problem
What (1) Phaser that?
(2) Phaser What features?
(3) Phaser CyclicBarrier and relative advantages of CountDownLatch?
Brief introduction
Phaser, translated to the stage, it applies to such a scenario, a large task can be divided into several stages to complete, and each phase of the mission may be multiple threads execute concurrently, but must be on a stage tasks are completed before they can execution of the next phase of the mission.
Although this scenario CyclicBarrier or CountryDownLatch can also be achieved, but much more complex. First, the specific needs of the number of stages is likely to become, and secondly, the number of tasks at each stage may also be capricious. Compared to CyclicBarrier and CountDownLatch, Phaser more flexible and more convenient.
Instructions
Let's look at a simple use case:
public class PhaserTest {
public static final int PARTIES = 3;
public static final int PHASES = 4;
public static void main(String[] args) {
Phaser phaser = new Phaser(PARTIES) {
@Override
protected boolean onAdvance(int phase, int registeredParties) {
// 【本篇文章由公众号“彤哥读源码”原创,请支持原创,谢谢!】
System.out.println("=======phase: " + phase + " finished=============");
return super.onAdvance(phase, registeredParties);
}
};
for (int i = 0; i < PARTIES; i++) {
new Thread(()->{
for (int j = 0; j < PHASES; j++) {
System.out.println(String.format("%s: phase: %d", Thread.currentThread().getName(), j));
phaser.arriveAndAwaitAdvance();
}
}, "Thread " + i).start();
}
}
}Here we define a large task requires four stages of completion, each phase requires three small task, for these tasks, we were starting three threads to perform these tasks, view the output results:
Thread 0: phase: 0
Thread 2: phase: 0
Thread 1: phase: 0
=======phase: 0 finished=============
Thread 2: phase: 1
Thread 0: phase: 1
Thread 1: phase: 1
=======phase: 1 finished=============
Thread 1: phase: 2
Thread 0: phase: 2
Thread 2: phase: 2
=======phase: 2 finished=============
Thread 0: phase: 3
Thread 2: phase: 3
Thread 1: phase: 3
=======phase: 3 finished=============We can see that each stage are three threads are completed before entering the next stage. This is how to achieve it, let us work together to learn it.
Principle guess
According to the principles of our previous study AQS probably guess the realization of the principle Phaser.
First, you need to store the current stage of phase, the phase of the current number of tasks (participants) parties, the number of participants is not completed, we can put these three variables stored in a state variable.
Second, the need to store a queue of participants to complete, when the last participant to complete the task, the participants need to wake up in the queue.
Ah, pretty much like this.
With case above into:
The initial stage of the current is zero, the number of participants is three, the number of participants is not complete 3;
Performing a first thread to phaser.arriveAndAwaitAdvance();entering the queue;
The second thread execution to phaser.arriveAndAwaitAdvance();entering the queue;
The third thread to execute phaser.arriveAndAwaitAdvance();when the first phase of this executive summary onAdvance(), and then wake up the first two threads to continue to the next phase of the mission.
Ah, the whole can make sense, as it is not so, let us look at the source of it.
Source code analysis
The main inner class
static final class QNode implements ForkJoinPool.ManagedBlocker {
final Phaser phaser;
final int phase;
final boolean interruptible;
final boolean timed;
boolean wasInterrupted;
long nanos;
final long deadline;
volatile Thread thread; // nulled to cancel wait
QNode next;
QNode(Phaser phaser, int phase, boolean interruptible,
boolean timed, long nanos) {
this.phaser = phaser;
this.phase = phase;
this.interruptible = interruptible;
this.nanos = nanos;
this.timed = timed;
this.deadline = timed ? System.nanoTime() + nanos : 0L;
thread = Thread.currentThread();
}
}Participants in the queue to complete the node, here we only need to focus on threadand nexttwo properties can be, it is clear that this is a single linked list, the thread is stored into the team.
The main property
// 状态变量,用于存储当前阶段phase、参与者数parties、未完成的参与者数unarrived_count
private volatile long state;
// 最多可以有多少个参与者,即每个阶段最多有多少个任务
private static final int MAX_PARTIES = 0xffff;
// 最多可以有多少阶段
private static final int MAX_PHASE = Integer.MAX_VALUE;
// 参与者数量的偏移量
private static final int PARTIES_SHIFT = 16;
// 当前阶段的偏移量
private static final int PHASE_SHIFT = 32;
// 未完成的参与者数的掩码,低16位
private static final int UNARRIVED_MASK = 0xffff; // to mask ints
// 参与者数,中间16位
private static final long PARTIES_MASK = 0xffff0000L; // to mask longs
// counts的掩码,counts等于参与者数和未完成的参与者数的'|'操作
private static final long COUNTS_MASK = 0xffffffffL;
private static final long TERMINATION_BIT = 1L << 63;
// 一次一个参与者完成
private static final int ONE_ARRIVAL = 1;
// 增加减少参与者时使用
private static final int ONE_PARTY = 1 << PARTIES_SHIFT;
// 减少参与者时使用
private static final int ONE_DEREGISTER = ONE_ARRIVAL|ONE_PARTY;
// 没有参与者时使用
private static final int EMPTY = 1;
// 用于求未完成参与者数量
private static int unarrivedOf(long s) {
int counts = (int)s;
return (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK);
}
// 用于求参与者数量(中间16位),注意int的位置
private static int partiesOf(long s) {
return (int)s >>> PARTIES_SHIFT;
}
// 用于求阶段数(高32位),注意int的位置
private static int phaseOf(long s) {
return (int)(s >>> PHASE_SHIFT);
}
// 已完成参与者的数量
private static int arrivedOf(long s) {
int counts = (int)s; // 低32位
return (counts == EMPTY) ? 0 :
(counts >>> PARTIES_SHIFT) - (counts & UNARRIVED_MASK);
}
// 用于存储已完成参与者所在的线程,根据当前阶段的奇偶性选择不同的队列
private final AtomicReference<QNode> evenQ;
private final AtomicReference<QNode> oddQ;The main property stateand evenQand oddQ:
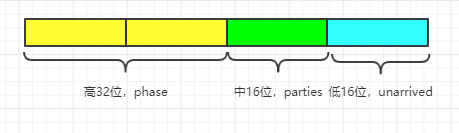
(1) state, the state variable, the upper 32 bits to store the current phase Phase, the number of participants of the intermediate storage 16, stores the lower 16 bits of the number of participants is not completed by the public [This article No. "brother read source Tong" original, Please support the original, thank you! ];
(2) evenQ and oddQ, participants completed store queue, when the last participant to complete the task the participants in the queue wake proceed to the next phase of the mission, or the end of the mission.
Construction method
public Phaser() {
this(null, 0);
}
public Phaser(int parties) {
this(null, parties);
}
public Phaser(Phaser parent) {
this(parent, 0);
}
public Phaser(Phaser parent, int parties) {
if (parties >>> PARTIES_SHIFT != 0)
throw new IllegalArgumentException("Illegal number of parties");
int phase = 0;
this.parent = parent;
if (parent != null) {
final Phaser root = parent.root;
this.root = root;
this.evenQ = root.evenQ;
this.oddQ = root.oddQ;
if (parties != 0)
phase = parent.doRegister(1);
}
else {
this.root = this;
this.evenQ = new AtomicReference<QNode>();
this.oddQ = new AtomicReference<QNode>();
}
// 状态变量state的存储分为三段
this.state = (parties == 0) ? (long)EMPTY :
((long)phase << PHASE_SHIFT) |
((long)parties << PARTIES_SHIFT) |
((long)parties);
}There is also a constructor parent and the root, which is used to construct a multi-level stage, is beyond the scope of this paper, it is ignored.
The focus is to see the way the assignment of state, high 32 stores the current stage phase, the number of intermediate storage 16 participants, the lower 16 bits to store the number of participants is not complete.
Here we take a look at the source of several major methods:
register () method
A registered participant, if the method is called, onAdvance () method is executed, the method waits for its finished.
public int register() {
return doRegister(1);
}
private int doRegister(int registrations) {
// state应该加的值,注意这里是相当于同时增加parties和unarrived
long adjust = ((long)registrations << PARTIES_SHIFT) | registrations;
final Phaser parent = this.parent;
int phase;
for (;;) {
// state的值
long s = (parent == null) ? state : reconcileState();
// state的低32位,也就是parties和unarrived的值
int counts = (int)s;
// parties的值
int parties = counts >>> PARTIES_SHIFT;
// unarrived的值
int unarrived = counts & UNARRIVED_MASK;
// 检查是否溢出
if (registrations > MAX_PARTIES - parties)
throw new IllegalStateException(badRegister(s));
// 当前阶段phase
phase = (int)(s >>> PHASE_SHIFT);
if (phase < 0)
break;
// 不是第一个参与者
if (counts != EMPTY) { // not 1st registration
if (parent == null || reconcileState() == s) {
// unarrived等于0说明当前阶段正在执行onAdvance()方法,等待其执行完毕
if (unarrived == 0) // wait out advance
root.internalAwaitAdvance(phase, null);
// 否则就修改state的值,增加adjust,如果成功就跳出循环
else if (UNSAFE.compareAndSwapLong(this, stateOffset,
s, s + adjust))
break;
}
}
// 是第一个参与者
else if (parent == null) { // 1st root registration
// 计算state的值
long next = ((long)phase << PHASE_SHIFT) | adjust;
// 修改state的值,如果成功就跳出循环
if (UNSAFE.compareAndSwapLong(this, stateOffset, s, next))
break;
}
else {
// 多层级阶段的处理方式
synchronized (this) { // 1st sub registration
if (state == s) { // recheck under lock
phase = parent.doRegister(1);
if (phase < 0)
break;
// finish registration whenever parent registration
// succeeded, even when racing with termination,
// since these are part of the same "transaction".
while (!UNSAFE.compareAndSwapLong
(this, stateOffset, s,
((long)phase << PHASE_SHIFT) | adjust)) {
s = state;
phase = (int)(root.state >>> PHASE_SHIFT);
// assert (int)s == EMPTY;
}
break;
}
}
}
}
return phase;
}
// 等待onAdvance()方法执行完毕
// 原理是先自旋一定次数,如果进入下一个阶段,这个方法直接就返回了,
// 如果自旋一定次数后还没有进入下一个阶段,则当前线程入队列,等待onAdvance()执行完毕唤醒
private int internalAwaitAdvance(int phase, QNode node) {
// 保证队列为空
releaseWaiters(phase-1); // ensure old queue clean
boolean queued = false; // true when node is enqueued
int lastUnarrived = 0; // to increase spins upon change
// 自旋的次数
int spins = SPINS_PER_ARRIVAL;
long s;
int p;
// 检查当前阶段是否变化,如果变化了说明进入下一个阶段了,这时候就没有必要自旋了
while ((p = (int)((s = state) >>> PHASE_SHIFT)) == phase) {
// 如果node为空,注册的时候传入的为空
if (node == null) { // spinning in noninterruptible mode
// 未完成的参与者数量
int unarrived = (int)s & UNARRIVED_MASK;
// unarrived有变化,增加自旋次数
if (unarrived != lastUnarrived &&
(lastUnarrived = unarrived) < NCPU)
spins += SPINS_PER_ARRIVAL;
boolean interrupted = Thread.interrupted();
// 自旋次数完了,则新建一个节点
if (interrupted || --spins < 0) { // need node to record intr
node = new QNode(this, phase, false, false, 0L);
node.wasInterrupted = interrupted;
}
}
else if (node.isReleasable()) // done or aborted
break;
else if (!queued) { // push onto queue
// 节点入队列
AtomicReference<QNode> head = (phase & 1) == 0 ? evenQ : oddQ;
QNode q = node.next = head.get();
if ((q == null || q.phase == phase) &&
(int)(state >>> PHASE_SHIFT) == phase) // avoid stale enq
queued = head.compareAndSet(q, node);
}
else {
try {
// 当前线程进入阻塞状态,跟调用LockSupport.park()一样,等待被唤醒
ForkJoinPool.managedBlock(node);
} catch (InterruptedException ie) {
node.wasInterrupted = true;
}
}
}
// 到这里说明节点所在线程已经被唤醒了
if (node != null) {
// 置空节点中的线程
if (node.thread != null)
node.thread = null; // avoid need for unpark()
if (node.wasInterrupted && !node.interruptible)
Thread.currentThread().interrupt();
if (p == phase && (p = (int)(state >>> PHASE_SHIFT)) == phase)
return abortWait(phase); // possibly clean up on abort
}
// 唤醒当前阶段阻塞着的线程
releaseWaiters(phase);
return p;
}Increase a participant's overall logic:
(1) add a participant, and the two parties need to increase the values unarrived, i.e. in state 16 and the lower 16 bits;
(2) If a participant is the first, then try to update the value of the state of the atom, if successful exit;
(3) If a participant is not the first, then check the implementation onAdvance (), if it is waiting for onAdvance () execution is not completed in, if otherwise try to update the value of the atomic state until a successful exit;
(4) Wait onAdvance () is completed using the first embodiment of the spin into the queuing waiting, reducing thread context switching;
arriveAndAwaitAdvance () method
The current phase of the current thread is finished, waiting for the other thread to complete the current stage.
If the current thread is the last to arrive at this stage, the current thread will execute onAdvance () method, and wake up other threads into the next phase.
public int arriveAndAwaitAdvance() {
// Specialization of doArrive+awaitAdvance eliminating some reads/paths
final Phaser root = this.root;
for (;;) {
// state的值
long s = (root == this) ? state : reconcileState();
// 当前阶段
int phase = (int)(s >>> PHASE_SHIFT);
if (phase < 0)
return phase;
// parties和unarrived的值
int counts = (int)s;
// unarrived的值(state的低16位)
int unarrived = (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK);
if (unarrived <= 0)
throw new IllegalStateException(badArrive(s));
// 修改state的值
if (UNSAFE.compareAndSwapLong(this, stateOffset, s,
s -= ONE_ARRIVAL)) {
// 如果不是最后一个到达的,则调用internalAwaitAdvance()方法自旋或进入队列等待
if (unarrived > 1)
// 这里是直接返回了,internalAwaitAdvance()方法的源码见register()方法解析
return root.internalAwaitAdvance(phase, null);
// 到这里说明是最后一个到达的参与者
if (root != this)
return parent.arriveAndAwaitAdvance();
// n只保留了state中parties的部分,也就是中16位
long n = s & PARTIES_MASK; // base of next state
// parties的值,即下一次需要到达的参与者数量
int nextUnarrived = (int)n >>> PARTIES_SHIFT;
// 执行onAdvance()方法,返回true表示下一阶段参与者数量为0了,也就是结束了
if (onAdvance(phase, nextUnarrived))
n |= TERMINATION_BIT;
else if (nextUnarrived == 0)
n |= EMPTY;
else
// n 加上unarrived的值
n |= nextUnarrived;
// 下一个阶段等待当前阶段加1
int nextPhase = (phase + 1) & MAX_PHASE;
// n 加上下一阶段的值
n |= (long)nextPhase << PHASE_SHIFT;
// 修改state的值为n
if (!UNSAFE.compareAndSwapLong(this, stateOffset, s, n))
return (int)(state >>> PHASE_SHIFT); // terminated
// 唤醒其它参与者并进入下一个阶段
releaseWaiters(phase);
// 返回下一阶段的值
return nextPhase;
}
}
}Logic arriveAndAwaitAdvance substantially as follows:
(1) modify the values of the state portion in unarrived minus 1;
(2) If it is not the last to arrive, then the call internalAwaitAdvance () method, or a spin waiting;
(3) If it is the last to arrive, then the call onAdvance () method, and then modify the value of the next phase value corresponding to the state, and wakes up the thread waiting for the other;
(4) returns the value of the next stage;
to sum up
(1) Phaser applicable to the scenario of the multi-stage multi-task, the task of each phase can be controlled finely;
Internal (2) Phaser queue using state variables and realize the whole logic of this article by the public [No. "Tong brother read the source" original, please support the original, thank you! ];
(3) state of the current phase of the high 32-bit storage phase, the number of participant 16 stores the current phase (task) of the parties, the lower 16 bits stores unfinished unarrived number of participants;
(4) selecting a queue based on a parity different from the current stage of queues;
(5) When a participant is not the last time arrives, the spin will enter queuing or wait for all participants to complete the task;
(6) When the last participant to complete the task, will wake up in the queue thread and move to the next stage;
Egg
Phaser CyclicBarrier and relative advantages of CountDownLatch?
A: There are two main advantages:
(1) Phaser complete multi-stage, and a control CyclicBarrier or CountDownLatch generally only one or two stages of the task;
(2) the number of tasks Phaser each phase can be controlled, and a number of tasks CountDownLatch CyclicBarrier or can not be modified once it is determined.
Recommended Reading
1, Sike java synchronization of the Opening Series
2, Sike Unsafe java class of analytic magic
3, Sike java synchronized series of JMM (Java Memory Model)
4, Sike java synchronized series of volatile resolve
5, Sike java synchronized series of synchronized resolve
6, Sike java series of synchronous write himself a lock Lock
7, Sike java synchronized series of articles from the AQS
8, Sike ReentrantLock resolve java source code synchronized series of (a) - fair locks, lock unfair
9, Sike ReentrantLock resolve java source code synchronized series of (two) - Conditions Lock
10, Sike java synchronized series of ReentrantLock VS synchronized
11, Sike ReentrantReadWriteLock parse java source synchronous series
12, Sike Semaphore synchronization java source parsing Series
13, Sike java source parsing synchronous series CountDownLatch
14, Sike java synchronized series of AQS final chapter
15, Sike StampedLock parse java source synchronous series
16, Sike java source synchronous series CyclicBarrier resolve
[This article from the "Tong brother read the source" original, please support the original, thank you! ]