Design and implementation of compiler theory lexical analysis procedure 5
This program is individually checked operation, and can spot completion code.
Lexical analysis program ( Lexical Analyzer ) requirements:
- stream from a source program composed of character scan left to right
- identify the lexical meaning of the word ( Lexemes )
- Return word record (word class, the word itself)
- filtered spaces
- skip comments
- lexical errors found
Program Structure:
Input: character stream (input what way, what data structure stored)
deal with:
- Traverse (What traversal)
- lexical rules
Output: word stream (what output form)
- tuple
Word class:
1. Identifier (10)
2. unsigned (11)
3. Leave the word (the word one yard)
4. Operator (word one yard)
5. delimiter (word one yard)
| Word symbols |
Species do not code |
Word symbols |
Species do not code |
| begin |
1 |
: |
17 |
| if |
2 |
:= |
18 |
| then |
3 |
< |
20 |
| while |
4 |
<= |
21 |
| do |
5 |
<> |
22 |
| end |
6 |
> |
23 |
| l(l|d)* |
10 |
>= |
24 |
| dd* |
11 |
= |
25 |
| + |
13 |
; |
26 |
| - |
14 |
( |
27 |
| * |
15 |
) |
28 |
| / |
16 |
# |
0 |
Source code is as follows:
#include<stdio.h>
#include<string.h>
#include<iostream.h>
char prog[80],token[8];
char ch;
int syn,p,m=0,n,row,sum=0;
char *rwtab[6]={"begin","if","then","while","do","end"};
void scaner()
{
for(n=0;n<8;n++) token[n]=NULL;
ch=prog[p++];
while(ch==' ')
{
ch=prog[p];
p++;
}
if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')) //可能是标示符或者变量名
{
m=0;
while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))
{
token[m++]=ch;
ch=prog[p++];
}
token[m++]='\0';
p--;
syn=10;
for (n = 0; n < 6; n ++) // and the identified character identifiers defined for comparison,
IF (strcmp (token, rwtab [n-]) == 0)
{
SYN = n-+. 1;
BREAK;
}
}
the else IF ((CH> = '0' && CH <= '. 9')) // number
{
{
SUM = 0;
the while ((CH> = '0' && CH <= '. 9'))
{
SUM CH * 10 + SUM =-'0 ';
CH PROG = [P ++];
}
}
the P--;
SYN =. 11;
IF (SUM> 32767)
SYN = -1;
}
the else Switch (CH) // other characters
{
Case '<': m = 0; token [m ++] = CH;
CH = PROG [P ++];
IF (CH == '>')
{
SYN = 21 is;
token [m ++] = CH;
}
the else IF (CH = = '=')
{
syn=22;
token[m++]=ch;
}
else
{
syn=23;
p--;
}
break;
case'>':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=24;
token[m++]=ch;
}
else
{
syn=20;
p--;
}
break;
case':':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=18;
token[m++]=ch;
}
else
{
syn=17;
p--;
}
break;
case'*':syn=13;token[0]=ch;break;
case'/':syn=14;token[0]=ch;break;
case'+':syn=15;token[0]=ch;break;
case'-':syn=16;token[0]=ch;break;
case'=':syn=25;token[0]=ch;break;
case';':syn=26;token[0]=ch;break;
case'(':syn=27;token[0]=ch;break;
case')':syn=28;token[0]=ch;break;
case'#':syn=0;token[0]=ch;break;
case'\n':syn=-2;break;
default: syn=-1;break;
}
}
int main()
{
p=0;
row=1;
cout<<"Please input string:"<<endl;
do
{
cin.get(ch);
prog[p++]=ch;
}
while(ch!='#');
p=0;
do
{
scaner();
switch(syn)
{
case 11: cout<<"("<<syn<<","<<sum<<")"<<endl; break;
case -1: cout<<"Error in row "<<row<<"!"<<endl; break;
case -2: row=row++;break;
default: cout<<"("<<syn<<","<<token<<")"<<endl;break;
}
}
while (syn!=0);
}
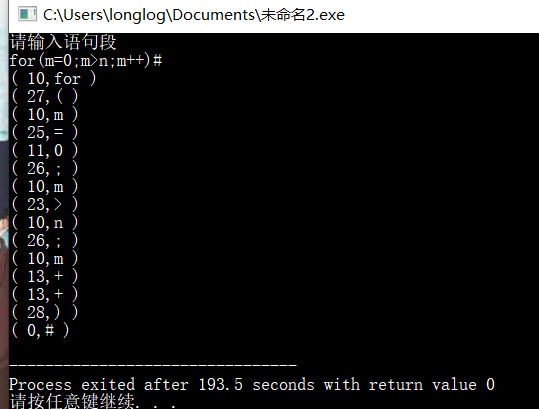
Screenshot program results as follows: