# -*- coding:utf-8 -*- """ author:Mr Yang data:2019/09/26 """ import itchat import matplotlib.pyplot as plt import matplotlib import os import re import numpy as np from PIL import Image from wordcloud.wordcloud import WordCloud class WeiXinAnalyze(): def __init__(self): self.sex_dict = {} self.city_dict = {} self.self_nickname = '' self.wordList = [] self.save_path = ' Result ' DEF wx_login (Self): "" " micro-channel data and statistics log " "" itchat.login () Data = itchat.get_friends (Update = True) self.self_nickname = Data [ 0 ] [ ' the nickName ' ] # obtain micro channel nickname for Item in Data: sex = Item. GET ( ' sex ' ) # sex Province = Item. GET('Province') # 省份 city = item.get('City') # 城市 if sex or sex == 0: if sex not in self.sex_dict: self.sex_dict[sex] = 1 else: self.sex_dict[sex] += 1 if province and city: address = '-'.join([province, city]) if address not in self.city_dict: self.city_dict[address] = 1 else: self.city_dict[address] += 1 if item["Signature"]: signature = re.sub(r'<span.*</span>', '', item["Signature"]).strip().replace('\n', '') self.wordList.append(signature) if not os.path.exists(self.save_path): os.mkdir (self.save_path) DEF get_sex_info (Self): "" " Gender Method " "" sex_dict = {} sex_dict [ ' M ' ], sex_dict [ ' F ' ], sex_dict [ ' other ' ] = Self. sex_dict.pop ( . 1 ), self.sex_dict.pop ( 2 ), self.sex_dict.pop ( 0 ) # data preparation data = sex_dict.items () Labels = [I [ 0 ] for I in data] the nums = [I [ . 1 ] for I in data] # draw a pie chart using Matplotlib matplotlib.rcParams [ ' font.sans serif- ' ] = [ ' SimHei ' ] # Kanji font type (here in bold) specified plt.title ( ' micro-channel buddy gender statistics ({}) ' .format (self.self_nickname)) plt.pie (X = the nums, = Labels Labels, autopct = ' % 1.2f %% ' ) plt.savefig (the os.path.join (Self .save_path, ' wx_sex_data.png ' )) DEF get_address_info (Self): "" " analysis method address " "" data = self.city_dict.items() sort_data = sorted(data, key=lambda i: i[1], reverse=True)[:20] x = [i[0] for i in sort_data] y = [i[1] for i in sort_data] matplotlib.rcParams['font.sans-serif'] = ['SimHei'] fig, ax = plt.subplots() rects = ax.barh(x, y, color='greenyellow', align="center") Ax.set_yticks (X) Set scale position # ax.set_yticklabels (x) # ordinate set the property values for each scale ax.invert_yaxis () # inverted scale value ax.set_xlabel ( ' number (bits) ' ) # set abscissa unit ax.set_title ( ' micro letter friends city statistics ({}) ' .format (self.self_nickname)) # set title picture for RECT, the y-, NUM in ZIP (rects, the X-, Y): X = rect.get_width () plt.text (X + 0.05 , Y, " % D " % int (NUM)) plt.savefig (the os.path.join (self.save_path,' Wx_address_data.png ' )) DEF wx_ciyun (Self): "" " Micro-letter word cloud Method " "" text = " " .join (self.wordList) # Get the current file execution path src_dir = The os.getcwd () # generated word cloud shape picture address imagePath = os.path.join (src_dir, " timg.jpg " ) # generate a word cloud font address (to prevent Chinese garbled) font = os.path.join (src_dir, " simhei.ttf " ) # address generating word cloud resultPath = the os.path.join (self.save_path, 'wx_ciyun.png' ) # Starts to generate image BG = np.array (Image.open (the imagePath)) WC = wordcloud ( MODE = ' the RGBA ' , # a transparent background mask = BG, # shape covering BACKGROUND_COLOR = " White " , the background color # max_font_size = 80 , the maximum font # MIN_FONT_SIZE = 10 , minimum font # MAX_WORDS = 5000 , the maximum number of words in the displayed word cloud # random_state = 100 , # provided how many random generation state, i.e., how many color schemes font_path = font, font set # ) .generate (text) wc.to_file (resultPath) IF the __name__ == ' __main__ ' : Weixin = WeiXinAnalyze () Weixin .wx_login () weixin.get_sex_info () weixin.get_address_info () weixin.wx_ciyun ()
Finally, look at the results:

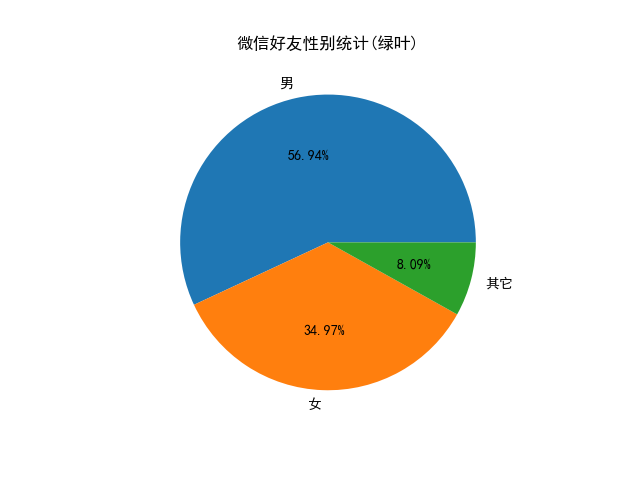

Tired, first contact data analysis.