0x00 Summary
Kafka in the previous version 0.8, does not provide High Availablity mechanism, once one or more Broker is down, it all goes down during the Partition can not continue to provide services. If the Broker can never be recovered, or that a disk fails, its data will be lost. One of the design goals of Kafka and that is to provide data persistence, and for distributed systems, especially when the cluster size up to a certain extent, a possibility of multiple machines or downtime greatly improved mechanisms for Failover demand is very high. Therefore, Kafka began to provide from 0.8 High Availability mechanisms. This article from both Leader Election Data Replication and HA introduced the mechanism of Kafka.
Why 0x01 Kafka needs High Available
1.1 Why do you need Replication
In Kafka 0.8 in the previous version, there is no Replication, once one Broker is down, then the data on all the Partition can not be consumed, which Kafka data persistence and Delivery Guarantee design goals contrary. Producer same time can not then these data are stored in the Partition.
- If the synchronous mode is the Producer Producer will attempt to re-transmit
message.send.max.retries(default is 3) after the time throws Exception, the user can choose to stop sending the subsequent data transmission can also choose to continue to choose. The former will cause obstruction data, which can cause loss of data should be sent to the Broker. - If the Producer using asynchronous mode, the Producer will attempt to re-send
message.send.max.retries(the default is 3) after the second log the exception and continues to send follow-up data, which can result in loss of data and the user can find the problem through the log.
Thus, in the absence of Replication circumstances, once a machine is down or stop a Broker work will result in reduced availability of the entire system. With the increase of the probability of cluster size, the type of abnormality that appears throughout the cluster greatly increased, so the introduction of Replication mechanism is very important for production systems.
1.2 Why the need Leader Election
(Described herein mainly refers to Leader Election Replica between Leader Election)
after introducing Replication, the same may have a plurality of Replica Partition, and then need to select one of these Replica the Leader, Producer and Consumer only interact with the Leader other Replica Follower as copying data from the Leader.
Because of the need to ensure data consistency between multiple Replica of the same Partition (down one after the other Replica you must be able to continue to serve and that is not cause duplication of data can not cause data loss). Without a Leader, while all Replica can read / write data, it would need to ensure that each (N × N pieces of lane) synchronization data, ordering data consistency and is very difficult to ensure between a plurality Replica, greatly increased Replication complexity of implementation, but also increase the chance of exception. After the introduction of the Leader, Leader only for data reading and writing, only Follower Fetch data (N pathways) Leader sequence to the system more simple and efficient.
0x02 Kafka HA Design Analysis
2.1 How will all Replica evenly distributed throughout the cluster
In order to better load balancing, Kafka try all the Partition evenly distributed throughout the cluster. A typical number of deployment is greater than a Topic Partition Broker. Meanwhile, in order to improve the fault tolerance of Kafka, with a need to try to spread Replica Partition of different machines. In fact, if all the Replica are on the same Broker, the Broker that once down, all the Replica of the Partition are unable to work, we will achieve the effect of HA. Meanwhile, if a Broker is down, you need to keep it above the load can be evenly distributed to all other Broker surviving.
Replica of Kafka allocation algorithm is as follows:
- All Broker (assuming a total of n Broker) to be dispensed and sorting Partition
- Partition the i-th assigned to the first (i mod n) th Broker
- Partition the i-th j-th Replica assigned to the first ((i + j) mod n) on a Broker
2.2 Data Replication
Kafka's Data Replication need to address the following issues:
- How to Propagate the message
- Producer ACK before sending to the need to ensure that the number of Replica has received the message
- How to deal with a situation Replica not working
- How to deal with the situation back Failed Replica recovery
2.3 Propagate message
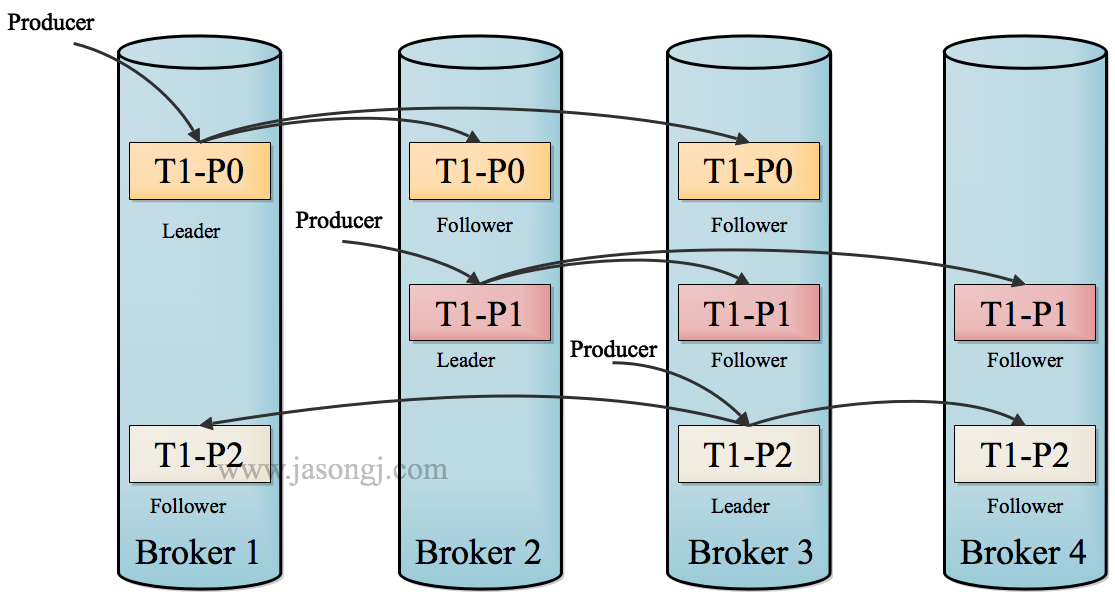
Producer when you publish a message to a Partition, first (available through Broker and Cache in the Producer) Metadata found by Leader of the Partition, then regardless of the Topic of Replication Factor is how much (that is, the number of the Partition Replica), Producer only sends the message to the Partition of Leader. Leader writes the message to its local Log. All data from each Follower Leader pull. On this way, data is sequentially stored Follower consistent with Leader. Follower after receiving the message and writes it Log, transmits ACK to the Leader. Replica Leader Once received all the ACK in the ISR, the message is considered to have a commit, and Leader will increase HW sends an ACK to Producer.
To improve performance, each Leader Follower immediately sends an ACK to the data as it is received, rather than wait until the data is written in the Log. Thus, for already commit message, Kafka can only ensure that it is stored in multiple Replica of memory, but can not guarantee that they are persisted to disk, it can not guarantee this massage after an exception must be Consumer consumption . But considering this scenario is very rare, can be considered in this way in terms of performance and data persistence on to do a better balance. In future releases, Kafka will consider providing greater durability.
Consumer read message is read from the Leader, only the over-commit message (offset below HW message) will be exposed to the Consumer.
Kafka Replication data flow as shown in FIG.
2.4 ACK before the need to ensure that the number of backup
Most distributed systems and, like, Kafka treatment failure must be clearly defined whether a Broker "alive." For Kafka, Kafka survival contains two conditions, first, it must maintain a session with Zookeeper (this is achieved by the Heartbeat mechanism Zookeeper). Second Follower must be able to copy the Leader of timely news to come, can not "far behind."
Leader keeps track of its list maintained Replica synchronization, the list is called ISR (ie in-sync Replica). If a Follower down, or too much behind, Leader will remove it from the ISR. "Far behind" described herein means exceeds a predetermined value the number of message duplicated Follower Leader behind after (this value can be obtained by $ KAFKA_HOME / config / server.properties the replica.lag.max.messagesconfiguration, the default value is 4000) or exceeds Follower predetermined time (this value may be $ KAFKA_HOME / config / server.properties by replica.lag.time.max.msconfigured, the default value is 10000) fetch request is not sent to the Leader. .
Kafka replication mechanism is neither fully synchronous replication, asynchronous replication is not simple. In fact, synchronous replication requires all Follower work are copied, the message will be considered commit, this replication greatly affect the throughput (high throughput is a very important characteristic of Kafka). The asynchronous replication, asynchronous replication from Leader Follower data, as long as the data is written to the log Leader is considered to have commit, in this case if the Follower are copied are behind Leader, but if the Leader suddenly goes down, it will data loss. This use of ISR and Kafka are well-balanced way of ensuring that data is not lost and throughput. Follower can bulk copy data from the Leader, this greatly improves replication performance (batch write to disk), greatly reducing the gap between the Follower and Leader.
It should be noted, Kafka addressed only fail / recover, does not deal with "Byzantine" ( "Byzantine") problem. A message is only ISR in all Leader Follower are copied from the past will be deemed to have been submitted. This avoids some of the data to be written into the Leader, Follower have not had time to be copied on any downtime, and data loss caused by (Consumer unable to consume these data). For the Producer is concerned, it can choose whether to wait for news commit, which can request.required.acksbe set. This mechanism ensures that the ISR as long as there is one or more of the Follower, is a commit message will not be lost.
2.5 Leader Election Algorithm
Above shows how Kafka Replication is done, and the other is a very important issue when Leader is down, how to elect a new Leader in the Follower. Because Follower may be behind many or crash, so be sure to select the "latest" the Follower as the new Leader. A basic principle is that if the Leader is gone, the new Leader must have all the original Leader commit messages before. This need to make a compromise, if the Leader Follower wait for more confirmation before a message is marked commit, that there is more Follower can be used as the new Leader, but it can also cause decreased throughput after it goes down .
Leader Election a very common way is to "Majority Vote" ( "majority"), but Kafka was not this way. In this mode, if we have 2f + 1 Ge Replica (included Leader and Follower), it must ensure that prior to commit f + 1 Ge Replica complete replication messages, in order to ensure the right to elect a new Leader, fail not exceed the Replica f a. Because the rest of the arbitrary f + 1 Ge Replica, there is at least a Replica contains all the latest news. This approach has a great advantage, latency system depends only on the fastest of several Broker, not the slowest one. Majority Vote also has some disadvantages, in order to ensure normal Leader Election, the number of follower fail it can tolerate less. If you want to hang tolerate a follower, there must be three or more Replica, if you want to hang tolerated 2 Follower, there must be five or more Replica. In other words, in a production environment in order to ensure a high degree of fault tolerance, there must be a large number of Replica, and a large number of Replica will lead to a sharp decline in the performance of a large amount of data. This is the algorithm used in more ZookeeperThis sharing system configuration in a cluster rarely need to store large amounts of data cause of system used. The HA Feature e.g. HDFS based Majority vote-TECHNOLOGY-based , but it does not use the data stored in this way.
In fact, Leader Election algorithm is very large, such as the Zookeeper Zab , Raft and Viewstamped Replication . The Leader Election algorithm Kafka used more like Microsoft's PacificA algorithm.
Kafka in Zookeeper dynamically maintains a ISR (in-sync replicas), the ISR in all Replica have to keep up with the leader, only members of the ISR have been selected as Leader of the possible. In this mode, one for Replica f + 1, a Partition can ensure the f Replica failure tolerance without loss has commit message premise. In most usage scenarios, this model is very favorable. In fact, in order to tolerate the failure of the f Replica, Replica Majority Vote and the number of ISR prior to commit to wait is the same, but the total number of Replica of ISR needs of almost half of Majority Vote.
2.6 How to deal with all the Replica do not work
Mentioned above, when there is at least one follower in the ISR, Kafka already commit to ensure that data is not lost, but if all Replica of a Partition are down, and you can not guarantee that the data is not lost. There are two possible options in this case:
- Waiting for ISR according to any one Replica "live" over, and it is selected as a Leader
- Select the first "live" over the Replica (not necessarily in the ISR) as a Leader
This need to make a simple trade-off in usability and consistency of them. If you must wait for the ISR Replica "live" over time that is not available may be relatively long. And if all of Replica ISR can not "live" over, or the data is lost, the Partition will never be available. Select the first "live" over the Replica as Leader, and this is not the ISR Replica Replica, even though it does not guarantee that already contains all the commit messages, it will be the Leader as consumer data source (previously there are instructions to complete all read and write by the Leader). Kafka0.8. * Use the second way. According to Kafka's documents, in future releases, Kafka support the user to select one of these two ways to configure, to select high availability or strong consistency according to different usage scenarios.
2.7 How elections Leader
The simplest and most intuitive program, all Follower are set on a Watch Zookeeper, once Leader downtime, the corresponding ephemeral znode automatically deleted, then all Follower are attempting to create the node, create winners (Zookeeper ensure that only to create a success) that is the new Leader, other Replica is the Follower.
However, this method will have three questions:
- This is a split-brain caused by the characteristics of Zookeeper, although Zookeeper ensure that all Watch in order to trigger, but it does not guarantee the same time all Replica "see" the state is the same, which may result in a different response Replica is inconsistent
- If the Partition herd effect on the Broker is down more, will result in more Watch is triggered, causing a lot of adjustments in the cluster
- Zookeeper overloaded Each Replica must be registered for this purpose on a Watch Zookeeper, when the cluster size increased to several thousand Partition Zookeeper load will be too heavy.
Kafka 0.8. * The Leader Election solution to the above problem, it elected a controller in all the broker, Leader election Partition of all decisions by the controller. Leader controller will change directly through the RPC method (more efficient manner than Zookeeper Queue) Broker to notify the need for this response. While the controller is also responsible for additions and deletions as well as Replica of reallocating Topic.
2.8 HA structure related Zookeeper
(The Zookeeper structure shown in this section, a solid frame represents the path name is fixed, and the dotted line frame represents the path name associated with the service)
ADMIN (znode will only exist when the directory-related operations, the operation will end deleted)
/admin/preferred_replica_electiondata structure
Schema: { "fields":[ { "name":"version", "type":"int", "doc":"version id" }, { "name":"partitions", "type":{ "type":"array", "items":{ "fields":[ { "name":"topic", "type":"string", "doc":"topic of the partition for which preferred replica election should be triggered" }, { "name":"partition", "type":"int", "doc":"the partition for which preferred replica election should be triggered" } ], } "doc":"an array of partitions for which preferred replica election should be triggered" } } ] } Example: { "version": 1, "partitions": [ { "topic": "topic1", "partition": 8 }, { "topic": "topic2", "partition": 16 } ] }
/admin/reassign_partitionsPartition for dispensing to a number of different set broker. Partition for each to be reallocated, Kafka stores all its Replica Broker id and corresponding on the znode. The znode created by the management process and once again it will be automatically assigned successfully removed. Data structure follows
Schema: { "fields":[ { "name":"version", "type":"int", "doc":"version id" }, { "name":"partitions", "type":{ "type":"array", "items":{ "fields":[ { "name":"topic", "type":"string", "doc":"topic of the partition to be reassigned" }, { "name":"partition", "type":"int", "doc":"the partition to be reassigned" }, { "name":"replicas", "type":"array", "items":"int", "doc":"a list of replica ids" } ], } "doc":"an array of partitions to be reassigned to new replicas" } } ] } Example: { "version": 1, "partitions": [ { "topic": "topic3", "partition": 1, "replicas": [1, 2, 3] } ] }
/admin/delete_topicsdata structure
Schema: { "fields": [ {"name": "version", "type": "int", "doc": "version id"}, {"name": "topics", "type": { "type": "array", "items": "string", "doc": "an array of topics to be deleted"} } ] } Example: { "version": 1, "topics": ["topic4", "topic5"] }
brokers

broker (ie /brokers/ids/[brokerId]) memory "alive" Broker information. Data is structured as follows
Schema: { "fields": [ {"name": "version", "type": "int", "doc": "version id"}, {"name": "host", "type": "string", "doc": "ip address or host name of the broker"}, {"name": "port", "type": "int", "doc": "port of the broker"}, {"name": "jmx_port", "type": "int", "doc": "port for jmx"} ] } Example: { "jmx_port":-1, "host":"node1", "version":1, "port":9092 }
topic registration information ( /brokers/topics/[topic]), Broker id all Replica store all the Topic Partition is located, is the first Replica Preferred Replica, for a given Partition, it is on the same Broker at most one Replica, therefore Broker id as Replica id. Data is structured as follows
Schema: { "fields" : [ {"name": "version", "type": "int", "doc": "version id"}, {"name": "partitions", "type": {"type": "map", "values": {"type": "array", "items": "int", "doc": "a list of replica ids"}, "doc": "a map from partition id to replica list"}, } ] } Example: { "version":1, "partitions": {"12":[6], "8":[2], "4":[6], "11":[5], "9":[3], "5":[7], "10":[4], "6":[8], "1":[3], "0":[2], "2":[4], "7":[1], "3":[5]} }
State Partition /brokers/topics/[topic]/partitions/[partitionId]/state( ) is structured as follows
Schema: { "fields": [ {"name": "version", "type": "int", "doc": "version id"}, {"name": "isr", "type": {"type": "array", "items": "int", "doc": "an array of the id of replicas in isr"} }, {"name": "leader", "type": "int", "doc": "id of the leader replica"}, {"name": "controller_epoch", "type": "int", "doc": "epoch of the controller that last updated the leader and isr info"}, {"name": "leader_epoch", "type": "int", "doc": "epoch of the leader"} ] } Example: { "controller_epoch":29, "leader":2, "version":1, "leader_epoch":48, "isr":[2] }
/controller -> int (broker id of the controller)The current controller of the information storage
Schema: { "fields": [ {"name": "version", "type": "int", "doc": "version id"}, {"name": "brokerid", "type": "int", "doc": "broker id of the controller"} ] } Example: { "version":1, "brokerid":8 }
/controller_epoch -> int (epoch)Directly stored in the integer controller epoch, not like other znode stored as a string in JSON.
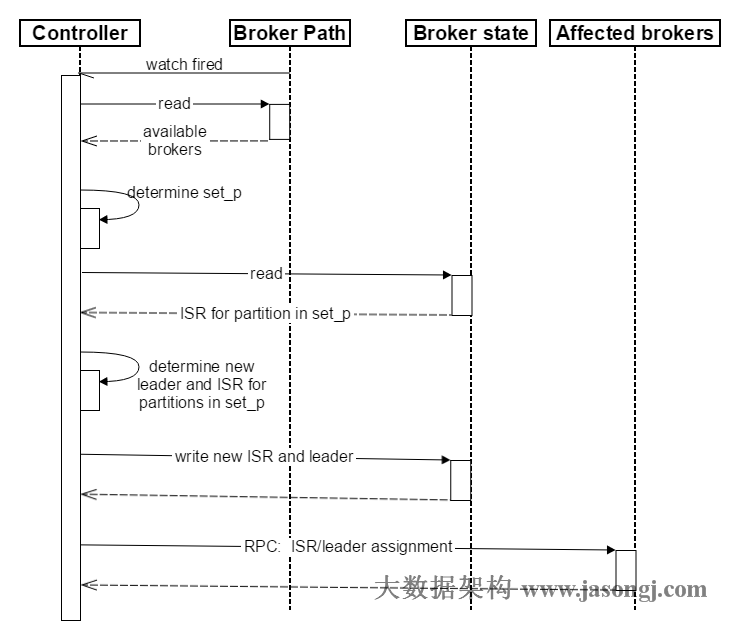
2.9 broker failover process Introduction
- Controller register Zookeeper Watch, once Broker downtime (which is used to represent any downtime to the system that it die scenarios, including but not limited to power off the machine, the network is unavailable, GC lead to Stop The World, a process crash, etc.) , which corresponds to the Zookeeper znode will automatically be deleted, Zookeeper will fire Controller registered watch, Controller reads the latest surviving Broker
- All Partition on all Broker Controller decisions set_p, the set including downtime
- For set_p each Partition
3.1 from a/brokers/topics/[topic]/partitions/[partition]/statereading of the Partition current ISR
to determine the new Leader of the Partition 3.2. If the current ISR at least a Replica also survived, then select one of them as the new Leader, a new current ISR ISR contains all surviving Replica. Otherwise, select the Partition of any one surviving Replica (there may be potential data loss under this scenario) as a new Leader and ISR. If all Replica of the Partition are down, the new Leader will be set to -1.
3.3 The New Leader, ISR and newleader_epochandcontroller_epochwrite/brokers/topics/[topic]/partitions/[partition]/state. Note that this operation will be performed only if no change in the course of its version 3.1 to 3.3, otherwise jump to 3.1 - RPC commands sent directly LeaderAndISRRequest to set_p relevant Broker. Controller commands can be transmitted in a plurality of RPC operations to improve efficiency.
Broker failover sequence shown as FIG.
0x03 reprint