jdk1.7.0_79
HashMap is arguably one of each data structure Java programmers use the most, and have been witnessed in its presence. About HashMap, usually you can tell it is not thread safe. This article is to be mentioned in a multi-threaded environment HashMap - ConcurrentHashMap, obviously it must be thread-safe, we inevitably have to discuss the same hash table, and how it is implemented thread-safe, its efficiency and how, as well as a container for mapping Hashtable is thread-safe, but it only seems to appear in the written test, interview questions, the coding in reality it has basically been abandoned.
About thread HashMap insecurity, under the influence of multi-threaded environment, it brings absolutely inconsistent data such cases is not only dirty data appear serious is it possible to bring a program loop , it may be a bit weird, but indeed in recent years the project has met with colleagues CPU100% full load operation, the analysis results in a multithreaded environment HashMap result in a program loop. For Hashtable, view its source code can be seen, Hashtable thread-safe way is to use the synchronized keyword, this will lead to inefficiency, but ConcurrentHashMap is using a different thread ensure safe way - segmented lock . Unlike Hashtable as the whole table is locked but the lock segment array element, if the element thread 1 segment1 of accessed segments, and the thread elements accessed segment Segment2 2, independently of each other they may be performed simultaneously operating. If a reasonable segmentation is the key issue.
ConcurrentHashMap HashMap and the results are consistent, is also stored as an object Entry of data, the other one is a lock --Segment segment mentioned above. It inherits from ReentrantLock (ReentrantLock on, refer to "5.Lock ReentrantLock interface and its implementation"), so it has all the characteristics ReentrantLock - reentrant, exclusive like.
FIG ConcurrentHashMap structure is shown below:
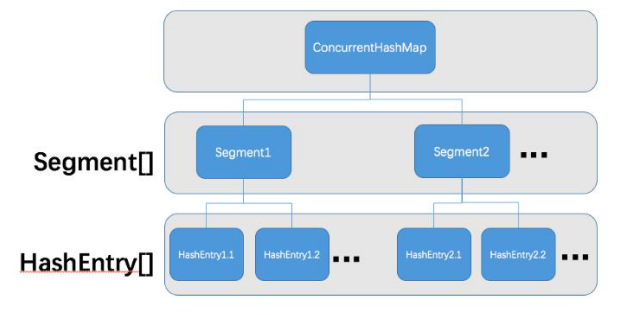
Can be seen compared to HashMap, ConcurrentHashMap on Entry arrays are Segment, this is what we mentioned above segmented lock and reasonable to determine the number of segments will be able to better improve the efficiency of concurrency, is to determine how we look at ConcurrentHashMap the number of segments.
ConcurrentHashMap initialized through its constructor public ConcurrentHashMap (int initialCapacity, float loadFactor , int concurrencyLevel) is completed, if not specified in the case of the parameters, initial capacity initialCapacity = DAFAULT_INITIAL_CAPACITY = 16, load factor loadFactor = DEFAULT_LOAD_FACTOR = 0.75f, concurrent level concurrencyLevel = DEFAULT_CONCURRENCY_LEVEL = 16, the same as the first two and HashMap. As the degree of load factor represents the amount of data using a hash space, initialCapacity (total capacity) * loadFactor (load factor) =, this formula have found that, if the load is greater the higher the degree of filling factor of the hash table, i.e. can accommodate more element, but this element, the more, the list is large, then the index will reduce efficiency. If the load factor is smaller, on the contrary, the index will be high efficiency, the more the exchange is paid for wasted space. It represents an estimate of a maximum level of concurrency how many common threads to modify the Map , and you can see it later segment associated array, the array length of the segment is calculated by concurrencyLevel.
//以默认参数为例initalCapacity=16,loadFactor=0.75,concurrencyLevel=16 public ConcurrentHashMap(int initalCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; int sshift = 0; int ssize = 1;//segment数组长度 while (ssize < concurrencyLevel) { ++sshift; ssize <= 1; } // After ssize left 4, ssize = 16, = ssift. 4 / * segmentShift bits for participation hashed, segmentMask mask is hashed, where the hash function operation associated HashMap and have similarities * / the this .segmentShift = 32 - ssift; // Fragment offset = 28 segmentShift the this .segmentMask = ssize the -. 1; // segment mask = 15 segmentMask (1111) IF (initialCapacity> MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; int C = initialCapacity / ssize The; // C. 1 = IF (ssize The C * < initialCapacity) ++ C; int CAP = MIN_SEGMENT_TABLE_CAPACITY; // MIN_SEGMENT_TABLE_CAPACITY = 2 the while (CAP <C) // CAP = 2, =. 1 C, to false CAP = <<. 1; // CAP is HashEntry segment length in the array, a minimum of 2 / * create an array of segments and segment [0] * / segment <K, V> S0 = new new segment <K, V> (loadFactor, ( int ) (* loadFactor CAP), (HashEntry <K, V> []) new newHashEntry [CAP]); // Parameter meaning: load factor = 1, the data capacity = (int) (2 * 0.75 ) = 1, the total capacity = 2, so the total capacity of each HashEntry Segment 2 is the actual data capacity It is. 1 Segment <K, V> = SS (Segment <K, V> []) new new Segment [ssize The]; // Segments array size of 16 UNSAFE.putOrderedObject (SS, SBASE, S0); the this .segments = SS; }
The above is the whole initialization process, initialization is mainly the length and size of the segments determined by the load factor for each Segment capacity size. Segment After determining the good, the next focus is how to accurately locate Segment. The method of positioning Segment is positioned by a hash function, a hash of the first element by a secondary hash method, the algorithm is more complex, there is only one object - to reduce a hash collision, so that the element can be evenly distributed on different Segment , the container improve access efficiency.
We used the most intuitive to observe ConcurrentHashMap put method is how to calculate the hash value of the key value through the targeting of Segment:
//ConcurrentHashMap#put public V put(K key, V value) { Segment <K, V> S; IF (value == null ) the throw new new a NullPointerException (); int the hash = the hash (key); // the hash function to calculate the hash value of the key value int J = (the hash> segmentShift >>) & segmentMask; // this operation is to locate the Segment array subscripts, are segmentFor return before jdk1.7 Segment, directly after 1.7 cancel this method, calculating the direct array subscript, then offset by the underlying operating Get Segment IF ((S = (Segment <K, V>) UNSAFE.getObject // Nonvolatile; Recheck in (Segments, (J << SSHIFT) + SBASE)) == null ) // in ensureSegment S = ensureSegment (J) ; // by cheaper less than the amount of the positioning method is called ensureSegment positioning Segment return s.put(key, hash, value, false); }
Segment.put approach is the key, the value added to the configured node corresponding to Entry Segment segment, if the segment has elements (i.e. two key hash values represents a repeating key) will be added into the list of the latest header ), the whole process must be locked safe.

Wish to continue in-depth Segment.put method:
//Segment#put final V put(K key, int hash, V value, boolean onlyIfAbsent) { HashEntry <K, V> = tryLock Node ()? Null : scanAndLockForPut (Key, the hash, value); // nonblocking acquire the lock acquisition success node = null, failed V oldValue; the try { HashEntry <K, V> [] Tab = Table; // HashEntry array length corresponding to Segment int index = (tab.length -. 1) & the hash; HashEntry <K, V> = First entryAt (Tab, index); // get the first value HashEntry array for (HashEntry <K, V> E = First ;;) { IF (E =! Null ) { // HashEntry array value already exists K K; IF ((K = e.key) == || Key (e.hash key.equals && == hash (K))) { // Key value and hash values are equal, replace the old values directly oldValue = e.Value; IF (! onlyIfAbsent) { e.value = value; ++modCount; } break; } E = e.next; // not traverse the same value is continued, until the key value is found equal to the array element or a null HashEntry of } the else { // an element position in the array is HashEntry null IF (Node =! null ) node.setNext (First); // Next added new node (key) is a reference pointing to the first element of the array HashEntry the else // has acquired the lock Segment Node = new new HashEntry <K, V> (the hash, Key, value, first) int C = COUNT +. 1 ; iF (C> threshold && tab.lenth <MAXIUM_CAPACITY) // before determining whether to insert the expansion, the expansion of the HashMap ConcurrentHashMap different, only ConcurrentHashMap Segment capacity expansion, expansion throughout the HashMap is the rehash ( node); the else setEntryAt (Tab, index, node); // set the head node ++ ModCount; // total capacity COUNT = C; oldValue = null; break; } } } finally { unlock(); } return oldValue; }
The above is substantially ConcurrentHashMap add an element to the process, is the need to understand the concept of segment ConcurrentHashMap lock. Segment of JDK1.6 positioned in relatively simple, be calculated directly Segment array subscript after the return of specific Segment, JDK1.7 is calculated by the shift amount, is calculated to be empty, there is a check acquired Segment, guess 1.7 using the underlying native is to improve the efficiency of different JDK1.8 ConcurrentHashMap there, yet in-depth study, it seems that the results of data into a red-black tree.
For get method ConcurrentHashMap no longer analysis process summary sentence: The calculated hash value key value, the hash value calculated from the corresponding Segment, HashEntry list traversal and then look in the Segment.
Want to learn more information, you can scan the next Fanger Wei code
