Database Query I believe many people are not familiar with, people often laugh at all the programmer is CRUD Commissioner, this so-called CRUD refers to additions and deletions to change search database.
In additions and deletions to change search the database operation, is the most frequently used queries. In all query operations, the number of statistical operations is often used.
About database statistics the number of rows, either MySQL or Oracle, has a function that can be used, that is COUNT.
But is this common COUNT function, but hidden a lot of mystery, especially during the interview, believe it will be abused. Do not believe it, try to answer the following questions below:
1 , there are several uses COUNT? 2 , COUNT (field names) and COUNT ( * ) query results any different? 3 , COUNT ( 1 () and COUNT * What is the difference between)? 4 , COUNT ( 1 () and COUNT * efficiency between) which is higher? 5 , why "Ali Baba Java Development Manual" recommends using COUNT ( * ) 6 , MySQL's MyISAM engine for the COUNT ( * ) optimized to do what? 7 , MySQL's InnoDB engine for COUNT ( * ) optimized to do what? 8 , MySQL on the above-mentioned COUNT ( * ) is optimized to do, what is a key premise is that? 9 , the SELECT COUNT ( * ) when, plus without conditions where there is difference? 10 , COUNT ( * ), COUNT ( 1 ) and COUNT (field names) in the execution process like?
More than 10 questions, if you can answer all accurate, then it means you really understand the COUNT function, and if there is what knowledge do not understand, then this article can help you just answering questions.
COUNT know
about COUNT function, are detailed in the MySQL official website:
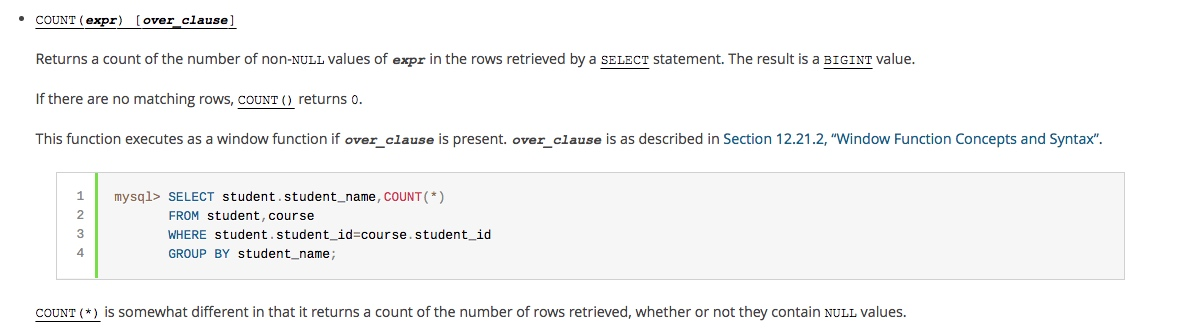
Simple translation this:
1, COUNT (expr), SELECT statement to retrieve the value returned expr row is not the number of NULL. The result is a BIGINT value.
2, if the query results did not hit any records, returns 0
3, however, it is worth noting that statistics COUNT (*), the number of rows that contain a NULL value.
That the following table records
create table #bla(id int,id2 int) insert #bla values(null,null) insert #bla values(1,null) insert #bla values(null,1) insert #bla values(1,null) insert #bla values(null,1) insert #bla values(1,null) insert #bla values(null,null)
Use statement count (*), count (id), count (id2) query results are as follows:
select count(*),count(id),count(id2) from #bla results 7 3 2
In addition to COUNT (id) and COUNT (*), you can also use COUNT (constant) (such as COUNT (1)) to count the number of rows, then the three SQL statements What difference does it make? Which in the end more efficient? Why "Ali Baba Java Development Manual" mandated not to use the COUNT (column name) or COUNT (constant) to replace the COUNT (*) do?

The difference between (*) COUNT (column name), COUNT (constant) and COUNT
As mentioned earlier COUNT (expr) the number of lines used to make statistics, statistics is the number of rows in expr is not NULL, then the COUNT (column name), COUNT (constant) and COUNT (*) three syntax, expr are the column names, constants, and *.
Then the column names, constants, and * these three conditions, the constant is a fixed value, certainly not NULL. * Query can be understood as the entire line, it is certainly not NULL, then only query result column names are likely to be a NULL.
So, COUNT (constant) and COUNT (*) indicates the number of rows in the query directly qualified database table. The COUNT (column name) represents the query qualifies for the value of the column is not NULL of the number of rows.
In addition to the query result set differently than, COUNT (*) compared to COUNT (constant) and COUNT (column name) is concerned, COUNT (*) is the syntax of the number of rows SQL92 standard statistical definition, because he is the standard syntax, so MySQL database against him a lot of optimization.
SQL92, the database is an ANSI / the ISO standard. It defines a language (SQL) databases and behavior (transaction isolation level, etc.).
COUNT (*) optimization
Mentioned earlier COUNT (*) is the syntax of the number of rows SQL92 standard statistical definition, so MySQL database against him a lot of optimization. So, what are the specific things done it?
Presented here to distinguish between different execution engines. MySQL more commonly used execution engine is InnoDB and MyISAM.
There are many differences between MyISAM and InnoDB, which has a key difference and we are going to introduce the COUNT (*) related to that MyISAM does not support transactions, MyISAM table-level lock is in the lock; and InnoDB supports transactions, and support line level locking.
Because MyISAM locks are table-level locking, so they need the serial same table above operation, so, MyISAM made a simple optimization is that it can put the number of rows in the table separately recorded, if used from a table COUNT (*) query time, you can return directly to the recorded values can, of course, the premise is not there where conditions.
MyISAM reason why the total number of rows in the table can be recorded for the COUNT (*) query uses, it is because MyISAM database table-level locking, will not have to modify the number of concurrent database rows, so the number of rows resulting from the query is accurate.
However, InnoDB, the cache can not do this operation because InnoDB supports transactions, most operations are row-level locking, so may the number of rows in the table may be concurrent modification, the number of rows cached recorded It is not accurate.
However, InnoDB or for COUNT (*) statement made some optimization.
In InnoDB, using the COUNT (*) query number of rows when the table is inevitable to conduct a sweep, then, can optimize the efficiency of the efforts to sweep the table in the process.
Starting from MySQL 8.0.13, for SELECT COUNT InnoDB's (*) FROM tbl_name statement, did do some optimization in the process of sweeping the table. Provided that the query does not contain GROUP BY or WHERE conditions.
We know, COUNT (*) is intended for statistical number of rows, so that he does not care about their own specific values found, so if he can sweep the table in the process, choose a low-cost index, then, it can greatly save time.
We know, InnoDB index into a clustered index (primary key index) and non-clustered index (non-primary key index), saved leaf nodes clustered indexes are whole rows, rather than clustered index leaf nodes save is the value of the primary key rows.
So, compared to a non-clustered index is much smaller than the clustered index, so MySQL will give priority to a minimum non-clustered index to sweep table. So, when we built the table, in addition to the primary key index, create a non-primary key index is still necessary.
So far, we have introduced over the MySQL database optimization for COUNT (*), which is the premise of optimizing the query does not contain WHERE and GROUP BY condition.
COUNT (*) and COUNT (1)
introduced over COUNT (*), then look at COUNT (1), for which there is no difference between the two in the end, online saying different opinions.
Some said COUNT (*) will be converted into COUNT (1) is executed, so the COUNT (1) less conversion step, so faster.
Some have even said, because for MySQL COUNT (*) to do a special optimized, so the COUNT (*) faster.
So, in the end Which statement is right? Look MySQL official documents is how to say:
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
Painting Key: same way, no performance difference. Therefore, the COUNT (1) and COUNT (*), MySQL optimization is exactly the same, faster than anyone else who does not exist!
That being COUNT (*) and COUNT (1), as recommended by Which it?
Recommended COUNT (*)! Because this is the syntax of the number of rows SQL92 standard statistical definition, and this is just based on MySQL to do the analysis on this issue in Oracle, also different opinions of it.
COUNT (field)
Finally, there is COUNT (field) we have not yet mentioned his query is relatively simple and crude, is a full table scan, and then determine the value of the specified field is not as NULL, NULL is not cumulative .
Compared COUNT (*), COUNT (field) field is one more step to determine whether the query is NULL, so his performance (*) slower than COUNT.
to sum up
This article describes the use of the COUNT function, mainly for the number of tables lines. The main uses are COUNT (*), COUNT (field) and COUNT (1).
Because COUNT (*) is the syntax of the number of rows SQL92 standard statistical definition, so he had a lot of MySQL optimization, MyISAM will be directly to the number of rows in the table separately recorded for COUNT (*) queries, InnoDB will in sweep when selecting the smallest index table to reduce costs. Of course, the premise of these optimizations are not conditional and inquiry where the group.
In InnoDB COUNT (*) and COUNT (. 1) is not implemented on the difference, and the same efficiency, but COUNT (field) field requires determination of non-NULL, so the efficiency will be lower.
Because the number of rows COUNT (*) is the syntax of the number of rows SQL92 standard statistical definition, and high efficiency, so please use the COUNT (*) query tables!
Original link: https://blog.csdn.net/hollis_chuang/article/details/102657937