Dropout is the depth of learning a means of preventing over-fitting, in an interview also often asked, it is necessary to get to know its principles.
1 Dropout mode of operation
During training the neural network, for one iteration of a neural network, to some randomly selected and temporarily hidden neurons (discarded), and then to this training and optimization. In the next iteration, we continue to hide some random neurons, and so on until the end of training. Because it is random discarded, and therefore each of a mini-batch training in different networks.
In training, each neural cell is retained with a probability $ p $ (Dropout discard rate $ 1-p $); in the prediction phase (beta), each neural cell is present, the weighting parameter to be multiplied $ $ W to $ p $, output is: $ pw $. Diagram is as follows:
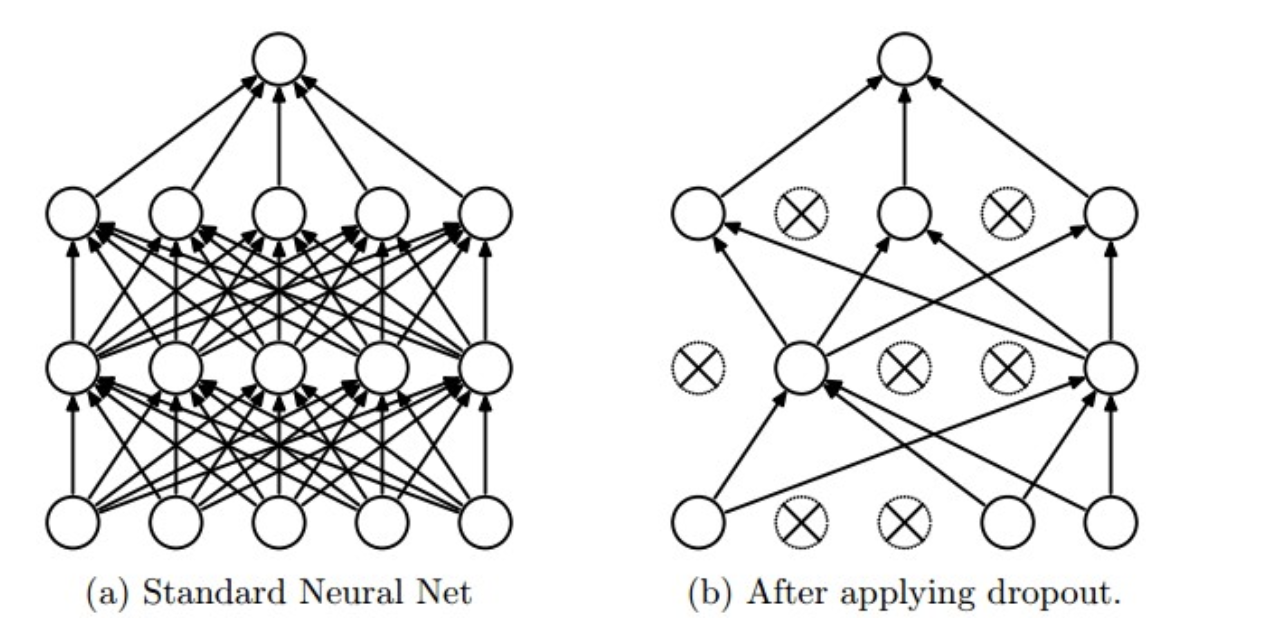
Prediction stage need to take on $ p $ of reasons:
A neural one hidden layer element output before the $ Dropout $ is $ x $, training expectations after $ Dropout $ a $ E = px + (1-p) \ dot 0 $; In the prediction stage the layer neural element is always active, in order to maintain the same level of output expected value and obtain the same result, it is necessary to adjust the $ x-> px $. $ p $ which is a Bernoulli distribution (distribution 0-1) probability value 1 .
2 Dropout achieve
As previously described, the hidden part of the random training neurons, p must be multiplied by the prediction. code show as below:
. 1 Import numpy AS NP 2 . 3 P = 0.5 # neuronal activation probability . 4 . 5 DEF train_step (X-): . 6 "" " X-the contains The Data " "" . 7 . 8 # three-layer backpropagation neural network as an example . 9 Hl = NP .maximum (0, np.dot (W1 of, X-) + B1) 10 Ul = np.random.rand (H1.shape *) <P # First Dropout mask . 11 Hl Ul * = # drop! 12 is H2 of np.maximum = (0, np.dot (W2 of, Hl) + B2) 13 is U2 = np.random.rand (H2.shape *) <P # SECOND mask Dropout 14 H2 *= U2 # drop! 15 out = np.dot(W3, H2) + b3 16 17 18 def predict(X): 19 # ensembled forward pass 20 H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activations 21 H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activations 22 out = np.dot(W3, H2) + b3
3 Reverse Dropout
A slightly different approach is to use a reverse Dropout (Inverted Dropout). The method comprises activating the scaling function during the training phase, the test phase so that it remains unchanged. Scaling factor is to keep the probability of the reciprocal of $ 1 / p $. So we change the thinking, the data is 1 / p scaling time in training, during training, you do not need to do anything.
Reverse Dropout is defined only once and only changed the model parameter (hold / drop probability) to use the same model for training and testing . In contrast, direct Dropout, need to modify the network during the testing phase . Because if you do not multiplied by a scaling factor p, the output of the neural network will produce a higher relative to the continuous desired value of neurons (neurons may thus saturated): Thus Dropout reverse is more common implementation. code show as below:
1 p = 0.5 # probability of keeping a unit active. higher = less dropout 2 3 def train_step(X): 4 # forward pass for example 3-layer neural network 5 H1 = np.maximum(0, np.dot(W1, X) + b1) 6 U1 = (np.random.rand(*H1.shape) < p) / p # first dropout mask. Notice /p! 7 H1 *= U1 # drop! 8 H2 = np.maximum(0, np.dot(W2, H1) + b2) 9 U2 = (np.random.rand(*H2.shape) < p) / p # second dropout mask. Notice /p! 10 H2 *= U2 # drop! 11 out = np.dot(W3, H2) + b3 12 13 # backward pass: compute gradients... (not shown) 14 # perform parameter update... (not shown) 15 16 def predict(X): 17 # ensembled forward pass 18 H1 = np.maximum(0, np.dot(W1, X) + b1) # no scaling necessary 19 H2 = np.maximum(0, np.dot(W2, H1) + b2) 20 out = np.dot(W3, H2) + b3
Why 3. Dropout can prevent over-fitting?
( 1) averaging effect
To return to the standard model that is no dropout, we use the same training data to train five different neural networks, usually get five different results, then we can adopt "five results averaged" or "majority win the voting strategy "to decide the final result. For example three networks judgment result is the number 9, it is likely that the real result is that the number 9, the other two networks gives erroneous results. This "together averaging" strategy usually can effectively prevent over-fitting problem. Because different networks may have different over-fitting, averaging it is possible to make some "reverse" fitting cancel each other out. dropout out different hidden neurons in different training on a similar network, randomly deleted half hidden neurons causes the network structure has been different, the overall dropout process is equivalent to a number of different neural networks averaged. The different networks have different over-fitting, some of each other "reverse" fitting offset each other to reduce the over-fitting can be achieved as a whole.
(2) reduce the complexity of co-adaptation between neurons relations
With the author of the original words were "standard neural network, each derivative parameters received indicate how it should change in order to reduce the final loss of function, and given all the other states of the neural network unit, so the nerve cells may be amended in a performed the wrong way other neural network unit is changed. This can lead to complications and co-adaptation (CO-Adaptations) . As these phenomena were not extended to accommodate no data will lead to over-fitting. we assume that for each hidden layer neural network unit, by Dropout other hidden layer neural network unit does not reliably preventing the occurrence of co-adaptation. Thus, a hidden layer neuron can not rely on other specific neurons to correct its error. "
因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
(3)Dropout类似于性别在生物进化中的角色
物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。
4 参考
1 http://cs231n.github.io/neural-networks-2/#reg
2 http://jmlr.org/papers/volume15/srivastava14a.old/srivastava14a.pdf