This article comes from: Easy Shield laboratory
Before the rise of deep learning technology for a long period of time, the machine learning technology of text classification method based on the dominance of text classification field.
As shown below, features works + machine learning classifier has been the standard paradigm to solve the problem of text classification. For different business scenarios, algorithm engineers need to carefully design the corresponding feature works to achieve the best classification results.

By 2010, the depth of learning technology gradually on the rise, the pattern of text classification technology is correspondingly changed. Breaking above technical paradigm depth learning text classification method based on the text after simple pretreatment, fed directly to deep learning model, end to end training and inference. General, deep learning model for text classification last layer is softmax layer (multi-label problem was sigmoid), which is equivalent to LR model of machine learning classifier. Thus, the rest of the model is essentially automatic learning feature representation of the text, so the algorithm engineers no longer have to worry about what features of the project. But first, do not get too excited, learn better is not good text features, depending on the depth of the structural design and ultra-learning model parameters, the engineers still have to spend the saved time to adjust and super structure above model parameters.
According to the text algorithm is easy to shield team experience in the field of content security, presentation used in the project some depth to the learning model and a discussion of some technical details. Deep learning is a popular direction in recent years, academic and industry researchers have proposed many valuable ways shared in this way but a few representative work, a reference work.
CNN
 The figure is a typical single model structure CNN. After the first vector matrix text into words, and then checked each convolution matrix is convolved different size, each plurality of convolution output feature map, then max pooling, all feature map spliced together to form a single vector representation, and finally with a layer of full connectivity softmax operation, the output classification score.
The figure is a typical single model structure CNN. After the first vector matrix text into words, and then checked each convolution matrix is convolved different size, each plurality of convolution output feature map, then max pooling, all feature map spliced together to form a single vector representation, and finally with a layer of full connectivity softmax operation, the output classification score.
FIG only one example, various types of parameters are ultra small, in actual use, the size of the vector 50 or more words, generally the size of the convolution kernel 2 ~ 7, feature quantity map in each of several tens to several convolved hundred. In addition max pooling of pooling may also be replaced by other methods, such as average pooling, but in general are more suitable for max pooling classification scene. Under normal circumstances, the ultra-tuning parameters, single-layer CNN model has been able to apply most text classification scene. But others use a multi-layer CNN model, our experience is about the same number of parameters of the premise, multi-layer CNN found no significant effect improved.
RNN
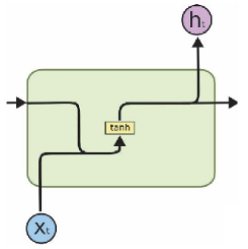
RNN model is mainly used for processing sequence data, and the text is represented as a natural sequence of several words, so use RNN model to model is quite natural for text. Unlike the convolution fully connected network or between different words corresponding inner RNN hidden layer are linked to each other: the input of the current word in addition to the output of the hidden layer is the input layer, the hidden layer further comprises an output of the previous word.

When the sequence length is longer, there is a gradient-based RNN model explosions and gradient disappearing. LSTM and GRU are two modified versions of RNN, they control the dissemination of information through the mechanism in RNN door, eased RNN gradient disappearing (RNN gradient explosion problem can be solved by gradient clipping technique). As can be seen from the figure, the GRU LSTM structure is similar, except that the main GRU used for updating door LSTM input gates and doors forgetting simplified.
Since the output of the last word of the previous information has been integrated RNN words, RNN and generally when the output of the last word as characteristic for text categorization entire text representation, i.e. full connectivity and softmax classification score with the last calculated output plus. Of course, we typically use a multi-layer structure RNN calculated classification score with the output of the final layer RNN last word.
RNN flow of data is unidirectional only from front to back or back to front. Bi-RNN offers an improvement, which would be using forward and backward RNN RNN, after the last word before the text is output to the first word and the RNN output to RNN spliced together, as the text feature representation. From our experience point of view, this improvement effect Bi-RNN enhance Obviously, we know that there is a greater attention to enhance the role model, but some business scenarios in which relatively limited attention to enhance the Bi-LSTM, which Description Bi-LSTM its effect has been relatively close to the theoretical upper limit of the problem itself.
RCNN
 RCNN is also one of the early depth learning technique to model frequently used text classification above. RCNN each word is defined as a left context and right context of two variables, specifically calculated as:
RCNN is also one of the early depth learning technique to model frequently used text classification above. RCNN each word is defined as a left context and right context of two variables, specifically calculated as:
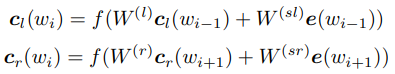
Final together each word represented by its own context word vector and two splice, then the first layer by layer fully connected, then make max pooling individual vectors form. Why is this model called RCNN (Recurrent Convolutional Neural Networks) it? First, from the definition of left context and the right context can be seen in this part is actually a two-way RNN, but finally stitching on the original word vector. Further, there does not take the output of the last word only calculated classification score, but connected to the output of each full word then make max pooling. In fact, this is equivalent to be fully connected size is [1, emb_size] and a strip of two-dimensional convolution operation, and then later followed max pooling, which is a typical structure of CNN.
Attention
Attention mechanism is widely used in natural language processing, image recognition, voice recognition, and other various types of learning tasks in depth, the depth of learning technology is one of the most interesting and in-depth understanding of the core technology. Attention mechanism to be understood that a given Q, calculated from a series of key KV heavy weight of each of V, then the weighted average of the V. Specific formula is as follows:

Where f is a function of Q and K scoring, may have different implementations, a little common plot, scaled dot product, additive, bilinear method, we can also own other calculation methods.
We note Attention is directed to calculating the Q, K, V three inputs, when Q = K, this technique is known as Attention self-attention. In fact, self-attention is currently the most attention with technology that does not require additional data, based only on the text itself context, the importance of the text can be calculated in each word. As can be seen, the attention is essentially re-calculated weight of each word, then the weighted average. And we know that in the future word2vec come out in how the word vectors of a plurality of words becomes a single vector to express the issue of sentence, there is a practice that is a weighted average, such as a weighted average based on tf-idf. So what is this attention and the weighted average difference is? The most essential difference is the same word, Common weighted average method of weights are fixed context dynamically calculated, different texts and different positions (multiplied up word frequency coefficient), the right attention method is weighted according to its weight is not the same. It's like the human visual attention, to see different areas of the image focus is not the same, so we put this technology called attention. Word with a different output obtained in different contexts, so that such a characteristic problem polysemous attention naturally good fit method of NLP.
DETAILED text classification model, Attention use more flexible, may be used alone Attention classification, and may be CNN, RNN other binding model. Currently there is a common model transformer, HAN, RNN + attention, CNN + attention, Bi-RNN + attention and so on, not to undertake further explanation.
Fasttext
FastText Facebook in 2016 is a lightweight open source text representation and text classification tools. It is characterized by having a depth comparable to the time while complex neural network model for text classification accuracy, training and forecasting very efficient, CNN one day of training data, FastText just a few seconds can be.

FastText reason why so efficient, there are three main reasons. First, the model is particularly simple, embedding find the text of all the words and then add an average softmax classifier. Second, this is a hierarchical classification softmax softmax classifier, the classification category in a lot of time more useful. Third, FastText using C ++ implementation, and the ability of the code is also very strong, so although there are many versions of reproduction, but are not original and efficient.
Despite the simple model structure, FastText use the n-gram and subword both technologies to help enhance the text classification results. n-gram word order help local model captures text, and most text classification tasks do not require too long dependency. subword also called char n-gram, is to break down smaller sub-word string pieces, which can be better for unknown words and rare words modeling, while learning to affix the same word semantic relations.
Overall, FastText for applications that require real-time high of text classification accuracy of less demanding on the scene at the same time, can be used as a baseline of the new algorithm.
Bert
BERT is a pre-trained language model Google released in 2018, it set a record 11 NLP tasks. BERT release makes the field of NLP really entered into the era of common tasks for downstream pre-trained model, but also vigorously entered the era of miracles - through more data, more accurate model for higher rates, since then various technology giant launched the model increases, the training data used more and more, simply show off their wealth. In fact, there are a lot of studies pre-trained language model before BERT, like ELMo, GPT are then more prominent achievements, many of their ideas and methods are borrowed from BERT.
Compared to predecessors, BERT was aroused so much attention, mainly because it's really stunning effect, and set records in more than NLP tasks above, and to enhance the rate are quite large. More importantly, BERT used in these tasks above do not require elaborate downstream network, basically take a simple prediction structure, then simply fine-tuning on OK.

BERT model structure itself is not complicated, is divided into three parts: the bottom is embedding assembly, comprising a combination of words, the position of token types and three kinds of embedding; Deep Web intermediate layer is composed of a plurality of Transformer encoder (base version 12 floors, large version is 24 layers); the top is the component associated with the training mission, mainly softmax network. The more important innovations BERT model has two aspects, namely Masked LM and Next Sentence Prediction (NSP). Masked LM replacement portion with a word in the sentence [MASK], the true target model is to predict words on [the MASK] position.
Masked LM technology allows the introduction of BERT model into a self-encoded language model, its goal is not optimized to maximize the likelihood function of the sentence, but part of the joint conditional probability maximization mask, so BERT model can be used bidirectional Transformer, before and after use contextual information on the current word prediction.
The language model before BERT is not truly two-way, which can be considered a relatively large improvements. BERT allow the introduction of NSP task model can better learn to the semantics of the whole sentence level. In NSP task, a sentence is input to the model (to be precise fragment, each fragment may comprise more than one sentence), the target sentence is input to the prediction whether the original two consecutive sentences. 50% real training data extracted from a corpus of sentences successive pair of the other 50% is from the corpus of random combinations. Optimization goals when training model is to minimize Masked LM and NSP combined loss of function.
BERT text classification model used in the process is relatively simple, single model input is the text, there is no need to carry out the word mask, do not form sentences right, the first output using a word as a vector representation of the text, and then take softmax network. Our experimental results show that the model BERT all methods described in this article is the best performance, now part of the online application on complex business scenarios.
to sum up
This article only describes several deep learning methods used in the security business is easy to shield the text, in fact, Netease's easy to shield the contents of security services include text detection, an image detection, video detection, audio detection, artificial intelligence review and audit system the product, and advertising compliance, website content detection, detection of document content, historical data cleansing, audio and video, social entertainment, government and enterprise, and media solutions. Content security services currently provided externally has been upgraded to third-generation artificial intelligence technology to provide Jurisprudence, involving politics, fear of violence, thousands of small class advertising than a dozen categories of harmful content filtering service intelligent recognition, recognition accuracy rate of more than 99.8 %.
Summarized above, it is the industry's mainstream approach to solve the problem of text classification. If you are using a fixed benchmark corpus for evaluation, the accuracy of these models in the above indicators did show some differences and pros and cons. But specific to text content security business scenario, which is difficult to model the best performing such a conclusion.
In actual use, according to the required characteristics of the text in different scenarios, taking into account the sample size, the size of the vocabulary, the processing time, various factors such as the size of the model parameters, to select the appropriate model. In fact, the role model is secondary, the key factors that determine the ultimate effect is to build a corpus, with large enough corpus of high quality, even if the model simple point, the effect is better than complex models. Built corpus is a long-term task that requires clear criteria for the various categories of irregularities and segmentation, clear and specific standards is a prerequisite for high quality labeling corpus. But also continue to invest manpower to collect and label samples, so that the sample corpus to try to cover different types of data.
In addition, the real text content security system is not able to get several models, it is a proven solution, the use of extensive testing instruments covered are different scenarios to ensure higher detection rate.
references
-
https://www.aclweb.org/anthology/D14-1181
-
http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
-
https://medium.com/@saurabh.rathor092/simple-rnn-vs-gru-vs-lstm-difference-lies-in-more-flexible-control-5f33e07b1e57
-
https://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/download/9745/9552
-
https://arxiv.org/pdf/1706.03762.pdf
-
https://arxiv.org/pdf/1810.04805.pdf