = i*dim;
for(int j = 1; j < dim-1; j++){
dst[k+j].red = (rsum[i-1][j-1]+rsum[i][j-1]+rsum[i+1][j-1]) / 9;
dst[k+j].green = (gsum[i-1][j-1]+gsum[i][j-1]+gsum[i+1][j-1]) / 9;
dst[k+j].blue = (bsum[i-1][j-1]+bsum[i][j-1]+bsum[i+1][j-1]) / 9;
}
}
}Operating efficiency as follows:
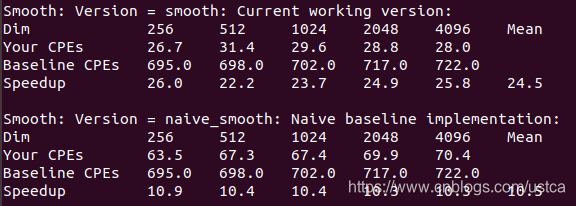
- Dim: Image Size
- Your CPEs: the corresponding function CPE
- Baseline CPEs: reference baseline CPE
- Speedup:加速比 = Baseline CPEs / Your CPEs
After the original function speedup of 10.5, optimize speedup raised to 24.5, although the loss of readability of some code to some extent, but to enhance the operating efficiency we want.
Optimized to reduce to some extent duplicate operations, but does not completely eliminate duplicate operations, if there is a better optimization methods please share.
Please indicate the source: https://www.cnblogs.com/ustca/p/11796896.html