Thinking
if tf read a file like this: 1. reading the file, the file data into memory 2. calculation. Then it means that the read and calculations are serial, inefficient.
So a simple way to improve efficiency, step two is to parallelize.

Such data can be separated from the read data calculations.
Improved tf
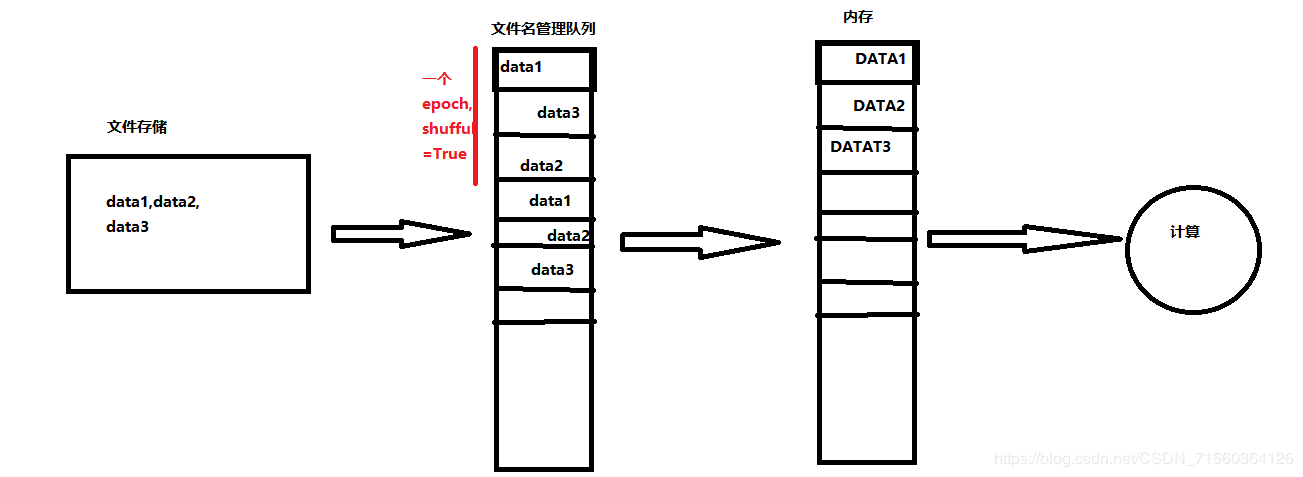
tf data read further, add a file name management queue for data to be processed first file stored, so that you can with the epoch (all data will be training again called a epoch) closely together If required two epoch, just need to manage these files in the file name can be stored in the queue twice. We need to use this data when obtaining files directly from the file name management queue, and then get the file into memory queue. Where filename management queue will be added behind the last file end mark for the program throws a OutOfRangeError and prompt completion of all the files have been read and calculate, end the program.
Correlation function
to create the file name of the queue:
filename_queue = tf.train.string_input_producer(fliename_list, shuffle=False, num_epochs=NUM)
Read data from the file name of the queue:
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
A step to create a queue, the next step to fill the queue, the system calculates the data get calculated:
tf.train.start_queue_runners()
reference:
"21 Fun project tensorflow"