First, install
1.1, kubernetes hardware support issues Description
Kubernetes mainly to a small extent supported CPU and memory discoveries. Kubelet processing device itself is very small.
Kubernetes for hardware use hardware vendors rely on independent research and development kubernetes plug-in, plug-ins by hardware vendors so that kubernetes hardware support.
Logic implemented as follows: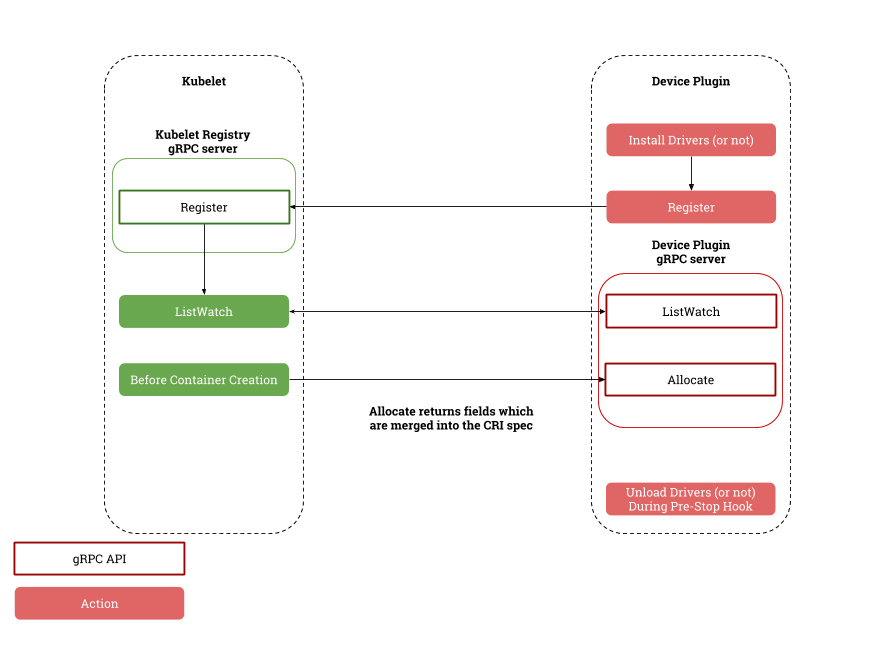
1.2 for the NVIDIA device plug Kubernetes Description
Kubernetes the NVIDIA device plug-in is a Daemonset, allows you to automatically:
The number of public GPU on each node of the cluster
tracking the health of the GPU
to run GPU-enabled vessel in Kubernetes cluster.
The repository contains NVIDIA's Kubernetes device plug- official implementation.
1.3, the NVIDIA device plug Kubernetes conditions ( Official )
Prerequisites run Kubernetes NVIDIA apparatus widget list as follows:
- ~ = 361.93 NVIDIA driver
- nvidia-docker version> 2.0 (see How to Install and prerequisites)
- docker nvidia configured as the default operation.
- Kubernetes version> = 1.11
Run nvidia-docker 2.0 prerequisite list as follows:
- Kernel version> 3.10 GNU / Linux x86_64
- Docker> = 1.12
- Uses architecture NVIDIA GPU> Fermi (2.1)
- NVIDIA Drivers ~ = 361.93 (older versions of untested)
1.4, delete nvidia-docker 1.0
Before you proceed, you must completely remove the version 1.0 software package nvidia-docker.
You must stop and remove all start using nvidia-docker 1.0 container.
1.4.1, Ubuntu release delete nvidia-docker 1.0
docker volume ls -q -f driver = nvidia-docker | xargs -r -I {} -n1 docker ps -q -a -f volume = {} | xargs -r docker rm -f
sudo apt-get purge nvidia-docker
1.4.2, CentOS release delete nvidia-docker 1.0
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo yum remove nvidia-docker
1.5, installation nvidia-docker 2.0
Make sure you have installed the NVIDIA drivers and Docker supported version for your distribution (see Prerequisites).
If you have custom /etc/docker/daemon.json , the nvidia-docker2 packages may cover it, to do a good backup .
1.5.1, Ubuntu release to install nvidia-docker 2.0
Install nvidia-docker2 package and reload the Docker daemon configuration:
sudo apt-get install nvidia-docker2 sudo pkill -SIGHUP dockerd
1.5.2, CentOS distributions install nvidia-docker 2.0
Install nvidia-docker2 package and reload the Docker daemon configuration:
sudo yum install nvidia-docker2 sudo pkill -SIGHUP dockerd
1.5.3, older versions of Docker install nvidia-docker 2.0 ( not recommended )
If you have to use the old version of the docker to install nvidia-docker 2.0
must be fixed nvidia-docker2 version and install nvidia-container-runtime, such as:
sudo apt-get install -y nvidia-docker2=2.0.1+docker1.12.6-1 nvidia-container-runtime=1.1.0+docker1.12.6-1
use
apt-cache madison nvidia-docker2 nvidia-container-runtime
or
yum search --showduplicates nvidia-docker2 nvidia-container-runtime
Lists the available versions.
The basic usage of
a new container running nvidia-docker registered with the Docker daemon. You must select docker run nvidia runtime use:
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
nvidia-docker 2.0 installation and usage detailed in "Fast Learning in Ubuntu Docker 1 hour"
Second, the configuration
2.1, configuration docker
You need to be enabled as the default on the node running nvidia runtime. Edit the docker daemon configuration file, which usually appears in /etc/docker/daemon.json , configured as follows:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
If runtimes does not exist, reinstall nvidia-docker, or reference nvidia-docker official page
2.2, Kubernetes enabled GPU support
When you enable this option on all GPU nodes you want to use, you can deploy the following Daemonset focus enabled GPU support group:
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.11/nvidia-device-plugin.yml
2.3, running GPU jobs
You may be used Dev nvidia.com/gpu configured to use the container by NVIDIA GPU level resource requirements:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: cuda-container
image: nvidia/cuda:9.0-devel
resources:
limits:
nvidia.com/gpu: 2 #请求2个GPU
- name: digits-container
image: nvidia/digits:6.0
resources:
limits:
nvidia.com/gpu: 2 #请求2个GPU
Warning: If the use of the device with a plug NVIDIA image, the number of requests is not configured GPU, the GPU on the host are all exposed in the vessel.
2.4, Kubernetes GPU to container
2.4.1, using notices
- Nvidia's GPU device plug-in function is Kubernetes v1.11 beta
- NVIDIA device plug-in is still considered beta and missing
- GPU more comprehensive health check function
- GPU cleanup function
- ...
- Only official NVIDIA device plug-in to provide support.
2.4.2, kubernetes GPU to the container in dependence Docker
1, get a mirror
1, the image extracted from the pre-built in Docker Hub:
docker pull nvidia/k8s-device-plugin:1.11
Method 2, without using the mirror, using the official method build:
docker build -t nvidia/k8s-device-plugin:1.11 https://github.com/NVIDIA/k8s-device-plugin.git#v1.11
Method 3, using a custom build files Method:
git clone https://github.com/NVIDIA/k8s-device-plugin.git && cd k8s-device-plugin docker build -t nvidia/k8s-device-plugin:1.11 .
2, run locally
docker run --security-opt=no-new-privileges --cap-drop=ALL --network=none -it -v /var/lib/kubelet/device-plugins:/var/lib/kubelet/device-plugins nvidia/k8s-device-plugin:1.11
3, kubernetes deployed as a set of daemons:
kubectl create -f nvidia-device-plugin.yml
2.4.3, kubernetes operation does not depend on the GPU container Docker
1, building
C_INCLUDE_PATH=/usr/local/cuda/include LIBRARY_PATH=/usr/local/cuda/lib64 go build
2, run locally
./k8s-device-plugin